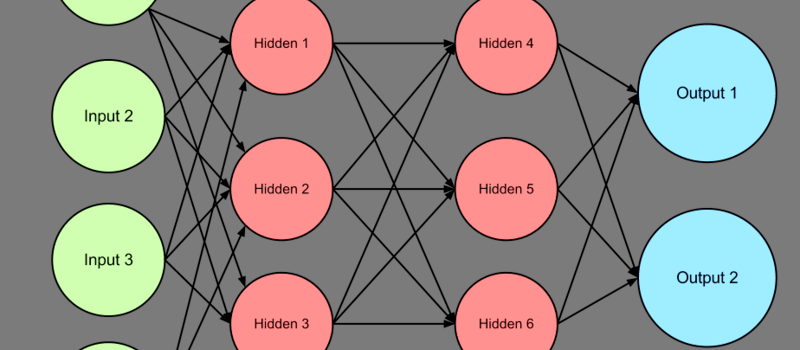
When you want a person to do something, you train them. When you want a computer to do something, you program it. However, there are ways to make computers learn, at least in some situations. One technique that makes this possible is the perceptron learning algorithm. A perceptron is a computer simulation of a nerve, and there are various ways to change the perceptron’s behavior based on either example data or a method to determine how good (or bad) some outcome is.
What’s a Perceptron?
I’m no biologist, but apparently a neuron has a bunch of inputs and if the level of those inputs gets to a certain level, the neuron “fires” which means it stimulates the input of another neuron further down the line. Not all inputs are created equally: in the mathematical model of them, they have different weighting. Input A might be on a hair trigger, while it might take inputs B and C on together to wake up the neuron in question.
It is simple enough to model such a thing mathematically and implement it using a computer program. Let’s consider a perceptron that works like a two-input AND gate. The two inputs can be either 0 or 1. The perceptron will have two weights, one for each input, called W0 and W1. Let’s consider the inputs as X0 and X1. The value of the perceptron (V) is then V=X0*W0+X1*W1 (edit: there was a typo in this equation, now fixed). Simple, right? There is also a threshold value. If the output value meets or exceeds the threshold, the output is true (corresponding to a neuron firing).
How can this model an AND gate? Suppose you set the threshold value to 1. Then set W0 and W1 both to 0.6. Your truth table now looks like this:
| X1 | X0 | V | Result |
| 0 | 0 | 0*.6+0*.6=0 | 0 |
| 0 | 1 | 0*.6+1*.6=.6 | 0 |
| 1 | 0 | 1*.6+0*.6=.6 | 0 |
| 1 | 1 | 1*.6+1*.6=1.2 | 1 |
If you prefer an OR gate, that’s easy. Just set the weights high enough that it always fires, say 1.1. The value will either be 0, 1.1, or 2.2 and the result is an OR gate.
When It Doesn’t Work
There are two interesting cases where this simple strategy won’t work; we can adopt more complex strategies to fix these cases. First, consider if you wanted a NAND gate. Of course, you could just flip the sense of the threshold. However, if we have any hope of making a system that could learn to be an AND gate, or an OR gate, or a NAND gate, we can’t have special cases like that where we don’t just change the data, we change the algorithm.
So unless you cheat like that, you can’t pick weights that cause 00, 01, and 10 to produce a number over the threshold and then expect 11 to produce a lower number. One simple way to do this is to add a bias to the perceptron’s output. For example, suppose you add 4 to the output of the perceptron (and, remember, adding zero would be the same case as before, so that’s not cheating). Now the weights could be -2 and -2. Then, 00, 01, or 10 will give a value of 4 or 2, both of which exceed the threshold of 1. However, 11 gives a value of zero which is below the threshold.
An easy way to accomplish this is to simply add an input to the perceptron and have it always be a 1. Then you can assign a weight to that input (for example, 0 for the AND gate and 4 for the NAND gate). You don’t have to do it that way, of course, but it makes the code nice and neat since it is just another input.
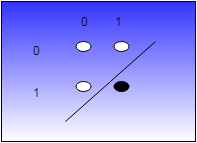 The other problem is that a single perceptrons can only deal with things that are linearly separable. That’s a fancy term, but it is easy to understand. If you plotted the AND gate on a graph, it would look like this.
The other problem is that a single perceptrons can only deal with things that are linearly separable. That’s a fancy term, but it is easy to understand. If you plotted the AND gate on a graph, it would look like this.
