
Embedded C developers shy away from C++ out of concern for performance. The class construct is one of their main concerns. My previous article Code Craft – Embedding C++: Classes explored whether classes cause code bloat. There was little or no bloat and what is there assures that initialization occurs.
Using classes, and C++ overall, is advantageous because it produces cleaner looking code, in part, by organizing data and the operations on the data into one programming structure. This simple use of classes isn’t the raison d’etre for them but to provide inheritance, or more specifically polymorphism, (from Greek polys, “many, much” and morphē, “form, shape”).
Skeptics feel inheritance simply must introduce nasty increases in timing. Here I once more bravely assert that no such increases occur, and will offer side-by-side comparison as proof.
Inheritance
The form of polymorphism by inheritance used by C++ is subtyping. As mentioned last time, we’re creating user defined types (UDT) that are treated by the compiler just like the standard language types. A subtype inherits the characteristics of its parent type and can use, or not, the member functions of the parent. You’ll see this relationship referred to in a number of ways: parent / child, super class / sub class, etc.
Let’s look at the C++ code used to test the timing to walk through inheritance and virtual functions. The parent is the class PinOutputAbstract. It represents an output pin on an Arduino:
class PinOutputAbstract {
public:
PinOutputAbstract(const unsigned int pin) :
mPinNum { pin } {
pinMode(mPinNum, OUTPUT);
}
virtual ~PinOutputAbstract() { }
virtual void output() const = 0;
static void outputPins();
protected:
const unsigned int mPinNum;
static PinOutputAbstract* mOutpuDevices[];
static const size_t mOutDevicesCnt;
};
using PinPtr = PinOutputAbstract*;
There is one datum needed by the class, the number of the pin number being accessed: mPinNum. It follows the protected keyword which determines who can access that datum. A protected class member can be accessed by subtypes but not by users of the class. In effect it is public for subtype but private for users. The value of mPinNum is not going to change during the use of the class so it is set to const which means it must be initialized by the constructor, PinOutputAbstract, which receives the value as a parameter. The initialization is handled by the expression following the constructors name and parameter list: ‘: mPinNum(pin)'. The body of the constructor then initializes the pin as an output.
After the constructor is the destructor and it is declared as virtual. This class doesn’t really need a destructor since there aren’t any resources or dynamic memory that need to be deallocated. But it is a common mistake to forget the destructor, especially when using virtual functions, so the compiler nags you to include it.
The virtual function we’re interested in is output(). The const following it indicates it is not changing any members inside the class. This allows the compiler to perform optimizations and generate errors should a future modification to the function attempt to change members.
In addition, output() is declared pure virtual by the '=0' following the const. Such a function does not need to have a body although it can. It makes PinOutputAbstract an abstract class, hence the name, which cannot be instantiated. This is close to being an interface, as used in other languages, except an abstract class in C++ can have members with bodies of code.
The static members we’ll discuss later since they are not directly involved with inheritance.
We’re now going to look at two subtypes: DigitalOut and AnalogOut. The original Arduino’s do not have true digital to analog outputs (DAC) but this is faked using pulse width modulation (PWM) on a digital output pin. PWM varies a pin’s time on and off which generates a variable voltage on the pin. Our classes represent the pure binary output and the PWM output capabilities of the Arduino. The DigitalOut class toggles its pin on and off with each call just to make things interesting.
Here is the binary digital output class:
class DigitalOut: public PinOutputAbstract {
public:
DigitalOut(const unsigned char pin) :
PinOutputAbstract(pin) {
}
virtual ~DigitalOut() { }
virtual void output() const;
};
The inheritance relationship is declared on the first line with ': public PinOutputAbstract'. This states that DigitalOut publicly inherits from PinOutputAbstract. There are also private and protected inheritance but those are details for you to study on your own. Public inheritance allows the child to access the parent’s public members.
