
The Japanese X-ray telescope Hitomi has been declared lost after it disintegrated in orbit, torn apart when spinning out of control. The cause is still under investigation but early analysis points to bad data in a software package pushed shortly after an instrument probe was extended from the rear of the satellite. JAXA, the Japanese space agency, lost $286 million, three years of planned observations, and a possible additional 10 years of science research.
Hitomi, also known as ASTRO-H, successfully launched on February 17, 2016 but on March 26th catastrophe struck, leaving only pieces floating in space. JAXA, desperately worked to recover the satellite not knowing the extent of the failure. On April 28th they discontinued their efforts and are now working to determine the reasons for the failure, although a few weeks ago they did provide an analysis of the failure sequence at a press conference.
 On March 26th, the satellite completed a maneuver to point at the galaxy Markarian 205. The Attitude Control System (ACS) began using the Star Tracking (STT) system data to control the position of the satellite. The STT at this point should have updated another position monitoring system, the Inertial Reference Unit (IRU). This may not have occurred.
On March 26th, the satellite completed a maneuver to point at the galaxy Markarian 205. The Attitude Control System (ACS) began using the Star Tracking (STT) system data to control the position of the satellite. The STT at this point should have updated another position monitoring system, the Inertial Reference Unit (IRU). This may not have occurred.
At the time, the satellite was passing the South Atlantic Anomaly. This is important for two reasons. First, it placed Hitomi in a communications blackout region which meant there was no active ground monitoring of the situation (human intervention might have prevented the catastrophic failure). Second, the belts of radiation encircling the Earth dip low in this region so particle density is higher than in other parts of the orbit. High energy particles may have disrupted the onboard electronics.
The STT and IRU disagreed on the attitude of the satellite. In this case the IRU takes priority, but its data apparently was wrong, reporting a rotation rate of 20 degrees per hour, which was not occurring. The satellite attempted to stop this erroneous rotation using reaction wheels. The satellite configuration information uploaded earlier was wrong and the reaction wheels made the spin worse.
The satellite now went into “Safe Hold” mode and thrusters were called upon to stop the rotation. Using the same erroneous configuration information they increased the spin further causing the satellite’s rotation to exceed design parameters. Parts, like the solar sails, came off. In all, at least 5 pieces were observed in addition to the main body. Some reports indicate there may be as many as 10 pieces with 2 larger and 8 smaller pieces continuing in orbit. It’s likely that all ten pieces separated originally but their close proximity prevented visual and radar images from seeing them as separate entities.
In satellites, the STT typically gets a good fix and sends the data to the IRU. The IRU uses the data to set its current reading and to measure how far it drifted since the last update. After calculating the drift it uses drift adjustments to compensate for the future drift. Clearly if the compensation calculation is wrong the future readings are going to be wrong. This appears to have played a role since the ACS attempted to correct a rotation that didn’t exist. The erroneous configuration information led the ACS to aggravate, not correct, the rotation.
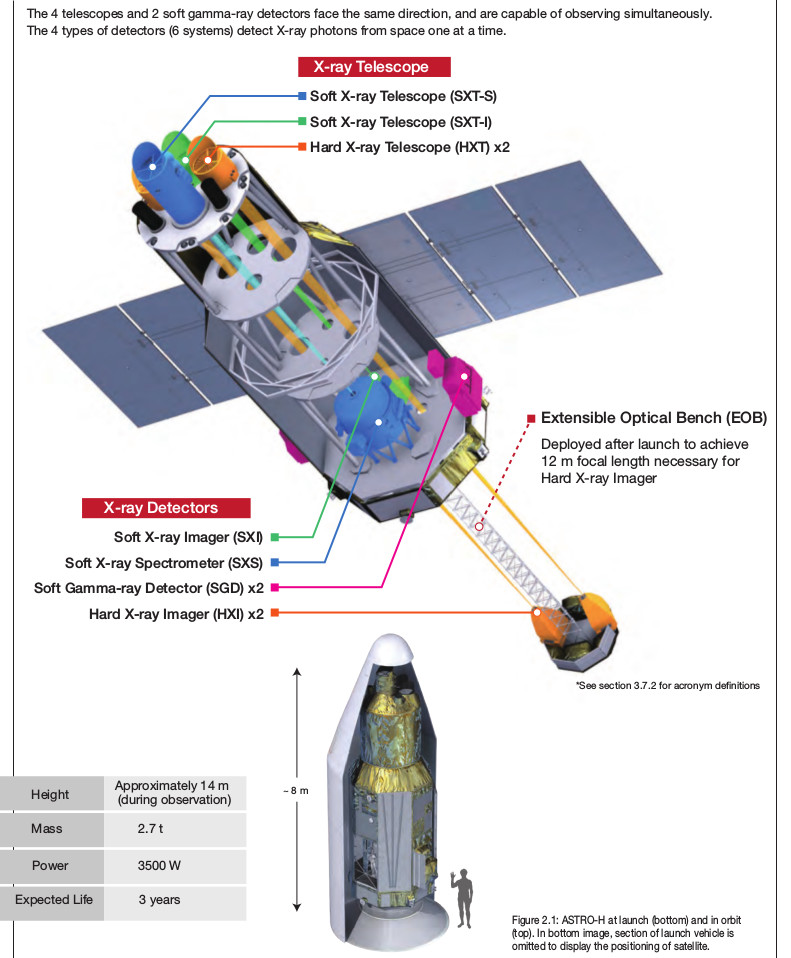
The hardware was built to study hard X-ray sources in the Universe. X-ray satellites like the Hitomi are not hindered by dust clouds that obscure visual instruments. Previous satellites have greatly expanded our knowledge of the Universe, with Japan as the leader in the technology.
