[James Bowman] of the Willow Garage published a paper on his J1 CPU core for field-programmable gate arrays. This was originally developed and used for the Ethernet cameras on the PR2 (you know, that incredibly expensive beer delivery system?) robot. It uses a 16-bit von Neumann architecture and lacks several processor features you’d expect a CPU to have such as interrupts, multiply and divide, a condition register, and a carry flag. None-the-less, its compact at just 200 lines of Verilog and it can run at 80 MHz. [James] compares the J1 to three different FPGA CPU Cores commonly used and discusses how the system is built in his 4-page paper that has the details you’re interested in but won’t take all day to dig through.
J1: A Small, Fast, CPU Core For FPGA
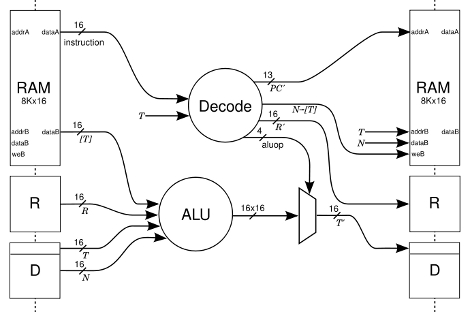














A forth machine. It’s been done a few times, but this guy’s work is excellent. Nice paper and writeup. If you want to see other versions of this (complete with schematics) you can look at http://www.holmea.demon.co.uk/Mk1/Schematics.htm
and better yet:
http://www.jwdt.com/~paysan/b16.html
A forth processor is basically the “hello, world!” of the FPGA hobbyist. As I understand it, a certain HAD reader has some expertise on these matters.
Very nice write up. You really can’t argue with that code density either.
I never saw the appeal of stack machines unless you happen to have some sort of forth fetish, but the results certainly look impressive. I wonder how big it is when mapped onto the FPGA.
All it needs now is for someone to do a competent C to forth compiler. :-)
What prosser did u use for the TYL
This would certainly come in handy if you needed a general-purpose CPU in an already well-purposed FPGA.
Microblaze or an equivalent is your best bet if you want an actual general-purpose CPU in an FPGA. You get a compiler, industry support, etc. This is a processor for when you need a specific purpose.
I loaded this into a Spartan-3 with a few mods for testing and it worked well.
Brad
People here smack-talk about “Forth Fetishes,” and these CPUs being only good for “specific purposes.” These people are woefully ignorant and are the primary reason why stack architectures aren’t as popular as they really should be — such people hold influential positions in the market, when they really should be sent back to school.
They look to more complex architectures with sheer awe and admiration, thinking that more complex is obviously always better, because, well, it’s more complex, you see? Obviously, SOMETHING (besides guaranteed employment of more and more engineers) has to be good about these architectures, right?
Stack CPUs are every bit as fast as RISC chips of considerably greater gate density. Comparing the J1 against a MIPS, you will find they retire about the same dynamic mix of instructions at the same rates, give or take some reasonable epsilon. That’s because, in any Von Neumann architecture, regardless of instruction set, there is only so many ways to accomplish some goal (hence why software patents are evil, but I digress heavily here). So, clearly, your preconceived notions of what is special- versus general-purpose are horridly off.
I’ve never, *EVER*, met a stack CPU that wasn’t general purpose enough to put an 80486 to shame with only the tiniest fraction of assembly instructions. Sure, such CPUs won’t run C apps as fast, but that’s OK. Remember the hoopla when RISC vendors announced quite proudly that their chips were “optimized for C”? I do.
So, why aren’t stack CPUs more popular? Because people don’t want to grok Forth or Lisp (they’re ostensibly too “weird” for them; to these, I claim, you’re not programmers. A real programmer can code in ANY language, not just their favorite pet), both of which compile nicely to stack CPUs. They prefer the likes of C, which does NOT compile competently well to efficient RPN. Random-access to parameters is preferred on such architectures, and not just during heavy math either. Thus, the CPUs need registers, which widens instructions, which means you need address decoding on the register banks, which slows the chip down due to propagation delay, which means you need pipelining to hide latency and restore average throughput (note: not guaranteed throughput), which means you need better branch scheduling and fewer branches, which means fewer subroutines, which means greater in-lining to keep those pipes filled, because subroutine overhead often costs more than a well-factored subroutine to begin with, . . . all of this adds up to WAY more complex ways of making a chip faster (caches versus instruction packets, superscalar execution units versus just putting multiple cores on a single die, etc.).
And don’t get me started on power draw.
So, kindly, don’t talk to us about fetishes when you carry a full domination dungeon in every computer you own.
Very nice work.
Your readers might also be interested in this 200 line minimalist RISC SoC (annotated Verilog) http://www.fpgacpu.org/papers/soc-gr0040-paper.pdf .