The white circles are zeros and the black one is the true output. See the straight line that separates the white from the black? The fact that it is possible to draw that line means the AND gate is linearly separable. Setting the weights effectively defines that line and anything on one side of the line is a zero and on the other side is a one.
What about an exclusive OR (XOR)?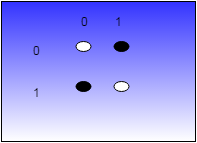 There’s no line on that diagram. Try drawing one. You can’t. That means you can’t create an XOR with a single perceptron. You can, however, use multiple layers of perceptrons to get the desired result.
There’s no line on that diagram. Try drawing one. You can’t. That means you can’t create an XOR with a single perceptron. You can, however, use multiple layers of perceptrons to get the desired result.
When you have more than two inputs, you don’t have a simple 2D chart like you see above. Instead of defining a line, you are defining a plane or hyperplane that cuts everything cleanly. The principle is the same, but it is a lot harder to draw.
Expanding
For a simple binary output like a logic gate, you really only need one perceptron. However, it is common to use perceptrons to determine multiple outputs. For example, you might feed ten perceptrons image data and use each one to recognize a numeral from 0 to 9. Adding more inputs is trivial and — in the example of the number reader — each output corresponds to a separate perceptron.
Even the logic gate perceptrons could use two separate outputs. One output could be for the zero output and the other could be for the one output. That means the zero output would definitely need the bias because it is essentially a NAND gate.
For example, here’s an AND gate with two parallel perceptrons (assuming a threshold of 1):
| Input | Weight for 0 output | Weight for 1 output |
| X0 | -2 | 0.6 |
| X1 | -2 | 0.6 |
| BIAS (1) | 4 | 0 |
Granted, this is less efficient than the first example, but it is more representative of more complex systems. It is easy enough to select the weights for this by hand, but for something complex, it probably won’t be that easy.
An Excel Model
Before you start coding this in your favorite language, it is instructive to model the whole thing in a spreadsheet like Excel. The basic algorithm is easy enough, but it is interesting to be able to quickly experiment with learning parameters and a spreadsheet will help with that.
I put the spreadsheet you can see below on GitHub. The macros control the training, but all the classification logic occurs in the spreadsheet. The Zero macro and the Train macro are just simple functions. The Train1 subroutine, however, implements the training algorithm.
The weights are the 6 blue boxes from B2:C4. Remember, the last row is the bias input which is always one. The inputs are at E2:E3. E5 is the expected result. You an plug it in manually, or you can use a formula which is currently:
=IF(AND(E2,E3),1,0)
You could replace the AND with OR, for example. You can also change the threshold and training rate. Don’t overwrite the result fields or the other items below that in column B. Also, leave the bias input (E4) as a 1. I protected the cells you shouldn’t change (but if you really want to, the password is “hackaday”).
Learning
How does a system like this learn? For the purpose of this example, I’ll assume you have a set of inputs and you know the output you expect for each (the train macro takes care of that). Here’s the basic algorithm:
- Set the inputs to the test case.
- Look at the expected output perceptron. If its output is not over the threshold, add the scaled input (see below) to the weights in the perceptron.
- Look at the other perceptrons. If their outputs are over the threshold, subtract the scaled input to the weights.
- Repeat the process for each test case.
- Keep repeating the entire set of cases until you don’t have to do anything in an entire set for step 2 and 3.
Scaled input means to take the inputs and multiply them by the training rate (usually a number less than 1). Let’s assume the training rate is 0.5 for the example below.
Consider if all the weights start at 0 and the test case is X0=1, X1=1. The “one” perceptron should fire, but its output is zero. So W0=W0+X0*1*0.5 and W1=W1+X1*1*0.5. In other words, both weights in that column will now be 0.5. Don’t forget the bias input which will be W2=W2+1*0.5.
Now look at the other peceptron. It shouldn’t fire and with an output of zero, it is fine so step 3 doesn’t make any changes. You repeat this with the other test cases and keep going until you don’t have to make any changes for step 2 or 3 for an entire pass.