The constructor follows the public declaration and initializes its parent with the pin number passed as a parameter. Again there is a virtual destructor with an empty body to keep the compiler happy. And finally, the output() method declaration. This declaration must be exactly the same as the one in the parent.
The AnalogOut class declaration is identical except for the class name:
class AnalogOut: public PinOutputAbstract {
public:
AnalogOut(const int pin) : PinOutputAbstract(pin) { }
virtual ~AnalogOut() { }
virtual void output() const;
};
The implementation of the two members is straightforward:
void DigitalOut::output() const {
digitalWrite(mPinNum, !digitalRead(mPinNum));
}
void AnalogOut::output() const {
analogWrite(mPinNum, 100);
}
Usage
Virtual member functions can be invoked just the same as non-virtual functions:
AnalogOut ao(11); AnalogOut* ao_ptr; ao.output(); ao_ptr->output();
Where it gets interesting is this usage from the actual code:
DigitalOut pin13(13);
AnalogOut pin11(11);
PinPtr PinOutputAbstract::mOutpuDevices[] { &pin13, &pin11, &pin13, &pin11, &pin13, &pin11, &pin13, &pin11, &pin13, &pin11, };
PinPtr pin13_ptr = &pin13;
void PinOutputAbstract::outputPins() {
for (auto p : mOutpuDevices) { // C++11
p->output();
}
}
The array mOutpuDevices is declared to contain pointers to the PinOutputAbstract class, the parent. But the array elements are pointers to instances of child classes. This is a feature of inheritance and is very powerful. It means you can work with collections of instances without knowing their classes. You can invoke any virtual function on those instances.
I used the C++11 initialization using {}s, the range based for loop to step through the array, and auto to allow the compiler to determine the type of the iterator. The C++ range based for makes working with arrays a lot cleaner.
If you look back at the declaration for PinOutputAbstract there were three lines with the keyword static. C++ uses this keyword to say these are members of the class, and not members of instances. They don’t need to be called with the dot or arrow notation. Instead, they are called with the class name and the scoping operator. The member function outputPins() is used during the timing tests. It steps through the array mOutputDevices as we’ve just seen.
Vtables
What is the cost for using virtual functions and why do some feel this is a good reason for not using C++ in embedded systems? Let’s look at a typical implementation by compilers.
Each class with virtual functions has an addition to its data structure which points to a virtual table, or vtable. The vtable is an array of the addresses of the virtual functions in the class. For our example there would be one entry. Diagrammatically you have:
DigitalOut* -> vtable_ptr -> vtable[0] -> output()
Oh! The horror of all those pointers! The overhead! The overhead!
That in a nutshell is inheritance and virtual functions. This isn’t a tutorial but just a glimpse into this feature of C++. There is a ton of additional information on how to use inheritance effectively, including when not to use it in lieu of other techniques.
Let’s get to the testing to see if C++ really is slower. Of course, it isn’t.
The Test Scenario
The basic processing loop in a non-trivial embedded system is: acquire data, perform processing, emit output. You need a consistent snapshot of the environment which means reading all the inputs at one time. All output needs to be done at one time so changes are made simultaneously.
One approach is to create a list of input devices and read all their data at once. Similarly, create a list of the output devices and walk the list when doing the output.
That’s what we’ll do for this scenario, using the classes defined above, and their C code equivalent, shown below. This is a bit of overkill for the Arduion Uno since it only has 14 digital pins. But consider handling the 54 pins of the Due or additional daughter boards which expand the IO capability greatly.
I used the LED pin 13 as the digital output and pin 11 as the analog output. Pin 13 is toggled every pass. The analog output is set to a fixed value, although it is different for C and C++ so I could tell everything was working using my new toy, a Rigol o-scope, to check the output.
These routines were kept simple to take just a small amount of time since our interest is in the timing of the calls, not the processing. We’ve seen the pertinent parts of the C++ code so lets look at the C version.