Japan’s first successful X-ray satellite, Hakucho, was launched in 1979. Other successful launches followed in ’83, ’87, and ’93. Launches in ’76 and 2000 failed. Their most recent X-ray satellite, Suzaka, launched in 2005, was just decommissioned in 2015 due to deterioration of batteries and other components. It was hoped that Hitomi would see similar utility but that hope has now been extinguished.
[Images from JAXA web site and reports.]















Heads up: “Attitude Control System (ACS)”
That’s the right word. Attitude. It means orientation in space.
“Incorrecting” is also a word now.
Ha! You just got Benchoffed!
word!
*Studio audience laughs*
ahaha owned!
bet it was that Windows 10 auto upgrade!
+1
I’ve had no problems with Win 10, but I can’t NOT acknowledge its issues. Any software with a failure state consisting of an aborted install and a dialog that literally just says “Something happened” is a goddamn abomination.
What about the Blue Screen of Death, that just says ” :( Your PC ran into a problem and needs to restart. We’re just collecting some error info, and then we’ll restart for you “
A BSoD with nothing else but a gray box and a blinking cursor.
IIRC, I was using 98 at the time and I was trying to hook into the desktop memory space when I ran into this annoying as hell bug. No message. No error. No memory dump. Nothing but a BSoD with a gray box and a blinking cursor. I banged my head on the problem for months. Getting it working sometimes but getting the useless BSoD again a week or so later.
I dropped the entire project when MS released the next OS. ME I think and I discovered the desktop memory space I was 0oking around in had moved into a privileged memory space. I just lost the heart to keep at it and moved on to other projects.
+1
Where is the like function.
The Akagi, Kaga, Sōryū, Hiryū, Shōkaku, and Zuikaku are steaming to Redmond as we speak.
They never use latest technology in space projects as it is always considered unproven. Maybe they used Windows 7 and forgot to disable Get Windows 10 update…
As an aerospace engineer it’s always somewhat mind blowing to me when something like this occurs. Satellite software updates are always tested on hardware in the loop sims/engineering models before they’re transmitted for this exact reason. Aside from hardware troubleshooting, this is the other reason we go to the trouble of building and maintaining these ground based mockups. I’ll admit that I don’t know what the engineering culture is at JAXA, and we certainly have made similar mistakes over here (Mars Climate Orbiter) but this sort of thing is almost always the result of gross negligence on the part of someone, and heads should roll.
By the time software hits the vehicle, every major function should have been thoroughly tested and verified. I mean it sounds like someone sprinkled a minus sign or two in where it ought not to have been and it’s hard to fathom how something like this would go unnoticed if there was any testing done at all… which indicates to me they just did inadequate testing i.e. the rocket science equivalent of “oh look, it boots, we’re good.”
When good engineering practices are adhered to, this sort of thing just does not happen.
What about the “we push one upgrade out, but forgot the dependency” or the “buffer overflow”? That one is really a pesky one to find. And yes, as a software engineer I know what you mean by “thorough testing”. Many times its an “it works” situation and then they forget to think about testing the exceptions. The regression test worked, so the rest works too… Except they forget that the “rest” means: “all the stuff that the software depends on”. That might also be the cause, human error because someone tested it with the wrong version of the software.
Dude, this was a satellite not some junky Android or generic Linux bod were the consequences of writing bad code are non-existent. They are much more serious and thorough(at least here in the U.S.) about testing and validation, etc.
Ooops…
https://en.m.wikipedia.org/wiki/Mars_Climate_Orbiter
That’s quite different.
The software had no known bugs at least no part of the software did anything unexpected.
If every component of the mission had used same units of measurement nothing would have happened.
That’s what happens when you stick to troglodytic practices, like driving on left, weight in stones, pounds, lbs and ounces, volume in american or british gallons, length miles, nautical miles, feet, inches, speed in knots, surface in acres, square miles, ecc. ecc.
Cheers.
@Felice Masi “like driving on the left” <- you mean like 67% of the world does? No argument about the others, but that one unfortunately isn't such a "trogladytic" practice
They drive on the right in china.
Yet is seems like a not exactly uncommon killer for too many high profile missions.
It sounds like the software was fine but the data was incorrect. Perhaps a missing or extra minus sign on a thrust vector specification.
But really should that destroy $286 million satellite? My car has a limp mode in software! If a sensor like the oxygen sensor gives erroneous reading then the software just ignores it and uses a table that it maintained when the sensor was ok.
Your car will not go into limp mode if the sensor is defective while it’s not giving erroneous readings. Your engine might still start knocking. And half an hour down the road, there’ll be a hole in one of the pistons.
I beg to differ.
Most modern ECU’s are quite able to detect and “fail safe” with most fully failed or intermittently failing sensors. Even my old Toyota pickup can deal with failing sensors in a graceful, albeit fuel-wasting manner.
+1 for old Toyota pickup, I had an issue with my O2 sensor as well. It was an 87. Before they updated the EFI system (I believe it was model year 89 they did that) the sensors grounded through the exhaust manifold. Bad design. I ran a separate ground from the plates where the sensor mounted to a random spot on the body.
