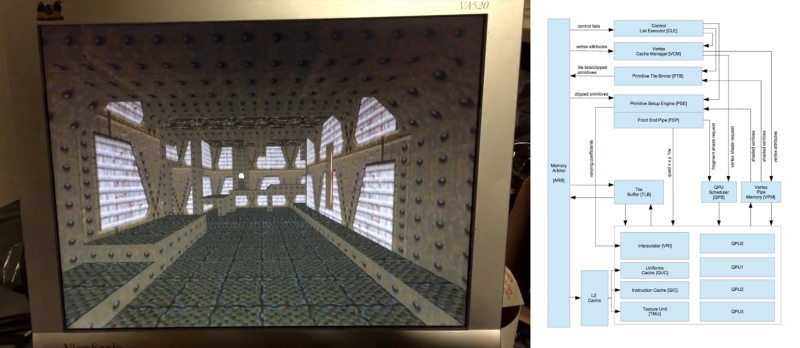
Researchers at Binghamton University have built their own graphics processor unit (GPU) that can be flashed into an FGPA. While “graphics” is in the name, this GPU design aims to provide a general-purpose computing peripheral, a GPGPU testbed. Of course, that doesn’t mean that you can’t play Quake (slowly) on it.
The Binghamton crew’s design is not only open, but easily modifiable. It’s a GPGPU where you not only know what’s going on inside the silicon, but also have open-source drivers and interfaces. As Prof. [Timothy Miller] says,
It was bad for the open-source community that GPU manufacturers had all decided to keep their chip specifications secret. That prevented open source developers from writing software that could utilize that hardware. With contributions from the ‘open hardware’ community, we can incorporate more creative ideas and produce an increasingly better tool.
That’s where you come in. [Jeff Bush], a member of the team, has a great blog with a detailed walk-through of a known GPU design. All of the Verilog and C++ code is up on [Jeff]’s GitHub, including documentation.
If you’re interested in the deep magic that goes on inside GPUs, here’s a great way to peek inside the black box.













“It was bad for the open-source community that GPU manufacturers had all decided to keep their chip specifications secret. That prevented open source developers from writing software that could utilize that hardware.”
I wonder what these documents are then: http://xorg.freedesktop.org/wiki/RadeonFeature/#index12h2
I think Mesa is doing wonderful job utilising graphics hardware.
Note the use of past tense. NVIDIA and VIA (if you still count them) are the last holdouts.
Those documents are essentially header files for the secret sauce that is on the cards–the actual good stuff (both the firmware on the card and all of the implementation details) are kept secret. There are a few cards (mostly very old and low powered stuff, I do not know if any that offer 3d acceleration of any kind) which have published specs which allow you to run your own firmware, but as far as I know there are no commercially available cards which offer open hardware level support. Even the soft GPU designs (available for license from ARM and the likes) are proprietary and come with binary blobs for the hardware and firmware.
I don’t know about calling them the secret sauce. A GPU isn’t really all that different from any other processor, in order to do anything useful it needs to read and write memory. Anyone that works with graphics code enough learns that 3D acceleration is essentially a very fast vector library with sorting algorithms. It is nice to see some of the techniques to achieve that fast of vector math.
Tms34010 the grandaddy of all gpgpus…. Probably a good place to start very well documented ISA and some architectural documentation is easy to Google up. There is an ancient version of GCC floating around archive.org for it too I think.
You could even gang several of them together at least 4 probably more. Used in alot of high end graphics cards in the early 90s as well as printer raster engines and notably the scuzzygraph Mac scsi graphics adapter.
only Official Operating Systems such as Windows should have access to the true hardware. Open-sores software like Linux might damage it, that is why they don’t want to provide the hardware specifications. Open-sores software runs just fine enough in a virtual machine, especially since it’s not useful for real work.
Sarcasm aside, the real problem was that open source devs pretty much refused to implement a nice stable interface for closed source drivers in order to -force- manufacturers to open their drivers and release all the secret sauce to every tom, dick and harry (and Chinese copycat companies), so the manufacturers basically ignored them.
The other problem was that things like X.org simply didn’t have the facilities and functionality to use the features of a modern graphics card, such as memory management, because the whole thing was still treating the GPU like it was a stupid “accelerator” card that simply implements specific OpenGL calls in hardware.
Plz, help bill my compy has more then 640k. What do?!?!?
Timothy Miller sounds familiar. I wonder if it is the same guy that started the Open Graphics Project. Seems likely, I guess!
http://p2pfoundation.net/Open_Graphics_Project
It’s rather difficult to find out what happened to that project, the relevant sites seem to be no longer available.
Francis Bruno’s kickstarter didn’t even get that far:
https://www.kickstarter.com/projects/725991125/open-source-graphics-processor-gpu.
Lack of interest notwithstanding, the red flag for me was the bit about “capable of OpenGL and D3D”. As is often the case with things like this the hardware design and exorbitant licensing fees are the the easy bit, it’s the navigating of the political and legal minefields where projects like this become unstuck.
At least he open sourced it anyway it’s up on github as gplgpu
FGPA?
Friggen Giant Plastic Artifact.
Frogs Groping Pussies Attentively.
Verilog Sigh … VHDL here!
On a side …
When 256 colors first came out (after 16 colors) I wrote a simple render to render a shaded and colored sphere.