C Implementation
The C implementation uses a data structure and requires a few functions. The code is:
enum PinType {
eToggle, eAnalog
};
struct PinOut {
enum PinType pin_type;
const unsigned int pin;
};
typedef const struct PinOut* const PinOutPtr;
void toggle_out(const PinOutPtr p);
void analog_out(const PinOutPtr p);
void output_all();
void output_by_func();
void output_pin(const unsigned int i);
The PinOut structure contains an identifier, PinType, to identify the type of output, digital or analog. It also contains the pin to use. The functions toggle_out() and analog_out() are called to control the pin specified by the PinOut structure which is passed via a pointer. The other functions are used in the list processing and are discussed below.
Timing
The timing process is simple. The micros() function is used to capture the time before and after each method of invocation. The difference between those times is how long it takes to perform the operation. Each operation is performed 10,000 times. Timing just a single operations, being they are so fast, would be inaccurate.
There were two general tests. The first is timing the call of a single output routine. This provides a feel for what each invocation costs but, while interesting, the results are a bit misleading. The second test uses the array process discussed above. This is a more realistic result.
Timing Simple Calls
There are three tests performed calling a single output function. One test is calling the C toggle_out(). The other two are calling the C++ digital output() using the dot-notation direct call and a virtual call through a base class pointer variable.
The actual invocations in each timing loop are:
toggle_out (pin_out_ptr); pin13.output(); pin13_ptr->output();
The variable pin_out_ptr is a pointer to the C data structure for pin 13.
The variable pin13 is an instance of the DigitalOut class for pin 13. Variable pin13_ptr is a PinOutputAbstract pointer containing a pointer to pin13.
Walking Lists
This more complex test is to call both output functions multiple times walking an array of ‘pins’ for both implementations. The C list is an array of PinOut pointers. The C++ version is an array of PinOutputAbstract pointers to instances of DigtalOut and AnalogOut. Each array contains ten elements.
C++ Implementation
The C++ implementation is simple, which is the advantage of using inheritance. C++ works to put details onto the class developer to make the class user’s job easier. C spreads this more equally between the two roles. In small projects this doesn’t make much difference. Considering today’s development teams, the class developer may be on a different continent than the user. Making it easy on the user has big benefits.
All it takes to implement that pass through the array is a loop making a virtual call to output() for each entry. We saw it above using the new C++11 range based for loop.
C Implementation
The C implementation tests two ways of walking the array of output devices. The first uses a switch-case structure to decided if the output is analog or digital. The second is for those experienced enough to work with function pointers. This avoids the decision process at the expense of more complex implementation.
C++ does not need to make a decision because it is inherent in the class being used for the device. Similarly, the call to the virtual function is handled by the compiler so the code is simpler than calls through C function pointers.
Switch-Case Decision
Here is the code for output_all which is used to walk the array and call the output_pin() function:
void output_all() {
size_t i;
for (i = 0; i < io_Pins_size; i++) {
output_pin(i);
}
}
Here is output_pin() which contains the switch-case statement:
void output_pin(const unsigned int i) {
PinOutPtr p = io_pins[i];
switch (p->pin_type) {
case eToggle:
toggle_out(p);
break;
case eAnalog:
analog_out(p);
break;
default:
break;
}
}
This is straightforward. The type of output is obtained from the array entry and used by the switch to determine the case to use.
Function Pointer Implementation
For those experienced enough to tackle this problem using pointers to functions here is the code used:
void output_by_func() {
size_t i;
for (i = 0; i < io_Pins_size; i++) {
PinOutPtr p = io_pins[i];
func_ptrs[p->pin_type](p);
}
}
This version has the advantage of just requiring one function, func_ptrs(). The overall drawback to this is the challenge of creating the function to the pointer.