When my Suzuki Sidekick developed a defective fuel injector, the ECU responded (probably based on the O2 sensor)
by highly enriching the A/F mixture. MPG dropped from 28 to 12. Once when it was idling in such a state, I lit a cigarette lighter about a foot (3 decimeters) from the exhaust outlet. An impressive flame about 6 inches wide developed at the lighter and extended about 2 and a half feet (something less than a meter) beyond! I stopped because the hair on my fingers got singed.
We’ve built how many x-million cars and how many y-thousand satellites? It took time and lots of failure to build that ECU.
This WAS a limp mode. The problem was that one part of an emergency system wasn’t tested right. This is one of the more common “subtle errors” in programming: who hasn’t made the mistake of not checking that error handling works properly?
Spacecraft can’t “limp” like cars can. They have to orient themselves and control their spin so they can communicate with Earth. A car’s limp mode relies on the fact that engines don’t really need intelligence to run. Spacecraft do.
Well looking at this from a “what will fix this” point of view rather than “who can we blame” type point of view – I expect that software is the simplest solution.
Coding practices should change and possibilities for positive feedback should be identified and coded for protectively.
When you look at – the problem was “too much angular velocity” and the corrective action was to “add force” so the opportunity for a positive feedback loop is rather obvious.
A better response would be to test adding force and if it that failed to be “corrective” then to require human intervention.
You could even write an application that runs shortly after compile time (on the ground) that checks for this sort of “uncaught” event just like we have Design Rule Checking (DRC) in PCB software.
The problem is, for ‘require human intervention’ to work, the spacecraft must be in a stable, power positive attitude, with good comms. That’s what it was trying to get to. This is the equivalent of an unexpected fault during a fault handling routine. You have to carefully engineer a spacecraft to make sure it doesn’t get into this kind of state. If the IRU is this critical to spacecraft health, then you make damn sure it isn’t going to get into a failed state. You have more than one. From different manufacturers. Running different code. Or better yet, a couple of photodetectors that tell when the Sun or Earth is going by. Simple. Reliable. Proven.
You can’t require human intervention. There are no humans. Talking to people requires power and orientation, which is what it was trying to get.
If it can’t get those, it’s just as dead as if it had fallen apart.
Well it wouldn’t have gotten to that point anyway if there were practices to identify positive feedback loops.
And answer these questions –
Is a unresponsive satellite any worse than one that has town itself apart?
No risk management solves every problem so should we completely give up on risk management?
“Well it wouldn’t have gotten to that point anyway if there were practices to identify positive feedback loops.”
Yes, it would’ve! It got to safe mode because of completely unrelated failures – because the IRU/STT system couldn’t handle the STT going bonkers for a brief bit. That forced the spacecraft to enter safe mode, and its “safe mode” was broken.
There wasn’t a positive feedback loop. It was trying to orient itself, and the controls for orienting itself were totally wrong, causing it to tear itself apart. It’s a spacecraft, filled with lots of stuff that explodes in a controlled fashion. The fact that those controls tore the spacecraft apart isn’t surprising.
“Is a unresponsive satellite any worse than one that has town itself apart?”
An unresponsive satellite is *identical* to one that’s torn itself apart. They’re both useless. A satellite without power is never coming back. Safe mode for a satellite *has* to be “find the Sun, listen to Earth.” And to do that, you’ve got to have thrusters, so there’s always the possibility of “boom.”
The problem with Hitomi wasn’t some grand overall decision thing. The real thing to criticize is that they tried to take measurements after deploying the optical bench before checking the flight controls of the satellite fully.
Normally satellites need orientation to communicate, but can’t they use omnidirectional antennas for backup? No need for high bit rates when recovering.
Often, the low-rate antenna is indeed omnidirectional – but if the new software is faulty, a tumble can be induced by normal orientation actions (anything from use of reaction wheels through to thrusters). Then, attempts to correct the tumble can then make things worse, not better – for example, because a reaction wheel’s being driven the opposite direction from desired. In this situation, the satellite can catastrophically deconstruct before it’s possible to rectify by ordering the onboards to reset to previous version.
Hindsight. After the fact we are smarter (well, we *should* be: that’s what mistakes were made for).
> heads should roll.
That’s why I disagree with this sentiment (or with the “Seppuku” in the other thread). Assuming people are capable to learn from errors (and corporate culture can do *a lot* to foster — or to hinder that), those having made all sorts of errors are key people when it comes to avoid the next problem! Don’t kill them, on the contrary.
It’s what is called “experience”. Learn from it.
By all means don’t throw away hard-earned knowledge, but there comes a point where people with histories of high-cost fuckups need to be quarantined from the critical decision-making process.
http://assets.amuniversal.com/84ec4ee09fa6012f2fe600163e41dd5b
Or we can stop trying to identify the “better” people (regardless of that means having made more or less mistakes in the past), view testing as a way of identifying blatant mistakes, but require _proof_ by formal verification…
with all the money from failed satellite/rocket/plane/train accidents, we could have formalized a lot of physics and engineering into a metamath database…
I wonder if it’s such a good thing to have heads roll, when you don’t have ready replacements for those heads. It would probably set you back even more years, because the new heads need to learn the importance of testing, and the extents of it, as well. Probably better to keep the team together, to find the culprit but forego on the blame, to find out what made him do the wrong thing, and make appropriate changes to the system so that it will not happen again.