Here’s the code from the Train1 macro:
' Train one item
Sub Train1()
' Put things in sane names
Stim0 = Range("E2")
Stim1 = Range("E3")
Stim2 = Range("E4") ' should always be 1
Bias = Range("F6")
Threshold = Range("F8")
TrainRate = Range("F9")
Res0 = Range("B5") ' save this so it doesn't "move" when we start changing
Res1 = Range("C5")
Expected = Range("B9")
' If we expected 0 but Res0<Threshold then we need to bump it up by the forula
If Expected = 0 Then
If Res0 =Threshod, we need to bump it down
If Res0 >= Threshold Then
Range("B2") = Range("B2") - Stim0 * TrainRate
Range("B3") = Range("B3") - Stim1 * TrainRate
Range("B4") = Range("B4") - Stim2 * TrainRate
End If
End If
' Same logic for expecting a 1 and Res1
If Expected = 1 Then
If Res1 = Threshold Then
Range("C2") = Range("C2") - Stim0 * TrainRate
Range("C3") = Range("C3") - Stim1 * TrainRate
Range("C4") = Range("C4") - Stim2 * TrainRate
End If
End If
End Sub
' Do training until "done"
Sub Train()
Done = False
ct = 0
Do While Not Done
Done = True
ct = ct + 1
If (ct Mod 100) = 0 Then ' In case bad things happen let user exit every 100 passes
If MsgBox("Continue?", vbYesNo) = vbNo Then Exit Sub
End If
For i = 0 To 1
Range("E2") = i
For j = 0 To 1
Range("E3") = j
' We are not done if there is a wrong answer or if the right answer is not over threshold or if the wrong answer is over the threshold
If Range("B8") Range("B9") Or (Range("B5") Range("B6") And Range("B5") >= Range("F8")) Or (Range("C5") Range("B6") And Range("C5") >= Range("F8")) Or (Range("B6") < Range("F8")) Then
Done = False
Train1
End If
Next j
Next i
Loop
End Sub
' Zero out the matrix
Sub Zero()
Range("B2") = 0
Range("B3") = 0
Range("B4") = 0
Range("C2") = 0
Range("c3") = 0
Range("c4") = 0
End Sub
What’s Next?
Experiment with the spreadsheet. Try an OR, NAND, and NOR gate. Try an XOR gate and note that it won’t converge. There are variations on the algorithm to account for how far off the result is, for example. You can also try initializing the weights to random values instead of zero.
Next time, I’ll show you what this looks like in C++ (suitable for your favorite microcontroller) and talk about how to tackle larger problems. If you want to dig into the theory a little more, you might enjoy [Dan Klein’s] lecture in the video below.
(Banner image courtesy this excellent writeup on neural networks.)













Has there ever been a new and updated version of Eliza developed which actually can carry on a conversation, with a bigger vocabulary, and also stay in context ?
The original Eliza was extremely limited, not just for the home computer version but also the MIT version. And the current state of these supposedly “AI” tools such as the Amazon Echo and others are just glorified Butlers — say this and do that. I would think theses RPi’s which are small enough to embed into a robot, would have enough horsepower and maybe install enough vocabulary possible for even today to make them intelligent enough to go beyond the traditional Eliza. And then you could link this with OpenCV to make it more interesting.
ELIZA came from an age where if you wanted to put together an AI, you did it with discrete math like predicate calculus and straight boolean logic and rules and rule solvers. Nowadays, the focus has shifted to less explicitly intelligent models, like clumps of neurons and statistical models that churn through large data pools. These are definitely dumber, but the produce more immediately useful results, especially when fed huge amounts of collected information, like in google’s voice recognition service used in android for searches, or in a lot of internet reverse image search engines (again, like google’s). Back before the AI winter of the 90’s a lot of money went into modeling consciousness with the first approach, but the funding ran out before we got skynet. AI research has had a resurgence recently, but of the dumber, more immediately useful type that drives a lot of cloud services and in which there’s a lot of money to be made. Even watson is an example, being effectively a miniature google search engine and wikipedia combo, with some natural language processing and synthesis, presumably all probabilistic.
Personally, I find all this rather disappointing, but this is how to make money in AI. I don’t think it will lead to very smart “AIs” though, I’ve never really found clever-bot to be very good at holding a conversation either. (and to cut ELIZA some slack, the program is very simple and compact (there’s a version for the arduino) and was written in the mid-1960’s)
“but the funding ran out before we got skynet”
Are you sure that was it, or the fact that nobody could make a satisfactory answer to John Searle’s Chinese Room problem?