Results Discussion
Here are the timing results: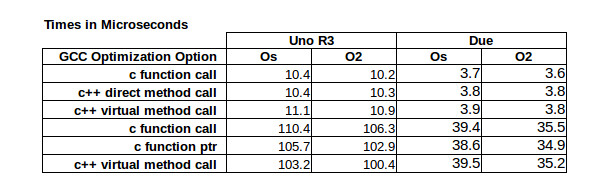 I used the same development environment from the last article, as described in Code Craft: Using Eclipse For Arduino Development. The timing in the table is from an Arduino Uno R3 and a Due. The tests were done with two optimization levels to see how they impacted the results. The Os is the default for Arduino and is optimizing for space. Optimization O2 is for speed, without getting into any unusual tricks. This is the level the GCC documentation recommends for general speed optimization. There are two higher levels if you want to experiment. I’ll also mention that memory use increases when speed optimization increases. This is a typical tradeoff.
I used the same development environment from the last article, as described in Code Craft: Using Eclipse For Arduino Development. The timing in the table is from an Arduino Uno R3 and a Due. The tests were done with two optimization levels to see how they impacted the results. The Os is the default for Arduino and is optimizing for space. Optimization O2 is for speed, without getting into any unusual tricks. This is the level the GCC documentation recommends for general speed optimization. There are two higher levels if you want to experiment. I’ll also mention that memory use increases when speed optimization increases. This is a typical tradeoff.
The results for the single calls to functions are as expected. The virtual call is slower by a whole 0.7 microseconds on the Uno. The Due has a faster processor so the difference is smaller. There is little difference between the C function call and the C++ direct member call. The change from Os to O2 optimization did improve the speed for the Uno and Due but only marginally.
The array processing test changes the timings in interesting ways. The C++ virtual method call is faster on the Uno than both the switch-case and the function pointer versions. The additional function call and switch-case case processing took a toll for the Uno. The results for the Due are not very different among the cases, especially for the speed optimized tests.
Wrap Up
There is no clear winner on the timing results since they are all so close. Pragmatically, it doesn’t matter if you use C or C++. That is the point of these two articles: to put to rest the argument that C++ is larger or slower than C. C++ classes do not cause code bloat and using inheritance and virtual functions are not inherently slow.
A key point to consider is you cannot always look at a single language feature in isolation, as the nay-sayers do when looking at function calls. The larger perspective on how and why a language feature is used needs to be considered; you need to look at the ecosystem the language presents. You have to take a specific problem and consider a solution in each language. Even then no comparison is going to be perfect.
A design goal of C++ is the expression of the solution in terms of the problem, not in the esoterica of the language. One example we’ve seen is that C++ pushes implementation details into classes and inheritance so the expression of their use is cleaner. For instance, the loop for the virtual function processing is much easier to read than the one for the C function pointers. Similarly, in the classes article calling a member with a reference parameter is cleaner than the C function where the users has to add the address operator.
The Embedding C++ Project
Over at Hackaday.io, I’ve created an Embedding C++project. The project will maintain a list of these articles in the project description as a form of Table of Contents. Each article will have a project log entry for additional discussion. Those interested can delve deeper into the topics, raise questions, and share additional findings.
The project also will serve as a place for supplementary material from myself or collaborators. For instance, someone might want to take the code and report the results for other Arduino boards or even other embedded systems. Stop by and see what’s happening.













Hi, nice write up. Two things that are important to know with respect to virtual calls:
Link time optimization (LTO) is present in newer versions of most compilers, and enables optimization a across object files. This can help improve embedded performance even further!
Combined with newer support for devirtualization, this can drop the cost of virtual function calls to zero in cases where the compiler can prove a variable is a particular type.
That is to say, try compiling with -O3 -flto
Are these really the issues embedded engineers are worried about when it comes to C++, though? I’d say the real risks are in unexpected operations, hidden allocation, non-linear execution and side effects – copy constructors being a great example where all these risks collide. This can be particularly woe inducing if one makes the mistake of using and subsequently upgrading a third party library.