There’s a word for that thing: managing. That word literally means: to make the system work.
For instance, a clock will not continue to work when you remove a gear. And if you replace a gear, you need to spend a lot of time on making it perfect, or your clock will run worse than before. If you want to replace a gear and expect the same results as before, then you must make damn sure that you are good at making gears, and spend a lot of time at making it perfect before inserting it in the clock. And until that time, the clock is not running at all.
Paraphrasing an exchange IBM CEO Tom Watson had with a young executive that made a mistake that cost the company a couple million,
Exec: “I guess you want me to resign”
Watson: “Resign? I just spent 2 million dollars to train you!”
Or 286 million in this case. Either way, he’s not making that mistake twice.
You learn from failure. The magic is learning from failure with no consequences – simulation. The question that occurs to me is how this mistake was made even with simulation and high talent software engineers. It may be that this control architecture lacks robustness to error conditions or that the system needs a different implementation of validation and redundancy. There is much to learn from this for everyone.
It’s extraordinarily difficult to predict every failure mode in a system of even moderate complexity. Even if one unit giving erroneous readings was tested for, there is a wide variety of ways for those readings to be wrong. Hindsight is 20/20—most massive engineering failures have easy, sometimes trivial, fixes. Finding all of these in advance is impossible. Simulation is great, but will never be completely exhaustive.
“but this sort of thing is almost always the result of gross negligence on the part of someone, and heads should roll.”
Looking more into it, it looks more like a management issue. Apparently, they knew about failures in 2 out of the 3 orientation sensors on the spacecraft: the star tracker glitched occasionally through the SAA, and the Sun sensor wasn’t working after optical bench deployment. So why in the world was the spacecraft allowed to continue normally until they had fixed/safeguarded around those problems?
Essentially, they were running with a single point of failure (the IRU), and when it failed, everything went crazy. The incorrect thruster settings destroyed the spacecraft, but even without that, it would’ve likely been in safe mode, pointing in the wrong direction (so losing power) and spinning. It could’ve been in big trouble anyway.
I see what you’re saying, but to say that good engineering practices have 0% failure rates is a little bit of a stretch. To my mind. What I have read in other places suggests that the South Atlantic Anomaly (high energy particle bombardment) was also a factor, which seems to be a wild card that neither JAXA nor NASA nor anyone else could account for.
*am still in undergrad, my opinion may be worthless
It worries me that the system that is supposed to override failure or error in the reaction wheel system relied on the same data. What happened to redundancy?
@[ZEF]
The satellite itself was redundant lol – there will send up another in ten years.
The other two sensor systems that should have prevented this (sun sensor and star tracker) weren’t working properly, leaving a single point of failure.
“heads should roll”.
Don’t say things like that. They’re Japanese. You want o be responsible? Nooo.
Seppuku time! Seriously though, this seems like it could have been avoided. First, why send an update when the satellite is in or near communication blackout area? Second, didn’t they test the update before pushing it to the satellite? I would assume they have simulation or even physical model of the satellite to verify changes. Its really unfortunate this happened, especially so soon after it launched.
“First, why send an update when the satellite is in or near communication blackout area?”
They didn’t. The update came weeks before. It never caused a problem because the specific condition requires other things to happen. A better question would be “why was the spacecraft allowed to perform pointing changes while going through the South Atlantic Anomaly,” which is probably the biggest mistake.
There’s a much, much more detailed failure chain at Spaceflight 101 here. You’ll note that they don’t title it “software update kills telescope” but rather blames a “chain of events,” which is a better description. Even if the software update hadn’t killed it, the spacecraft would’ve been in trouble.
” I would assume they have simulation or even physical model of the satellite to verify changes.”
Yup! And part of the problem was that the satellite *physically changed* – they had just unfolded the optical bench, so they had to update all of the onboard models/etc. And those updates weren’t correct.
There’s actually additional failures in that linked article that weren’t mentioned here: after deployment of the optical bench, for instance, the Sun sensor didn’t work right. Which was a tertiary orientation sensor.
So you’ve got failure of all 3 orientation sensors coupled with being in a communications blackout coupled with improper thruster controls due to the spacecraft’s new configuration. I really feel bad for the engineers/scientists on this project, that’s seriously crap luck.
The term “software update” is not the best description but how else do you neatly summarize the bad configuration information update? The Spaceflight 101 is a good article so thanks for mentioning it. I didn’t locate it during my research, although I did work through the April 15th press release notes. The ‘101’ articles is based on that report. Later reports discount the radio signals. JAXA no longer believes they were from the Hitomi but something else, in part because they weren’t exactly on frequency.
It is tragic because it is the third instrument loss for JAXA: ASTRO-E launch failed and the rocket exploded; ASTRO-E2 (later named Suzaku) suffered a coolant loss that rendered the microcalorimeter, the most important instrument of the mission, useless; and now ASTRO-H… These have been the only three attempts to put an X-ray microcalorimeter in operation, I really hope they succeed at some point.
Clearly wasn’t running on Mac OS.
Name anything that costs >100,000 that does run on Mac OS? Lol nothing and for a reason.
don’t give apple any ideas.
The forthcoming Apple car probably will cost over $100,000 because of the sapphire windshield, sapphire dashboard, sapphire pedals, sapphire steering wheel…..
…And you can talk to it but good luck getting Bluetooth to send media to the 4 embedded Ipads.
At least we know it will be a thin car.
