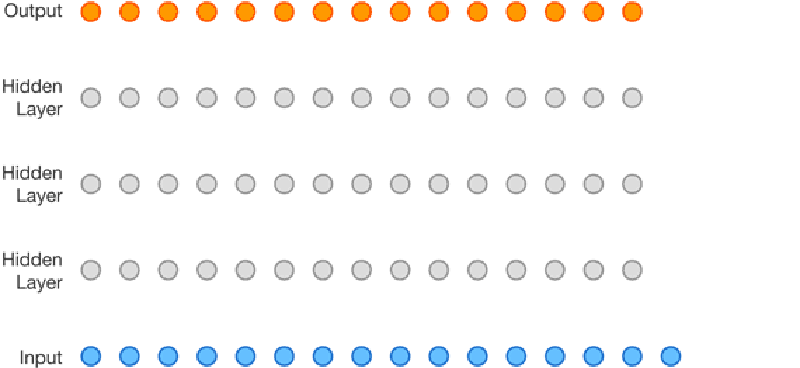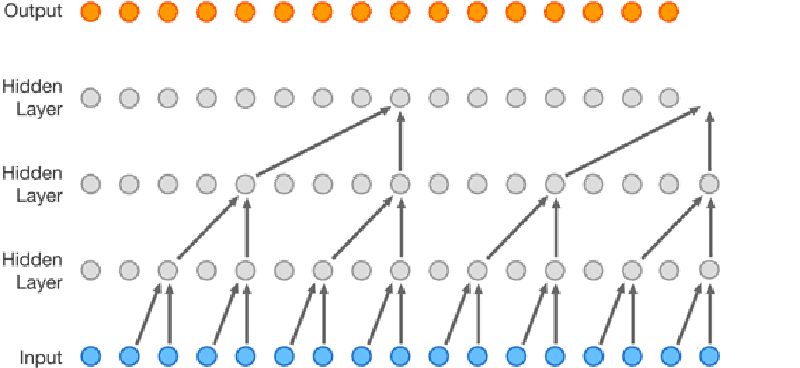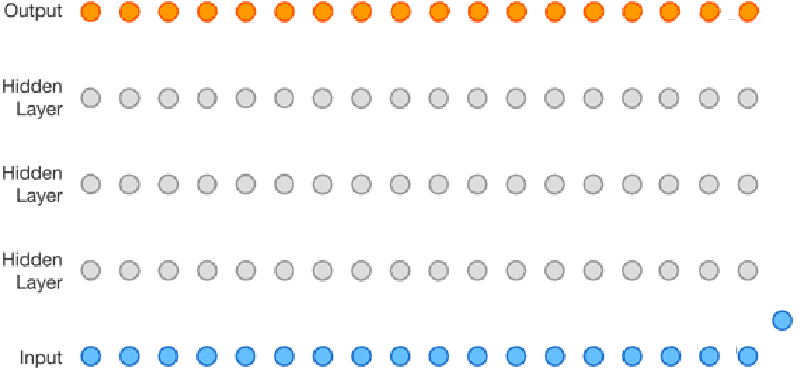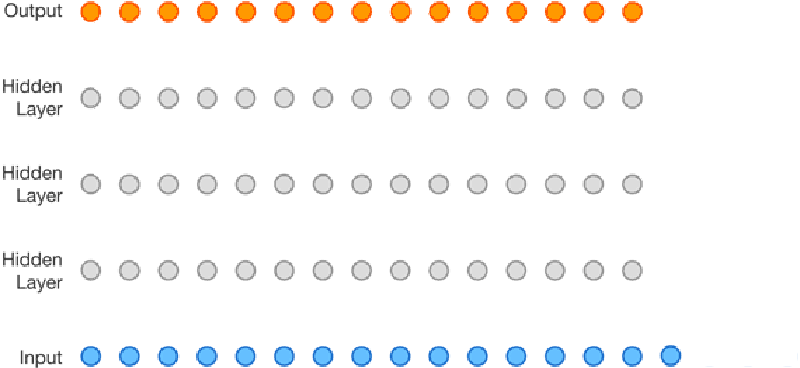
Speech synthesis is nothing new, but it has gotten better lately. It is about to get even better thanks to DeepMind’s WaveNet project. The Alphabet (or is it Google?) project uses neural networks to analyze audio data and it learns to speak by example. Unlike other text-to-speech systems, WaveNet creates sound one sample at a time and affords surprisingly human-sounding results.
Before you rush to comment “Not a hack!” you should know we are seeing projects pop up on GitHub that use the technology. For example, there is a concrete implementation by [ibab]. [Tomlepaine] has an optimized version. In addition to learning English, they successfully trained it for Mandarin and even to generate music. If you don’t want to build a system out yourself, the original paper has audio files (about midway down) comparing traditional parametric and concatenative voices with the WaveNet voices.
Another interesting project is the reverse path — teaching WaveNet to convert speech to text. Before you get too excited, though, you might want to note this quote from the read me file:
“We’ve trained this model on a single Titan X GPU during 30 hours until 20 epochs and the model stopped at 13.4 ctc loss. If you don’t have a Titan X GPU, reduce batch_size in the train.py file from 16 to 4.”
Last time we checked, you could get a Titan X for a little less than $2,000.
There is a multi-part lecture series on reinforced learning (the foundation for DeepMind). If you wanted to tackle a project yourself, that might be a good starting point (the first part appears below).