The very point of C++ is to build a higher level environment by building abstractions to keep these details out of mind, but in doing so it resists both the sort of deterministic static analysis required for real time development, and increases code complexity to the point where it becomes difficult to keep an entire system in one person’s head.
C is basically a rubbish portable macro assembler, but in this case, it’s assorted flaws come together, and miraculously almost cancel each other out: if the code’s complex and unreadable, it’s because it’s doing something ugly and hard.
C is for people who work on low level stuff like drivers where a support library suite is minimalistic. C++ was originally a pre-parser to make high level abstraction possible. In most cases, running C through the g++ compiler can force inexperienced C coders to follow cleaner style guidelines.
Those who regularly use the C++ STL or Boost correctly will save time on most types of projects, but the power of design patterns is meaningless if after 15 stacks deep the architecture throws a HACF. The opposite can also be true, as CUDA development libs used to deallocate in a way that made C programs seg-fault on exit.
Most inexperienced people don’t understand when each language is appropriate, and indeed just about any language is inappropriate under some circumstances.
I agree. The problem with the examples is that they are fighting strawman arguments. The issue with “C++ bloat” is not about whether or not one extra level of indirection on a function call is a problem (even though even that can add up if it is an loop and you are doing many such operations – e.g. matrix algebra).
The problems start the moment higher level abstractions and constructs are used – e.g. deep class hierarchies, dynamic allocation, STL, etc. – basically the meat and bones of C++. Without that it is only C with some syntactic sugar to make things nicer. Which can certainly be useful, but shouldn’t be the basis to make claims about performance of C++ vs C.
If you need a dynamic array in your application, it does not make a performance difference if you code it in C or C++, but the C++ version is going to be a lot cleaner and more typesafe. You can use a template to determine the stored type instead of relying on `void*` which can lead to corrupted memory, something that can be extremely hard to debug on an embedded target.
For some (non STL compliant) container implementations for microcontrollers, you can have a look here: https://github.com/roboterclubaachen/xpcc/tree/38c8fb74d787dda3f6562f521089e2bd5665b515/src/xpcc/container
Another excellent C++ article… thank you Rud, and keep up the great work! I am always excited when I see another article in this series.
Nice article Rud. As interesting as the previous one about C++. What is missing in your table in this article is code size, now that you’re using polymorphism and virtual functions… Any numbers for those?
This code is all in one executable so pulling out the code sizes is a challenge. Once the Serial library is brought in the code size is pretty meaningless.
“C++ classes do not cause code bloat and using inheritance and virtual functions are not inherently slow.”
I completely agree. What’s slowing this example down isn’t C++, or C: it’s the abstraction in general. Obviously the fastest way to do this wouldn’t be to have a list of pins at all, and just do the toggle_out/analog_out calls directly. And the speed-ups there can get *very* large if the compiler gets smart enough to inline things, and you end up basically avoiding all function overhead entirely.
The thing is, if you declare things correctly (and if things are const), the compiler, in theory, could be smart enough to inline *everything* and avoid everything. But they’re not.
That is, declare mOutpuDevices const. mPinNum is already const, so those entire operations in the loop are completely predictable. It should just be able to resolve all of the virtual function lookups, and unroll the loop entirely. For zero cost. As far as I can tell, though, C++ compilers don’t do that. (I think with templating you *might* be able to encourage them to do that, but, I have no idea)
Are you suggesting an article on loop unrolling using template metaprogramming? That would blow minds. The approach would also increase the code size.
“Are you suggesting an article on loop unrolling using template metaprogramming?”
No, I’m saying I wish compilers could recognize that if they could pre-resolve vtable pointers after loop unrolling and inline the resulting functions, it’d be super-awesome. There’s no reason they *can’t* in the setup that you’re using – if you would do something more clever with ‘mOutpuDevices’, at least.
In order to do it yourself, you’d need something like a helper variadic template to do the loops. You can do it, and it’d almost certainly be ideal in terms of code size/speed.