Basically any expensive system using BSD UNIX. OSX is UNIX 03 certified. Apple makes servers.
Apple “made” servers. They don’t anymore.
I know the phrase “If it’s not broken, don’t fix it.” isn’t really in a hackers vocabulary, it’s okay for a five pound project on scrap but all being said, perhaps they’d know better by now, when it comes to multimillion, multidecade long missions.
It was “broken” – at least, non-functional. They sent the updated code because the spacecraft had deployed, so the old code didn’t physically match the configuration of the spacecraft. Unfortunately, neither did the new code.
Sounds like the fail of the week
+1
this semantic pedantic bait is working beautifully!
“Attitude Control System (ACS)”
*Altitude
Attitude is the correct word. This means the orientation of the spacecraft. Altitude would be its height above sea level.
Attitude Stabilization System. :)
At least it’s probably not because of using archaic measurement unit instead of mandatory metric system (Mars orbiter).
Or using software from previous generation of launcher that overflow on new one but was not tested because of cost (Ariane 5)
And you can’t put the Magic Smoke back into that one.
weird that a $0.20 accelerometer could have detected this failure mode, and wasn’t included…granted, for space, it would probably have cost $100, but still. Literally spinning into pieces seems like something that doesn’t need a whole lot of precision to prevent.
I imagine the IRU had a really good accelerometer in it. Maybe a 50c one! If they’d known this was going to happen, of course they’d have fixed it, otherwise extremely specific hindsight patches aren’t practical.
It was probably a logic error, rather than lack of precision. The IRU and SST were each other’s backup, and probably the IRU had extra backup sensors in case one failed. The thing intentionally spun itself to death, that’s not supposed to happen, and not the sort of thing you can always foresee. Sometimes shit happens. Some unforeseen interaction, or a bug in the software, probably caused it.
We do pretty well with satellites, really, considering how many are up there, launched on enormous columns of supersonic fire. Failures should be learned from, but you can’t always find blame.
This was probably a mistake deep in a fault tree, so it’s tough to say “duh, how could you have missed it!”
1: Spacecraft needed to change orientation.
2: The star tracker was out of commission, due to the South Atlantic Anomaly.
3: The IMU had faulty data (also possibly due to the SAA).
4: The condition persisted long enough for the reaction wheels to hit their limit
I don’t think the article here’s giving enough credit to the SAA. The SAA is probably worthy of a Hackaday article in its own right: it’s probably caused more spacecraft failures than anything else.
The IRU, the best I can tell, used gyros, not accelerometers. The problem with gyros is the drift. The STT is the precision tool for determining attitude but it takes a ‘long’ (whatever that means) time to determine the attitude. Its data is used to update the IRU and to provide a drift compensation measurement. The IRU can report attitude quickly. Basically, the IRU got totally screwed up, possibly from bad data from the STT and due to the SAA.
I don’t think an accelerometer alone would help much. The only thing it would measure is the acceleration caused by the firing of the thruster, for the period of time it was fired. Remember, the spacecraft is in freefall. Accelerometers can’t be used to determine orientation in orbit like they’re used to determine your phone’s orientation in Earth’s gravitational field. There is not much field to measure against when you’re in freefall.
I suppose the accelerometer could measure the g-force induced by the spin if it was mounted away from the center of mass. But that only measures rate, not attitude. A gyro is much more useful in an orbiting spacecraft.
yea. the g-force reading was all that was needed to keep the thing from flying apart. if (GFORCE > (0.95 * DESIGN_TOLERANCE)) { shutDownEverything() }
These things use much more precise IMUs, a smartphone-grade IMU is would not be sufficient for this.
he is saying the smartphone grade IMU may have been sufficient to tell the sattelite that it was worsening its angular momentum, not claiming it has enough precision to subsitute the sattelites orientation detectors, but perhaps sufficient to arbitrate which is making nonsense…
Safe mode is supposed to be as simple as possible, you use safest and simplest sensors and actuators. I would never employ thrusters in safe mode. Even IMU should be secondary if possible. In safe mode the priority is to avoid losing the satellite, attitudewise all you need is to get enough sun on your solar panels and avoid pointing sensitive sensors to sun. Sun sensors, magneto meters and magnetotorquers should be sufficient. In addition, your software shouldn’t allow any commands in safe that would put satellite in anomaly between ground station passes.
Having said that, I’m sure those guys are smarter than me and thought all about this stuff.
Depending on the particulars not using thrusters at all might cause the craft to rotate to an angle where it can’t be easily recovered, eg an antenna pointed the wrong direction.
That’s my wild speculation, anyway.
Unless it’s hit by a meteor, it would only tumble either after separation with the launcher or if the control system fails in the middle of a maneuver. In both cases, by definition, the spin rates should be safe for both sensors, structure and communications. Most of the time the satellite is launched with either minimal or no software. And most satellites have low speed communications through omni antennas for command and control, that would operate under such spin conditions – good enough to upload software.
Either these guys made the dumbest mistake or a really weird thing happened, like all redundant memory units getting struck by particles at the same time..
” or a really weird thing happened, like all redundant memory units getting struck by particles at the same time..”
I mean, for that to happen, you’d have to be passing through some really high radiation flux. Like some sort of weird anomaly in the Earth’s magnetic field. Wait…
Thrusters were used when the reaction wheels had hit limit. At that point the spacecraft had no other way to fix what it thought was a crazy spin, most likely due to the SAA.