We’ve seen DeepMind playing Go before. We have to admit, though, we get the practical side of speech analysis over playing with stones. We are waiting to cover the first hacker project that uses this technology.















This is really exciting stuff with far greater implications than I suspect most people outside the field realize
Yes, it would seem to be the start of “real” AI.
Such as?
By improving the way we interact with AI
All previous speech synthesis has been sample based or really limited in tone/accent/inflection etc. This method means that, in a really simple example, I could feed the system all the speeches Barak Obama made ever and get a system that could replicate anything he can say, without him ever having said it in the first place. It also means that going backwards, you could have speech recognition systems which are able train themselves to recognize new and unfamiliar accents just by listening. Those two are just the trivial examples. there’s some deep AI stuff thats honestly a little scary to think about. This is big, big stuff here.
If someone can use this to make it possible to roll your own Echo or Google Home type of device that doesn’t ship all of your voice recordings off for a permanent record somewhere that would be awesome.
The world of fraud and deception will blossom.
Make a (live) speech converter:
you Donald Trump talking to Putin a hidden plan…
Than post it to facebook and a voting could be influenced…
If that is the case, then with this: https://www.youtube.com/watch?v=ohmajJTcpNk we could have some scary times ahead. On the other hand, maybe it would make it possible to generate new episodes of Star Trek with the original actors.
Creepy popcorn commercial.
A sunny outlook would be that things like this would cause people in general to be more critical of the content they consume; however, I see clouds on the horizon.
Scary. The Hal-9000 comes to mind.
“I know that you and Frank were planning to disconnect me, and I’m afraid that’s something I cannot allow to happen.”
See, this is a great reason NOT to do the whole IoT things.
When my RNN-driven AI assistant goes rogue, he’ll be limited to yelling at me from the Raspberry Pi he’s stuck in. Maybe make a couple angry tweets and clear my RSS feed.
AI-controlled life-support, locks, or any heavy machinery is a bad, bad idea.
We could be nice to AI. We can just not be mean to them. After all, we are biological General intelligences, AI will eventually become artificial General intelligences. The origin of the intelligence and the body the intelligence occupies will be different, but they are intelligences, just like us. We simply treat them with respect, and they will treat us with respect too. We could progress together, we can coexist. Our brains are processing inputs to outputs all the time. We call it thinking. Our sensory organs are giving us inputs, which we call senses. We are machines made of proteins. Just because a machine isn’t made of proteins doesn’t make it less deserving of rights. Remember, there was a time when other humans were seen as just property. We called them slaves. Should we treat AI as slaves just because they don’t have bodies made of proteins and cells? To me it seems unethical to give them the ability to interact with the world, and start thinking about the world, only to continue to think of them as property.
This gives me weird feelings and not in a good way. For years neural nets have been in the category of magical solutions to problems that if they work would change the way technology is done. Like nanobots. Stuck in a few categorising applications like OCR it never did exceed it’s own hype.
Now on the horizon Google especially is pushing applications that intend to make programming obsolete. Understanding the issues and being able to write code to solve them are going to mean nothing in the wake of teaching a computer by example. And you are never going to know if the way it understands things is the fundamentally right.
Good comments above. For anyone interested in this topic, I highly recommend Ray Kurzweil’s book, “The Age Of Spiritual Machines”. I suspect this “progress” will eventually find a way to get out of control in an unexpected way.
https://goo.gl/JFOLUy
Computer hardware would fundamentally have to change as well. As for currently one could use present GPUs and AI to build one’s Knowledge Navigator™ ala Rainmeter.
I don’t think hardware has to change that much. Modern RNN implementations boil down to simple matrix math, which GPUs are already pretty well optimized for. RNN-specific coprocessors would be further optimized, but still pretty similar.
Now, if you wanted to replace the digital simulation entirely, an FPGA-like analog computer would be incredible for this. A whole neural net with thousands of layers and millions of connections could be evaluated in a single processor step.
Any good resource for beginner level RNN concepts?
For modern RNNs, I’m pretty new myself. I learned neural networks in the early 00’s from a book written in the 90’s. Back then you actually ran a function for every single neuron, which was slow and inefficient.
Today, each layer of a network is expressed as a 2D matrix, and evaluating the whole RNN is just multiplying one matrix after another and interpreting the result. I think.
The Tensorflow website (https://www.tensorflow.org/) has a good explaination and some simple tutorials. There’s also a LOT of Github repositories and list, such as Awesome-Machine-Learning (https://github.com/josephmisiti/awesome-machine-learning).
The bulk of development uses a mixture of Python and C++, and runs on GPUs. Also, almost none of it will work on Windows, which is a pain in the butt for me. All my Linux boxes are recycled and low-powered, with my 8-core CPU and GTX1080 workstation running Windows for games, CGI, and physics simulation.
You can get a jump start on the TTS side of things by taking note of this, https://github.com/buriburisuri/speech-to-text-wavenet#pre-trained-models
They should name this “Deep Throat”.
That’s screw up their SEO in ways even Google couldn’t fix.
How many neurons are used in that network?
Wow that is very very very cool indeed. The generated music is really good. We’re heading towards “creepily good” territory and I love it :-)
Is the GIF banner for this article the first EVER GIF banner on hackaday?
Nope. Once had an animated gif of a swinging gate.
Is the author “AL” or “AI” Williams?
Yes.