“The approach would also increase the code size.”
I doubt it, actually. You save so much from the call/return overhead as well as including the loop overhead on simple functions that a lot of times it ends up being smaller. You can reuse the unrolled loop by shoving it in a function itself.
But more importantly, you can fix code size by getting a larger microcontroller. Most of the time you can’t get a faster one in the same architecture.
The Kvasir library actually allows you to group pins in a template and to automatically generate optimal code to activate them. At least that’s what the author told me: https://github.com/kvasir-io/Kvasir
Neat. Also heavy use of CRTP programming there, which makes total sense. I’m not a huge fan of template programming, but because of the way C++ works, it’s really the only way to avoid stupid overhead.
I actually coded up a version of the Wiring interface that moved all the pin declarations into a template parameter, as most of the time that you are using digitalWrite, you are writing to a specific pin, known at compile time. This made digitalWrite a heck of a lot faster for bit-banging because a lot of the unnecessary run-time code gets elided by the optimizer. I’m quite certain that if I had taken it to the logical extreme by metaprogramming the heck out of it, I could have gotten the run-time down to something quite comparable to the minimum possible using C without Wiring, when starting with the same interface contract.
That last point is kind of crucial. In digitalWrite, the side effects/interrupt consequences of what I’m doing are handled by the library (although bitwise port operations are available in some micros, which avoids this). So if I want to continue to use an interface as abstract as digitalWrite, then I kind of have to accept some overhead. But with templates, I can use one version of the function and compile-time parameterize it in a way that avoids banking on compiler intelligence, or only relies on minimal intelligence.
If there is interest, I’ll look at putting that up on Github for public mockery.
I’ve been tempted to look at doing that but hesitated because of the different processor architectures. Is your code just for the Uno equivalent boards or others? I’d like to see the code.
https://github.com/dklipec/AVR/blob/master/avr_test3.cpp
I couldn’t find the original (it was part of some disposable project I wrote a few years ago). So this is a quick rewrite from memory of how it generally worked. Definitely Uno only, but it is pretty clear how it could be extended to provide similar coverage. It would just take a lot of verification effort.
This version is roughly 3x faster than stock digitalWrite, does all the same stuff, but moves “pin” from a function parameter to a template parameter to force the compiler to treat it as a compile-time constant.
so digitalWrite(LED, HIGH);
becomes digitalWrite(HIGH);
Most of the optimization comes from compile-time generation of constant information (offsets, bit assignments).
Interesting. I’ve been working on something similar. Arduino’s DigitalWrite takes more than 50 (!) clock cycles on AVR. With template metaprogramming this can be reduced to the minimum (2 cycles) with the same, easy, syntax. For writes to several pins at the same time, this can even be reduced to (#pins+#separate ports) cycles for a syntax like this:
digitalWrite( led1 | led2 | led3, HIGH); // led1, led2 and led3 may be in different ports.
My code is at https://github.com/DannyHavenith/avr_utilities, and there’s a writeup at http://rurandom.org/justintime/index.php?title=Arduino-like_pin_definitions_in_C%2B%2B
That is some good stuff – pretty much what I was alluding to, only you actually did it.
I will note that (as far as I can tell) your version of digitalWrite isn’t functionally equivalent to Wiring’s digitalWrite. It doesn’t have provisions to change pin state (ie: disable PWM), and doesn’t handle interrupts (an ill-timed interrupt that modifies the same port will cause this to misbehave). You might want to consider how you could add interrupt safety to this.
@David: replying to my own comment, since I can’t reply to yours. You’re absolutely right, Wiring’s digitalWrite() also checks to see if pwm needs to be disabled.
About your second point: To my mind interrupt safety for pin-setting this isn’t worth the clock ticks in the general case. The templated digitalWrite produces code that is equivalent to the “C-style” code ( PORTX |= 0x03). This is indeed read-modify-write and could therefore suffer from interference by interrupts if they write to the same port (not sure about the one-bit case, since this generates a single SBI instruction on gcc).