The argument points out that a program that manipulates symbols isn’t enough to constitute a mind. The symbols that it manipulates, whatever they may mean externally to someone else, are always meaningless to the program or the machine that runs it because neither is involved in any ways in defining them – the computer is just stupidly following a program, put into it either explicitly by a programmer or implicitly by “learning” according to a program, which is just an indirect way of entering the same program. Without meaning and understanding, we can’t describe what the machine is doing as “thinking” and since it does not think, it does not have a mind, nor is it intelligent. The programmer may be intelligent, yes, but not the program.
The early attempts at AI were attempts to wiggle away from the fact that the machine they were building was simply a very elaborate answering machine – designed to pass the Turing test without actually being intelligent. Searle demanded more “causal powers” from a mind – for the machine itself to be involved in creating and giving meaning to the information it handles on a more fundamental level.
Searle said syntax is insufficient for semantics, and the last 35 years AI researchers have been trying to prove him wrong. None with complete success, although many have faith that reality, or at least brains, can be sufficiently described as a deterministic computation and therefore a computer program must be able to reproduce a mind.
Of course, if you believe in strict determinism like that, words like “mind” or “intelligence” kinda lose meaning. Can something be described intelligent if it’s just following laws, like a rock that is tumbling down a hill due to gravity? If so, then a rock tumbling down a hill is also intelligent. What’s the difference?
https://en.wikipedia.org/wiki/Symbol_grounding_problem
“How are those symbols (e.g., the words in our heads) connected to the things they refer to? It cannot be through the mediation of an external interpreter’s head, because that would lead to an infinite regress, just as looking up the meanings of words in a (unilingual) dictionary of a language that one does not understand would lead to an infinite regress.”
That is the problem of the AI that only manipulates symbols according to a program. Nothing makes sense to it, and nothing you can program into it will make it any wiser. Hence the “skynet” strong AI chatbot is pretty much impossible. It can extract very detailed information about the relationships of symbols (words and sentences), and parrot those relationships back to you, but it will never understand what they mean.
Quote:
#Of course, if you believe in strict determinism like that, words like
#“mind” or “intelligence” kinda lose meaning. Can something be
#described intelligent if it’s just following laws, like a rock that is
#tumbling down a hill due to gravity? If so, then a rock tumbling
#down a hill is also intelligent. What’s the difference?
Quite my way of looking at things… We’re just chemical reactions, Just a very complex (on the macro scale) chemical reaction.
It seems (to me) the laws following are followed…. I call them: accept/reject, react/no-react,etc…
Atoms/molecules with higher potential stealing/accepting atoms/molecules from lower potentials or lowered potentials, i.e. when a higher potential reactant gains an atom to fill the difference and becomes lower than its own previous molecule self it is swimming in thus becomes broken apart (rejected) to reorganize potentials again and again… I’m not certain but one thing that is (not very or likely at all) possible is life could of started from a rock of carbon rolling down a volcano… This sudo-theory amongst million other possible beginnings.
I know… It doesn’t quite work like that.
But if that is how (adaptation theory based) evolution started, “Den I’ll be daym’d!!!”
Personally, I think AI took a wrong turn when they got a boner about machines having no pre-concieved notions and to learn everything from scratch. That’s when they got lazy about embedding basic knowledge in the programming to at least bootstrap the thing to where it can begin to structure data it’s given in a more expert system sense, rather than figure out what something is and what to do with it… What age is it before humans can even really begin to self direct their learning and explore new things on their own, about 8 years old? Before that it’s a crap ton of programming to achieve basic function. Sure they have stimulated learning to handle their visual systems and movement, and speech, getting basic IO up and running, but you’re not going to get them to do meaningful problem solving or anything until they’re older. Most often when we’re talking about what we expect of an AI, as being as smart as a “normal” human, we’re talking about a human adult who’s done high school.
Anyway, some attempts seem like they’re taking a figurative AI toddler, sitting it in front of a stack of university text books and beating it until it learns something.
But on the other hand, the no notions theory, forces concentration on actual ability to learn, the problem being is that then is glazed over when a good enough facsimile of it happens, without being the real thing, and on this foundation of spit and dust another crumbling AI ivory tower is built. So that I think that if it would finally work, it doesn’t really get fundamental enough, where the AI is at a very baby stage and can’t even handle it’s input, but you’d have to persevere with that for months before you knew if you’d actually got anything.
“What age is it before humans can even really begin to self direct their learning and explore new things on their own, about 8 years old?”
I think it’s about the point where they acquire a brain. Babies are shown to learn some language even in the womb, and the cognitive spark of “me” occurs somewhere between 1-2 years old.