I found it much much faster to map the screen to the sphere instead of mapping the sphere to the screen. ie what area does this pixel cover in the simulated environment and what’s the average color.
Is there a reason that this isn’t done today.
Congratulations, you just invented ray tracing.
ok, so it is “a thing” now lol. My code was in the late 80’s (from memory) but I am sure someone else did it before me.
It’s okay. Spacewar wouldn’t have become an arcade classic anyway. Model was to take the quarter and engage the player. What could you do if two players figured out how to infinitely travel around an synchronize orbit without a shot. Don’t forget best strategy for Asteroids was full throttle diagonally and fire. But they figured out make shots slower then the ship.
check out shadertoy some time
Dont get excited, this is purely academic project. Main goal is learning, not end product.
there is no quake and no play, that screenshot is few borrowed textures running in custom engine rendering ONE ROOM at <1 fps on 50MHz vector processor
For comparison I did something similar in ~1996, wrote lame assembler/pascal engine rendering T shaped corridor with quake textures, it ran 1-5 fps on 386DX40.
Man, tough crowd. :) A few clarifications:
– It’s not an academic project. It’s a spare time project I’ve been working on. I collaborated with some academics to publish a paper that performs some experiments based on it (the press release is a bit poorly worded). But it’s open source and available on github so anyone can play with it, instrument it, profile it, and improve it.
– It’s not just one room, it’s doing a BSP traversal and rendering the entire level, as I discuss in the blog post. The quake viewer program is also using a general purpose renderer library that supports pluggable vertex and pixel shaders, z-buffering, and scales to multiple cores https://github.com/jbush001/NyuziProcessor/tree/master/software/libs/librender
http://latchup.blogspot.com/2015/02/improved-3d-engine-profile.html. It’s reference code quality right now, but the point of it was more to demonstrate that the hardware could run non-trivial programs and give a baseline for performance characterization.
I think you have done a sterling job!
rasz_pl is too smart and cool for everything.
I’m not. Thanks for sharing the project!
Im not trying to shit on your project, just bring HaD writeup back to reality.
Its academic by most definitions, as evidenced by papers you mention :) btw I like how university announcement makes you a distant co author who somewhat helped brave prof and his team in bringing this great innovation into the world :P
I frickin love your whole blog, but Imo trying to demo GPU by running whole engine was a mistake.
Your demo might be operating on whole level, but It still doesnt make it “play Quake”. I imagine it only gets worse once you leave e1m1 spawn area (staircase = 0.2 fps?). 486DX 33mhz actually runs quake, and renders most of that level at >4 fps (at 1/4 resolution). Badly pipelined(actually used in courses to teach how not to implement pipelining) non superscalar 33mhz cpu does better than this demo :( This is the kind of demo that would be impressive on poor ancient Atari falcon (16MHz + 33mhz fixed point dsp), like this https://www.youtube.com/watch?v=WpwlZgQPCpk
Your original idea of implementing some king of minigl library (immediate/arrays/streaming) was much better. You could bridge your fpga board with pc over usb (EZ-USB FX2LP) or even ethernet. It had a chance of demonstrating quantitative performance and showing something impressive like for example being on par with first Voodoo/riva128 cards.
3DFX Voodoo ran at 50MHz, showing you can do better than the grand daddy of GPUs would nicely validate merits of this project. Talking about stalls, register renaming and caches while showing 1fps is academic :(
The frame rate is fairly consistent across the levels. Most of the workload is pixel rendering. The combination of BSP/PVS in the Quake levels reduces overdraw significantly, so the number of pixels to render isn’t highly variable.
The Quake renderer is a bit distracting for people. The reason I originally built it was because the level files are readily available and it is well documented. But it inevitably invites comparisons to lower end processors that aren’t always appropriate. The software renderers take a lot of shortcuts. For example, the original Quake engine didn’t do perspective correct texturing, but fixed the perspective every 16 pixels. The demo you linked is fairly low resolution and doesn’t seem to be doing bilinear filtering. I tried to implement something that behaves like a modern GPU with real shaders. It works in floating point and is more flexible. It’s design focuses more on scaling up than down. I’m not trying to make excuses–there’s a ton of room of improvement. But I don’t think it makes sense to compare them directly.
Re running the whole engine: the amount of overhead to set up the scene and take input is basically lost in the noise compared to rendering itself. A split architecture is interesting, but that would be much more complex and would add IPC overhead. I’m also intrigued by the idea of a hybrid model where everything runs on one processor. There are lots of other highly parallel, non-graphical tasks that a game engine needs to execute like AI and physics.
Finally, I disagree that profiling and looking at low level performance is “academic.” I’m not sure how else I would figure out how where to optimize it. If you’ve read Michael Abrash’s articles, he spends lots of time talking about low level details like instruction pairing. If an instruction is executed millions of times, shaving a few cycles off can add up to a big difference. Most projects don’t start out high performance. Abrash and Carmack spent two years optimizing the Quake engine, and the account of all of the approaches they tried is fascinating (http://www.jagregory.com/abrash-black-book/#chapter-64-quakes-visible-surface-determination).
Well. This could be useful.
It’s going to need a lot of work before if can compete with the gaming crap down at best buy, but graphics hardware has been a longtime sticking point with attempts at a ‘fully-open’ computer, with both open source hardware and software.
What’s this gaming crap at best buy?