I think that not changing the interrupt mask is better than what Arduino’s digitalWrite seems to be doing, which is disabling interrupts and not restoring them after the operation.
Having said (written) that, I now realize that it would be possible to create a safe_set() function that would, at the cost of extra clock ticks block interrupts during the write. It would even be possible to only incur the overhead if more than 1 pin is set per port (assuming that SBI behaves atomically).
So, this prompted me to look at the assembler output. To my (modest) surprise, the compiler seems to figure it out and use the sbi/cbi instruction in the C++ version I wrote. I presume it does the same in your library. This means that they are interrupt safe in this build, even without cli/SREG restoring interrupt context.
However, I’d feel better about it if the libraries were explicit about that being a requirement (with inline assembler), as a debug build or arbitrary discretion of the compiler could make it unsafe.
That’s doing exactly what I’d have asked for Rud and I like the use of an oscilloscope to time the loops, but I’m quickly getting lost in terms so the bulk of the article just isn’t accessible to me.
I would say that one persons “Cleaner looking code” is another persons “Sweeping functionality under the carpet” :)
More non-scientific promotion of C++. Almost anyone can find a way to prove something when that is their intention; it’s called confirmation bias.
On the AVR virtual functions are a big performance hit. They are hard to inline; only the latest versions of gcc have included devirtualization optimizations to do this. They significantly increase register pressure, as they use icall which only works with the 16bit Z register.
Now that’s a good comment!
People often forget that architecture makes a big difference. Which may explain some small amount of the language argument.
Additionally, AVRs are quite small, so the penalties could bite even harder.
Yes, but the same issues are seen on AVR with C when calling via a function pointer. C++ doesn’t change that (or force you to use virtual – it does make it easier though).
It is a nice plus that newer C++ compilers can optimize out virtuals in some cases. I wonder if C function pointer overhead can be similarly optimized out by these compilers?
Also, are benchmarks or language comparisons ever “scientific”? Seems to me you can’t get too much closer to a “black art” in constructing them and then interpreting the results. :-)
Exactly why I included the use of C function calls for comparison. I didn’t originally because I consider them an advanced use of C that most hacker level developers would avoid. But a comment by a reviewer of an early version of the article brought it up so I added it in. I was surprised to see the Atmel on the Uno did virtuals faster than the pointer to function calls.
Right on. I think you did a commendable job at getting an “apples to apples” comparison.
I did also notice the slight “win” for C++ virtuals vs C function pointers. Interesting, and (for me) unexpected. I have a few ideas why this might be the case, but it makes me want to look closer at the details.
Hmmm well look at the data. The UNO is an AVR. I think the key is Rud’s making an apple to apple comparison (or as close to it as he can get). Sure, if I take my RTOS and write C++ code that does a red/black tree on some sensor data as a bunch of polymorphic objects with virtual functions it is going to be slower than a C LED blinker. That’s just life.
I had a coder on a previous job tell me that C++ just “does things” as though those things are not knowable. That’s just not true. Everything in C++ can be done in C (in fact, CFRONT just converted C++ to C; so does http://www.comeaucomputing.com/ — so there’s no magic sauce in C++. I won’t assert that you can’t write something the compiler would do better than the compiler in C. There’s bound to be cases. But I bet in most cases, you will only do as well and maybe not as good as the compiler/library.
Humans CAN write better code than compiler. But that doesn’t follow that humans MUST write better code than compilers. My experience is, they generally don’t.
So while I also try to look out for confirmation bias, what I see is Rud has data and I don’t see anything wrong with his methodology. So where’s the counter data?
Speaking of confirmation bias, try this: http://www.nytimes.com/interactive/2015/07/03/upshot/a-quick-puzzle-to-test-your-problem-solving.html — I think that’s a great puzzle.