So the “don’t use thrusters ever” edict would result in a total loss if the spacecraft were struck by a meteor or something, causing it to spin.
Probably the better lesson to learn is “just drift through the SAA and hope nothing happens.” Making decisions when you’re being bombarded with high energy protons is probably not smart.
Well, let me rephrase then. Don’t let autonomous control use high power actuators in safe mode. You are better of letting magnetotorquers try to calm the satellite down while you assess the situation on the ground and decide whether or not to use reaction wheels or CMGs.
By the way, It might be that they uploaded a wrong inertia matrix. It says It happened after they deployed that big appendage and uploaded software.
“You are better of letting magnetotorquers try to calm the satellite down while you assess the situation on the ground and decide whether or not to use reaction wheels or CMGs.”
How do you assess the situation on the ground from a satellite that’s spinning?
You can’t. You can’t talk to it. Its antenna is spinning. That’s why you need autonomous control in a satellite.
If it were struck by a meteor, it’d be in a million pieces :P
No, not necessarily. Spin gets imparted by high torque collisions, which can be either high force or high radius. If the spacecraft gets clipped by something at its far edge, it might only be slightly damaged, but highly spinning.
its orbit would have changed as well
The average velocity for something getting ‘clipped’ by another object in Earth orbit is about 15,000 MPH. The average velocity for an object in solar orbit (like a meteor) would be several times higher. Random impacts in orbit don’t “slightly damage” spacecraft.
You can’t use magnetotorquers unless you know your orientation accurately and you’re rotating slow enough that the dwell time can make a significant change to your angular momentum. If you’re trying to correct an out-of-control rapid spin, you’re unlikely to know your orientation very well, and the effective torque (assuming you can time it properly) will be tiny on each rotation.
So what if they’re moving fast? There’s an entire distribution of debris sizes. Small ones barely do any damage. Large ones will cause major problems. Medium ones can cause significant problems but leave a recoverable satellite.
Plus “slightly damaged” might have been an overstatement – I meant “you can recover it into a stable orbit and talk to it.” Hitomi, specifically, had a long optical bench that if it had gotten struck, it could’ve spun the satellite but left the bulk of the payload fine.
Magnetotorquers won’t work effectively when you’re spinning, and can’t be used at all if you don’t accurately know which way you’re pointing. Thrusters are about as simple as you can get. You fire a solenoid, and you get thrust. They’re simple, reliable and robust. This is far simpler than reaction wheels and gyros. The only reason we use complicated reaction wheel systems at all is because thrusters have limited fuel.
Almost everything on the spacecraft had backups. There are two IRUs. Two star trackers. Two completely independent sets of thrusters and control systems. There’s a spare reaction wheel. It appears when the spacecraft went into safe mode it was supposed to use the thrusters along with the Sun sensors to get close to a proper attitude. That gives it a completely independent attitude control system. But the Sun sensors hadn’t been working correctly since they extended the optical bench, so it fell back to using the bad IRU data. And that cascade of failures killed the spacecraft.
I’m going to go ahead and blame this on C++.
Actually what language do they program satellites in? This particular one? I think for Pioneer it’s a couple of K of 1802 machine code, but presumably things have moved on.
Probably C on a well tread RTOS on top of a flight certified rad hard SBC.
I’m with you, Grenaum!
Even if it _was_ written in C, I’ll blame it on C++.
Removing Elliot from the xmas card list – that he wasn’t on, anywan.
The US military invented ADA as a language that has reliability built-in, designed to give clear results. You really CAN’T say that about C! One misplaced bit of punctuation and half your code path goes awry. There’s no memory protection. I wouldn’t let C code near my satellite, if I had one. There’s supposed to be standards for reliable coding, I wonder if they were followed. Of course implementing that is a management problem. The whole thing is a vast and complex system, more complicated that the satellite itself.
A standard for code lol
Well here it is –
Insecure dumb code made by insure dumb people for insecure and dumb people.
Aeronautics is usually done in Ada.
Not sure about aerospace. Fortran95? If it’s embedded software, Ada is still a good choice.
I’m puzzled as to why Sun, Moon, and Earth were not used as at least a backup orientation points. Regarding the failure, it might be a fear of reprisals against the lower ranks if they mention something to the top brass. Or just a culture of obedience. It happened many times, including Shuttle in the 1980-ies. For specific japanese example, this comes to mind: https://en.wikipedia.org/wiki/Minamata_disease Even after the poisoning source was found, company lied about the filtering systems, and they kept killing people for at least 10 more years.
Optical referencing (the star tracker), which is essentially what you’re talking about, was out of commission due to passing through the South Atlantic Anomaly.
Actually, clarifying, it did have a Sun sensor on board, and that was what “safe mode” was supposed to use, because one of the most important things the satellite needs, obviously, is power – out of control rotation means power generation goes away, and then you’re dead in the water.
Problem was that the Sun sensor didn’t work, apparently due to the spacecraft’s new configuration after the optical bench deployment.
Quite a blunder. I’m thinking that if only central processor could get the data from the solar panels, that would tell it the rotation speed, and whether correction applied is making things better or worse.
i am willing to bet the united states sabotaged the satellite by hacking into their space program and uploading bogus software.
the united states would love to prevent other countries from building competing or rivaling technology especially if it can threaten national security.
even if the satellite is peaceful for a good cause like radar mapping.
what if the satellite falls into terrorist hands it could be used to defeat our military just like the gpu and fpu in the power mac g4 in the 90’s (remember the g4 weapon commercials?)