Here’s an older one written up in Circuit Cellar:
http://www.fpgacpu.org/xsoc/cc.html
Here’s a nice minimal one from Chuck Thacker:
http://www.bottomup.co.nz/mirror/Thacker-A_Tiny_Computer-3.pdf
Happy hacking!
SoC systems are becoming more well suited towards every application.
It might just be my signal processing background, but von Neumann architecture, ewww. What happened to Harvard?
Harvard architecture doesn’t work so well with C compilers. And having two address spaces often translates to two RAMs in an FPGA which can be a issue when you only want something small. Restricting look up tables to data space can be a pain too.
If you’re doing signal processing in an FPGA, you want to be parallelizing as much as possible and avoiding a CPU all together.
@Samuel A. Falvo II
+1
Samuel A. Falvo II:
Saying that stack processors aren’t popular because because people don’t want to use Forth or Lisp might be in some sense true, but it’s missing the point. People don’t want their choice of language restricted by the architecture they’re using.
C is a grotty language to start with if you want to perform optimising compilation to pretty much any architecture, but register-based architectures cope fairly well. They also cope fairly decently compiling a lot of other (much more abstract) languages. Having your architecture strait-jacket your development process is a problem.
Moreover, having a register set allows way more flexible access patterns. Not all algorithms map down to nice RPN expressions. Not many people love the x87 instruction set. Furthermore, if all you’ve got is a stack, as soon as you go outside of it, all you’ve got is main memory, and things get very expensive.
Claiming that all the baggage of superscalar execution is the fault of having registers is more than a little disingenuous. Plenty of it is there to just get more parallelism, not to make up for the weaknesses of registers. I am rather intrigued how you’d suggest to build a superscalar architecture that can process a stream of stack instructions efficiently.
I don’t think modern general-purpose CPUs, with their power-hungry OoO superscalar execution, deep pipelines, complex branch prediction, etc. are a panacea, and indeed I believe they are the wrong answer to many problems. However, I think stack machines are the wrong answer to many more.
For this kind of application, though, they’re pretty cool.
Better late than never.
So, on topic, something small that can fit in FPGA’s, as a starting point to expand upon. The size helps. So, Samuel is also a standup guy.
Now, let’s put it this way, as far as actual chips go. 4,000 transistors for a forth processor, 10k transistors for a bigger one. But let’s talk about a much more capable one, 100k transistors, maybe with some more memory on top, maybe not. Now compare to a more modern Intel CPU with over a 1000 instructions (or an Arm with over 1000 instructions for that matter). So how many more can you fit in an array. Now realise that current forth chip design has gone through a phase of lowest energy consumption per cycle processor in the world, but also capable of highest cycles (but not current focus, so that claim is uncertain). So, at the reduced energy you can pack incredible amounts of general purpose processing power per area, particularly because of the low heat. What matters in programming is results, and if a reverse Polish notation twin stack machine delivers the highest performance, then you should program it.
Now, the darker side. The current genre of this, is exotic, to say the least, and not that functional, requiring work to get highest end results. This is not like normal forth, but more bare bones embedded hardware programming with hardware optimised for size/performance, not necessarily for ease. This is OK, for large volume program once products, as many smaller things can be (the current batch are meant to compete with the smallest programmable hardware, glue logic, hence features do not need to be as expansive as a desktop PC).
However, the lighter side. I have desired to design a much smaller comprehensive microprocessor architecture optimised for performance and low energy per cycle. A higher end processor is often implemented with features requiring lots of transistors (the sub systems to boost performance in many high end architectures also requiring a lot of space in the implementation of instruction set handling, the instruction set design also being a limiting factor on performance, more on this shortly). My architecture redesigns these systems to be smaller, and answers the register question. The simpler instruction set design and handling of forth processors not only reduce transistor counts and energy usage, but open opportunity to increase speed as closer to the highest the chip making process can go (which maybe 10x faster, though leakage would be modifying this). Chip making process design rules include wider safety margins to prevent issues, but simpler forth designs allow hand made designs and optimisations, that can be replicated in arrays.
I’m not really aiming for Forth but basing it off of Forth’s efficiencies. So, 100k transistors is what I’m aiming for, but as close to 10k or less for the actual processor (remember, this is a multiple component design). The issue is as usual, how much extra memory per core and where, to maximise the potential for the application (which general purpose changes, making this difficult). However, as the group is involved with actually making chips, which is extremely expensive, I turned my attention to figuring out a much better solution proposal than FPGA that can solve this. The level of functionality aimed for is to be able to run something competitive with Linux at least. I am also aiming at a much cheaper and much higher performance process to make the chips. To be used as a general purpose product and other. Performance estimates per unit of area (hopes at this time) are at least 10x-100x. Plus other metrics. However, if I do have dementia, I don’t know if it will ever be completed. But despite length of time, even if function based quantum/optical computing becomes a reality, I see this architecture at its core, from nearer the beginning, as a procedural management processor design, one instruction after another that will still be used with newer types of computing.
