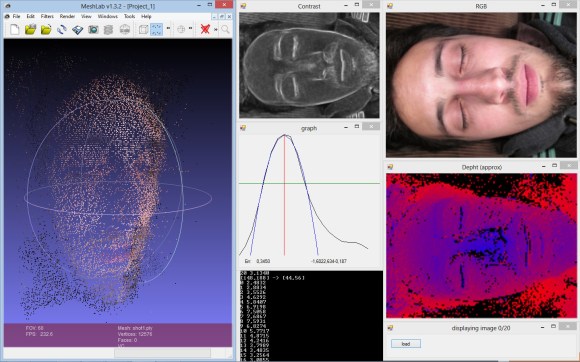
We understand the concept [Jean] used to create a 3D scan of his face, but the particulars are a bit beyond our own experience. He is not using a dark room and laser line to capture slices which can be reassembled later. Nope, this approach uses pictures taken with several different focal lengths.
The idea is to process the photos using luminance. It looks at a pixel and it’s neighbors, subtracting the luminance and summing the absolute values to estimate how well that pixel is in focus. Apparently if you do this with the entire image, and a set of other images taken from the same vantage point with different focal lengths, you end up with a depth map of pixels.
What we find most interesting about this is the resulting pixels retain their original color values. So after removing the cruft you get a 3D scan that is still in full color.
If you want to learn more about laser-based 3D scanning check out this project.
[Thanks Luca]














This could be a game changer for autonomous vehicles depending on the computational expense vs. alternative methods. Even if it requires more MIPS, those will likely get less expensive faster than the hardware methods currently in use to reduce computational requirements. I would expect that this method of processing would lend itself to analysis by FPGA?
I believe this should lend itself to FPGA usage quite well, since each pixel can be processed independently once all the images are available.
The single largest issue I see is that you need two different focuses, so you need not only two pictures, but two pictures from the same camera. This sounds a lot slower than current methods, no matter how fast the processing goes.
This is not a new thing. It’s been used in microscopy for years. It’s not practical to use on a macroscopic scale.
This might work very well with this: https://www.lytro.com/
It is a multiple focal point camera.
I wonder what kind of issues this technology might have. How accurate is it in real world situations with varying lighting, etc.
Also came to post this. Very promising!
Heh, yea the lyrtro camera would be perfect.
Another idea i had was to basically take a cd-like lens assembly and mount it to a high speed camera, to change the focal length of a shot from macro to infinity within 30 times a second, and then taking each frame (probably running on about 3000 fps) to create a “full focus” 30fps video. Could also use that to get a basic depth map (probably rather low precision or accurate) in each video. This could help VFX artists to create more realistic scenes.
Nice point. That’s more or less what I was thinking to do with a cheap Android phone on which camera i managed to force focal distance.
But is the information to use lytro images available to the public?
Last I checked I found their software lacking, you can for instance determine the position of the DoF but not set its size, so for instance have near AND far in focus or a selectable depth, it was all very dumb and basic, and when I checked (back when) I did not hear of any alternative viewers but theirs.
And I hear they only last week unlocked the wifi radio that apparently was inside the damn camera all the time.. took them only a what? A few years?
I like the concept of lytro but question the way they do things.
this 3d scan is phenomenal and the linked camera is insane, I believe I have just seen a good chunk of future innovation and I only wish I could afford that camera lol
You can’t afford a $300 camera?
Not everyone has $300 they can afford to spend on a whim.
No.
Once again, Mike Szczys shows his inability to correctly read a camera-related article. It’s not taking photos at different focal lengths.. it’s a focus stack photo. That just means changing the focus of the lens. Not changing the focal length of the lens used.
in fact that’s a matter of perspective/semantics you cant change the focal length of a lens (under normal circumstances) but you can easily change the focal length of an optical system i.e camera.
hahaha this guy re-inveted depth from focus :)
come on….this is a wll known technique in computer vision.
http://en.wikipedia.org/wiki/Depth_of_focus
sorry pasted the wrong link there
http://www.google.co.uk/#gs_rn=17&gs_ri=psy-ab&suggest=p&cp=12&gs_id=bg&xhr=t&q=depth+from+focus&es_nrs=true&pf=p&sclient=psy-ab&oq=depth+from+f&gs_l=&pbx=1&bav=on.2,or.r_qf.&bvm=bv.48293060,d.bGE&fp=1fcd42495e594388&biw=1920&bih=910
You should use https for wikipedia, you don’t want the damn cops and GCHQ have it too easy.
Wouldn’t call it well known technique, compared to stereo input and IR mesh input, given there isn’t a OpenCV function for it.
But on the other hand when you think about it, the technique is blindingly obvious.
I was recently thinking about if this would be possible. As I noticed that it was possible to see depth with one eye closed … Very nice stuff!
@pieter-jan: It is not possible to “see” depth with one eye. It is only possible to surmise it based on observations over a period of time.