The United States already allows extensive mapping of its borders via an agreement with the EU and Russia. Foreign powers can request a time for an escorted fly over of the U.S.. They are allowed to use whatever equipment is needed.
While, Yes, Japan is not part of this agreement, they can get this footage directly from their EU or Russian counterparts.
There’s no real reason for satellite espionage these days.
“There’s no real reason for satellite espionage these days” Wrong.
No, it’s just all outsourced now. NRO is a contractor.
So this thing was secretly a spy satellite? Disguised as a telescope? Doesn’t make sense. They just don’t announce spy sats, they keep them quiet. No bizarre cover story. And it certainly LOOKS like a telescope, assuming that’s the thing they actually sent up. It saw in X-ray, there’s nothing on Earth to see in X-ray. Except skeletons.
Don’t see how even the USA could claim a space telescope is a threat to national security.
They are all spy satellites now. Not all of them but come on. There is so much secret shit out there. How many nuclear missiles are up there? I bet at least 2 nations have COLD WAR era tech still up there…
Doesn’t make sense to launch nukes into space. You can launch them from submarines, which are just about undetectable. Cruise missiles are pretty much unstoppable. And even if you could stop a missile, you can’t stop ALL of them, there’s enough of them to make Earth completely uninhabitable for centuries. We’ve no shortage of surface-based megadeath.
Problem with Cold War tech, is it’s out of date. Sure, the USA is certainly still spending ludicrous amounts of money on war, the military-industrial complex never goes hungry. So I’m sure there’s still plenty of spy sats being launched each year.
Not saying the skies aren’t full of spies, because they are, but doesn’t mean this telescope was part of it. They’ve no shortage of actual spy satellites, they don’t need to piggy-back them on legitimate missions.
Those automatic upgrades to windows 10 are really getting out of hand.
This strikes me as just how similar people and technology are. I’ve known plenty of humans that fell apart after they spun out of control due to really bad software.
Yeah, that happened a lot in the 60’s. Many of them are still spinning really badly!
“heads should roll” <–YES, but a little to late.
"It’s what is called “experience”. Learn from it." <– Totally ignorant.
I find the modern attitude of Kumbaya simply laughable. So we should keep incompetent team members in the name of education? What about a manned space mission where the crew dies? Is there acceptable loss of life in the name of teaching and experience? How about an error that caused a flight to crash with a family member aboard? How about quality control failing on the trigger of a nuclear bomb stored in a populated area?
Life is not a video game that you can simply restart. Consequences are real and many times there is ZERO room for error. Would you want a neurosurgeon opening up your head gaining experience that causes your death?
The reality of this exercise is that more people than just the idiot will lose their jobs. Without the satellite many of the team members will be unnecessary, is that fair? What will their lessons be? How much public money will evaporate because of a fool?
There are some cases where perfection is required. In those instances being PC or loving will cause death. I just can't wait for this generation of engineers to start designing self-driving cars, aero plans, weapon control systems, and more.
I think people here are advocating learning from failure, not a lack of accountability.
why was it necessary to have the satellite carry $286M? when will it start falling down on earth? where on earth?
Sorry to inform you, the $286M was loaded into the spacecraft fuel tanks as $1 notes. What do you think they burn for thrust?
Yes that is correct. They used dollar bills for fuel because $1 in gas is much heavier than a $1 bill. That’s math.
does that mean all the money was spent, or it had some money left for landing back on earth?
No problem guys! I’m almost sure that Windows 11 will solve ACS, STT and IRU issues, please stand by and start collecting money for the next satellite :)
I think they are going to call it WindowsOne, though, not Windows 11.
I suspect “Culture Shock” as a possible root cause of this type failure. Many engineering groups I’ve worked with used new kids on the block (Just out of college, no real world experience) to perform the grunt work of coding and testing, leaving the senior engineers to accept the kudos. Upon the inevitable failure, the senior engineers are never culpable.
Y0re mileage will vary.
Does it seem weird to anyone that the authority system (IRU) in an attitude and positioning discrepancy updates its info from the info provided by a system it overrides (SSI)?
It’s to correct the bias/drift that builds up in a gyroscope system.
Looking more carefully at the press release info, the problem inherently wasn’t the screwed up configuration, although that turned the “problem” into “total catastrophe.” But it looks like what they’re saying happened is:
1: After the slew, the star tracker glitched – essentially, it rebooted, switching back to ‘acquiring’ mode from ‘tracking’ mode. This meant that the IRU had no bias correction, and it accumulated error.
2: By the time the star tracker came back on, the IRU was so far off that the star tracker data looked incorrect. It was greater than 1 degree off, so the IRU just ignored it. (This is the bug, in my mind – the star tracker data should’ve been timestamped and the ‘ignore me’ condition should’ve been if the deviation from last *corrected* IRU data, divided by the time since last data, vastly exceeded the drift time of the gyroscopes).
3: After that the spacecraft was headed to safe mode pretty much no matter what, and instead of a ‘recoverable’ safe mode, the screwed up configuration tore the spacecraft apart, because the IRU was sooo wrong.
Speaking as a Software Dev who works on similar platforms, I agree that item two on your list seems to be the “real” problem here. From a design perspective, throwing out obviously bad data makes sense, but in this particular circumstance, was the wrong action to take.