I can say, from my estimations, that we are being defrauded in the industry that much better can be done. This is a thirty year effort to understand the ubiquitous optimisation of performance.
Stack-based CPUs are everywhere, especially if you also include virtual CPUs. If you’ve programmed in Java, or any .NET language, you’ve had your code translated to a stack-based intermediate language.
But coding *directly* in a stack based language by choice when there are alternatives available, is accurately described either as a fetish akin to masochism, or simple elitism.
It’s not a matter of whether people “grok” or understand it, as Forth is actually very easy to understand. It’s just an unnatural and inefficient way of writing code.
So I will never code in Forth unless absolutely necessary. I don’t care what kind of “domination dungeon” might be in my CPU. It can play whatever kinky superscalar games it wants behind the scenes, as long as it does what I need. At least I’m not spending the day needlessly flagellating myself!
@Samuel A. Falvo II: You are right, everyone else is not only wrong, but stupid too, and only you know the secret that can save us from inefficient code and slow development time. Thanks, Samuel A. Falvo II!! My eyes are now opened to the truth, and I can begin fetishiz . . . I mean, appreciating a better way of living.
What about Navré soft core? 900 line source, but AVR compatible so a standard C compiler like gcc can be used.
Also ~80Mhz and ~80 MIPS
http://opencores.org/project,navre
@nes – “Harvard architecture doesn’t work so well with C compilers.”
So many misconceptions, so little time.
@Salvo-
I see you’ve been drinking the kool-aid for a while now. As rants go, I give it 3 out of 10 stars, a couple of dups with additions and a pop.
Excellent, even if your roots are showing.
In the meantime, your “No true programmer” argument/definition is daft… my definition of true programmer includes being able to actually start working on the problem, without having to code up the routines for the libraries needed to provide the scaffolding to get started. And I say this as a forth fan – forth was OO long before it became mainstream.
@sgf – “Having your architecture strait-jacket your development process is a problem.”
Only for a sufficiently small mind. Unless you’re doing floating point matrices on relay logic, or using dot Net libraries, this hasn’t really been applicable to any processor for a decade or two.
There is no spoon.
Chuck Moore stole it.
Can you tell us exactly how many wedgies you had when you were in school Samuel A. Falvo II?
And sorry to double post this,
@ Samuel A. Falvo II, WHY, why, why, why, why, why, are you still using 80486 chipset computers? 1989 called, and they want that pocket protector back.
@Samuel A. Falvo II
You should take up Ruby or something..
@turing’s dog
‘@sgf – “Having your architecture strait-jacket your development process is a problem.”
Only for a sufficiently small mind. Unless you’re doing floating point matrices on relay logic, or using dot Net libraries, this hasn’t really been applicable to any processor for a decade or two.’
The reason that architecture rarely strait-jackets development processes nowadays is because the architectures and tools which don’t limit you as much are the ones which win out. Which is why stack-based CPUs aren’t the common thing. Which, er, was my point.
@turing’s dog: I think the C on Harvard was a fair point. Care to elaborate on my misconceptions?
C works very well for programming PDP11’s, but I think as soon as you break apart the flat memory model compromises are required. I formed my opinion having worked on backends for lcc and sdcc. I do like the language though.
Back on topic; stack machines are not a panacea for efficient software (all you’re doing is limiting the data to which you have immediate access without penalty and forcing the programmer to deal with it) and don’t normally map to FPGA all that well (where a RAM costs the same as a stack), but this one and its applications have turned out very respectable.
A nice FORTH implementation in 200 lines of verilog seems promising (though 200 lines of VHDL would be more impressive). Being one of the aforementioned ‘forth fetishists’ (I’ve got a kink for all sorts of languages, and I’ve been waiting for someone to try to implement a dedicated prolog machine), this excites me quite a bit.
By the by, as any compiler course should teach you, it’s trivial to compile C down to a forthlike. Whether or not your C code runs slower when compiled into a stack language is a matter of the compiler and of your C code. If you are worried that your code, when automatically translated, will be slow, don’t use an automatic translator.
There is a Prolog to Forth compiler developed by Odette in the eighties for NASA and used for embedded expert systems … very hard to find but someone still has a copy of the Journal of Forth Applications and Research vol. 4 to scan.
Actually, I know Samuel Falvo personally. He writes Python, Ruby, and Java code daily, and some years ago, was hacking on OS kernels. I think you under-estimate his abilities and knowledge. Ignore the rant, and read the message instead.