You mean, like, your brain estimates depth from multiple images? So, basically the same as “seeing” depth with two eyes?
Completely different, parallax is used to sense with two eyes. With only one eye I can’t tell if there is a person in the distance walking towards me or away from me until I notice if they are getting bigger or smaller.
From wikipedia https://en.wikipedia.org/wiki/Depth_perception
“Accommodation
This is an oculomotor cue for depth perception. When we try to focus on far away objects, the ciliary muscles stretch the eye lens, making it thinner, and hence changing the focal length. The kinesthetic sensations of the contracting and relaxing ciliary muscles (intraocular muscles) is sent to the visual cortex where it is used for interpreting distance/depth. Accommodation is only effective for distances less than 2 meters.”
@Willis75 That was what I meant of course. I just realised that stereo was not the only way people estimate depth.
“Those aren’t small cows, they are a along way away” – father Ted
I was going to point that out. I suffer from amblyopia and the net effect for me is very poor stereo vision. 3D TV does not work for me etc, but I’m not terrible at judging depth (not fantastic either), if wifey were around I could give you a more technical info regarding other visual cues.
A little OT, but hey, my wife is an optometrist and they get emails from some of their professional bodies with news about what’s happening in the optical world. She came across some info in one which mentioned a treatment for amblyopia in adults. It uses a tetris game where both eyes receive some of the information and each individual eye also receives some information not available to the other eye. Apparently it’s produced significant improvement in those with amblyopia. So I’ve a little project planned once I get some time to use a stellaris launchpad and a couple of Nokia 3310 screens to build a pair of cheap goggles to do the same. Might be a decent project for someone with an occulus rift. The only problem then is the potential for double vision.
If I ever get there I’m sure I’ll write it up and present some quantitative data on any improvement in my vision.
This might help you understand why this approach works: https://en.wikipedia.org/wiki/Dolly_zoom
I know this has been tried on UAVs with single cameras. Don’t really remember how well it worked.
My Lumix Camera (and maybe other brands) uses that method instead of sonar or IR range to focus the camera. When you press the focus button the focus goes far and close while analyzing in every step the “focusiness” of the image, Finally the lens stop in the step where is the better “magic number”. Its a good method for avoiding bad focus due to glass windows or other objects that makes false “echoes” for IR or sonar. But isn’t a very good method for photography sky or clouds without “solid” objects
Yup, this method (local contrast maximization) is used in most point-and-shoot cameras, and simple autofocus cameras like those in most cell phones.
I’m not aware of any cameras that use IR time-of-flight to focus, and ultrasonic is a bit out of fashion today (though I’d love to be proven wrong!). DSLRs use another interesting method (well worth a Google search)!
It is just a standard focus stack based depth estimation. This is exactly as wtomelo says how passive focus cameras find the focal plane (e.g. calculating the pixel variance or the gradient variance on a small box in the center of the image and taking the focus plane where it is max).
For every pixel you get a depth value, thus 3D info (x,y, and Z=depth). Then you can easily calulate the X,Y world coordinates as well.
Shroud of Turin
Hi guys, I’m Giancarlo Todone the author of this work: Thanks for all the positive comments!
To all those saying that this is just plain depht from focus stack, well.. you’re right, but i didn’t forgot to mention it in my article…. my motivations for “reinventing the wheel” were lack of good free/open source code. For what concerns the LYTRO… well I hope to have a chance to play with it sooner or later :)
Very well said Giancarlo.
Many people don’t like to read before they bite off heads. ;)
I’m a huge fan of what you’ve done here! Great work!
OH, and is your server down? Seems to be at the moment.
Do you have a direct link to Git depot please?
Thanks.
Oh, yes… my host doesn’t appear to like all your interest, and keeps crashing the web app… i’ve to manually restart it every now and then, SORRY :(
Git is here: https://github.com/jean80it/DephtInition
Edit: i quickly implemented a sort of auto-reset on my site… hope this will allow you to take a look without further trouble… sorry again (have to change host :P )
Hi Giancarlo,
was there a particular app that you used for your phone, or did you write something yourself? Any chance you could post a link?
Thanks,
Phil.
I reverse engineered the stock camera app of my LG-P500 and found that there are 10 presetted focus distances i can choose from by sending a custom command to driver. Probably this is something that just works on that particular phone/camera model, but I’ll experiment further and will surely write about it in near future.
Thank you giancarlo great hack m.
You can do something similar on ImageJ with the plug-in depth of field http://bigwww.epfl.ch/demo/edf/ which from what i got use the same principle, except that it doesn’t make a surface in the end you have to extract the data and reconstruct the mesh from it.
This is fun because the guy reminds me and his project too! I made something really similar in 2001 (12 years ago… omg!) you can see screenshots here http://www.autistici.org/darko/dmimages/fage.jpg
http://www.autistici.org/darko/dmscreenshots.php
OMG! XD