Rud “bravely assert” that inheritance doesn’t cause increases in timing. He then goes on to show how virtual function calls perform essentially the same as function pointers. You can call that apples to apples, but it’s not proving the point he set out to prove.
Good C programmers can write clean code without using inheritance. What’s good about C++ is not that it is easy to attain the performance of C, but that it is easy to put constraints on the way code is written so that even mediocre coders can write maintainable code.
To get good performance and code size from C++ in embedded systems, virtual functions should be avoided, and static singleton-style classes should be used where possible. Wiring/Arduino has lots of examples of how NOT to code in C++ with embedded systems. One example is the Serial class. On the mega8/168/328 there is only one UART, but the Serial class is written to support multiple instances for devices that have multiple UARTs. I stripped it down so there were no virtual functions, and was able to keep enough functionality so most sketches still work as intended, but compile to as little as half the code size.
http://nerdralph.blogspot.ca/2015/10/beta-picowiring-arduino-compatible.html
And I’m not impressed with the article. I stopped on the first page due to the false presumption “no one likes to be wrong”. I like being right more than I like being wrong, but I still like being wrong. I understand that lots of humans that are primarily driven by their limbic system have an emotional attachment to the feeling of being right. However there’s still lots of us that work on logic and realize you acquire knowledge when experiment shows your theory to be correct or if it shows your theory to be incorrect.
Is there a typo in the first example – line 4?
mPinNum(pin) instead of mPinNum { pin }
That is not a typo. It’s the form of initialization introduced with C++ 11.
One of my favorite e-mail signature lines (forget who had it) was:
I saw cout being shifted left by “Hello World” bit positions and I got the $*#& out of there!
Virtual functions are one of the C++ features that I will not use on an MCU along with exceptions, RTTI and anything else that requires runtime support that’s invisible at compile time. The problem with virtual functions is not the pointer indirection it’s the fact that all vtables are copied out of your copious flash into your much more constrained SRAM at program startup time taking a chunk out of your most precious and scarce resource. It’s disingenuous to promote the use of a language feature like this without placing all information onto the table so that the less experienced can make an informed choice.
Agree, the article is incomplete without at least a mention of the ROM/RAM resource overhead of virtual function table and pointer. It can result in significant overhead on small MCUs esp the 2KB RAM AVRs being discussed here
This is all fine and nice, but it’s still bloated compared to java.
the fastest, smallest implementation, would be a java executable, running on a java interpreter written in java, running on a java interpreter written in java.
Unlike C or C++, the more abstraction, the more speed!
java’s hotspot and memory management technology make all the code run faster.
My main concern is RAM and not run time, specially if you are already using the slow “digitalWrite” which is full of indirection.
VMT might be nice, sometimes necessary, but extensive usage can lead to some problems.
Just creating a pin instance: DigitalOut pin1(1); will consume 4 byte ram, using 4 full ports will consume 128 byte and we haven’t even done anything. (Haven’t toughed, referenced the pin, -Os opt, maybe something is broken. Atmel Studio 7…)
Maybe we add a virtual int input() const = 0; to PinAbstract because we also want input not just output and want to use analogRead. Then add a couple other virtual methods and we start to run out of memory without having done anything with the pins…
When you write low resource low level stuff using C you have to think like C and not how to implement VMT in C so you can do the same thing you would have done in C++.
The hypothesis was that polymorphism, indirection will consume resources, then you implement the same kind of indirection in C and act surprised that it isn’t faster. Wow…
Just to be clear C++ is better than C, you just don’t have to use everything C++ offers. And you can do magic with templates… (You can accomplish the same thing without using virtual methods and instead of an array using a list, template and loop unrolling… it’s faster and doesn’t waste memory…)
Of course most people don’t care about wasting resources (computer or otherwise) as long as there is enough, who cares…
Just want to point out that you should compare % and not absolute difference.
Going from 10ms to 11ms is “just” 1ms more, but it’s actually 10% increase.