This is the exact type of thing that wouldn’t show up in testing either.
That’s what I’d flag as the “bad design choice” mistake.
What I’d flag as the “bad management choice” is what actually killed the spacecraft – trying to do *anything* without a known-working safe mode. I mean, they were slewing towards a *science target.* Why are you doing science when you’ve haven’t verified that the spacecraft’s flight controls are fine?
I explained this in another comment. The STT is a slow system but precise. The IRU is faster but drifts. The STT updates the IRU periodically to compensate for the drift. When you’re correcting a spin you need the fast results from the IRU.
Speaking of sun and star sensors, can anyone point me at a good electronic sextant project?
Back in the cold war they were top dollar tech, now I think it could be done far more cheaply.
The burning question that hasn’t been answered is “How much spin is required to dismantle a satellite?”
Surprisingly not all that much, they are fairly fragile…
Per the JAXA report the spin was mainly on the Z-axis which is the long axis of the satellite. Going much above 20 rpm exceeded the design limits. The satellite went into Safe Hold when that limit was approached.
They said 20 deg per hour, not 20 rpm put it into safe mode. That’s 1 revolution every 18 hours, or 0.000925 rpm. That’s when the thrusters started firing. I’ve not seen any estimate at how fast it was rotating with the first object separated.
It probably doesn’t matter in the long run.
For a satellite to maintain a Geo-stationary orbit for 10 years then it must have a huge payload of fuel for periodic corrections so there would be more than enough fuel to destroy the satellite a thousands times over.
Hitomi was not in a geostationary orbit. It was in a circular low Earth orbit at 550km, 31 deg inclination. Similar to the Hubble space telescope. The spacecraft doesn’t have that much fuel on board, because it very rarely uses thrusters to change its attitude. It normally uses reaction wheels and magnetotorquers, which are purely electric devices.
I sit corrected :)
And I told them they shouldn’t use an Arduino for this thing!!
Arduino? You wish. It was a PIC that failed after trillionth RAM bank switch :)
Solar sails? I think you mean Solar panels or photovoltaic arrays.
That’s gotta hurt…
Lesson learned: If it’s working DO NOT SOFTWARE UPDATE.
This is why I think software companies shouldn’t sell cars. I predict we will be seeing Apple cars dead in the middle of the road because some software update bricked the car. People will just get out, leave it there, then go buy a new one. Just like cell phones.
It WAS NOT working. The spacecraft, as launched, was in a folded position. It can’t do science from there.
Unfolding the spacecraft required updating all of the control software/configuration details. That’s what screwed everything up.
OK FTDI !!!!now, enough is ENOUGH ! lol
I laughed.
Imagine the lawsuit!!! It would even eclipse the Micro$oft Internet Explorer anti competition.
I transposed a couple of letters and made a $50,000 error one time. And I knew of another programmer who made a million dollar booboo (he got fired). But I would hate to live with a 286 million dollar mistake – every day you wake up and remember and then try to forget and then remember – endless loop.
There is far more to this than just blaming a programmer.
In general a programmer will do exactly what he is asked to do in a concise specification. If things then break, explode fall apart then it’s not the programmers fault.
Bummer, but as they say, shit happens. On the bright side JAXA has the ultimate fail to to submit to Hackaday for consideration.
Do you think it was a matter of bad testing? or tests not done in a proper testbed ?
The switch to Agile development wasn’t as smooth as we hoped.
Bummerson.
What do you want to bet the developers didn’t bother to comment the code?
Reminds me of how if you change monitor settings you get a timeout saying ‘Is this new setting OK? Press yes or it will revert back’
Where the idea is that if people change things so the monitor doesn’t display a image anymore it is corrected automagically.
So it seems this technology might be an idea for space industries, have a backup firmware, if contact with earth is not made within a certain time revert to the old state. Simple and cheap and saves millions, since it’s not the first time such a mishap occurred, and not just from the Japanes I like to add..
“i did not read any of the above comments.” is it not odd that it seemed to aquire catastrophic failure at the perfect point at which it could not be seen and/or monitored? is this the effect of a blackhat system on newer higher orbit satillites, or a directed attack via pulse technologies? has anyone else noticed the new stars and array system blossoming overhead? plus, with the magnetosphere we lost reading at 6 am on may 8th (north america) due to a massive CME, people and climate have decidedly reacted differently since that date. was our orbit altered? (intentionally or not). (locally about 5 days before the 8th 3 electric transformers blew up in my city, they exibited the characteristics of an EMP not a black out. electrons stopped and it was a radial outage not a grid. the outside lights on my building went out, while the inside. on the not hit/shielded areas stayed with power (they are on the same circut? isnt that impossible?))
And this, ladies and gentlemen, is why, when you commission a satellite, you should also commission a simulator. That way, you can train up your flight ops team ahead of time, test out unusual procedures before committing them to flight model, and run firmware upgrade tests safely on the ground. The cost, compared to losing the launched flight model, is chicken-feed.
(Oh – and if you need the help of someone who wrote most of the software for a commercial hardware-in-loop satellite simulator, let me know!)
Somewhere in Japan, there is an engineer saying ‘I told those bastards in management that we needed more time’ and a manager saying ‘those bastard engineers and their laziness are going to be the death of us. They could have gotten it done right in the schedule I gave them, regardless of the fact that it was 1/3 the length of the one they said they needed.’
It is a very great play, solving many problems for people.
Cua Thep Goonsan