@[Dax]
Without getting into determinism because I don’t want to :p
Kids can actually understand speech long before they can talk because they have already developed the intelligence to do so but the features of their mouth and tongue are not yet developed well enough to speak.
They also start to learn the social skills that they will later need in their adult relationships at about 3 years – long before that actually have any concept of adult relationships.
“…more expert system sense, rather than figure out what something is…”
That’s the problem. Pre-loading the program with some symbols and instructions over what to do with them does not give the program any more understanding over what they mean, therefore no mind and no intelligence. It’s still just “If A then B else C” and it never needs to know what A, B or C mean – they’re just arbitrary symbols.
You can for example tell the machine that 1+2=3 but since it has never directly experienced anything concrete involving quantities, it doesn’t know what numbers are. It doesn’t have a first hand experience of three to connect with the symbol “3” – the symbol isn’t grounded in anything. The only thing it knows is how to manipulate and move the symbols around, so it might as well be going apples+oranges=pears. They’re all in the symbolic category of “fruit” after all, just as 1,2,3 are all labeled “numbers”.
And that’s exactly the kind of error these systems fall on, like how Watson tripped over itself by answering “Toronto” to a question about a US city because it found enough loose correlations.
It probably doesn’t matter what reality exactly is made from and whether an AI understands it “correctly”. What matters is that it does the right thing, like we apparently do:
https://www.quantamagazine.org/20160421-the-evolutionary-argument-against-reality/
“””although many have faith that reality, or at least brains, can be sufficiently described as a deterministic computation and therefore a computer program must be able to reproduce a mind.”””
I believe that is the wrong idea and it just leads down an infinitely deep rat-hole of ever more precise simulations burning exponentially more CPU-power with every level of detail added. Clearly, this is not how intelligence is made in nature. All known instances of intelligence relies on sloppy “calculations” using the “computronium” available to it.
Deterministic computation will always give a limited range of behaviors. Even if the number of possible behaviors are very large when compared to the universe the AI has to exist in, they are still are puny and limiting compared to the problem of existing in an infinite universe. To get towards true AI, I believe that one has to involve Quantum computing, which is non-deterministic. Brains seem to have “reservoir neurons”.
https://www.researchgate.net/publication/305420421_Reservoir_Computing_as_a_Model_for_In-Materio_Computing
https://www.quantamagazine.org/20150604-quantum-bayesianism-qbism/
Quantum mechanics is weird because the real universe behind is totally different from what our minds were evolved to perceive.
Which just underlines the real problem with AI in general: we are trying to model a system we just don’t understand completely enough.
Well, some of the linguistics studies I’ve read in the past suggest that brains at least emulate quantum algorithms; when you’re presented with a choice such as between a blueberry pie and a muffin, the classical view is that your brain is primed with a pre-existing condition which leads to your eventual choice, whereas the newly discovered version is that you don’t have an opinion or an inclination over the matter at all until you’re tasked to make it – as if both choices exist in a superposition and one becomes real at the moment the choice becomes relevant – i.e. someone asks you which one would you prefer.
The Chinese room problem is a nice though experiment, but it doesn’t make really bring anything new to the table. Do you’re neuron’s chemical exchanges understand the signals they transfer? Of course not. The Room problem is an attempt to grasp at an “even deeper” meaning which doesn’t and at some point cannot exist. To chose an apt metaphor, all software must eventually meet hardware if you peel back all the interpreters.
As for the Turing test, I think you’ve got it completely backwards. Attempts at modelling a mind are much closer to an “intelligence” than a statistical algorithm or neural net which is merely trained or set up with statistical data.
Addressing your final fumbling around with determinism and semantics, let’s examine a few facts. Either the brain is just as deterministic and grounded in matter as anything else, or it isn’t. If it isn’t then that presupposes some “other” that is neither encompassed by the determinism of regular age-old physics and logic, nor the randomness that arises from thermodynamics/quantum mechanics/the random number generator of the day. This other by definition must have an effect on the brain, which will be either deterministic or random, meaning it doesn’t exist as a separable entity (there is no such “other”), or it will have no effect at all, in which case it also (this time literally) doesn’t exist. Thus, we can conclude that the brain is either not different than any other thing which dwells in matter, or what element that does not doesn’t exist in any meaningful sense. This argument was made a bit more concisely by CGP Grey in his video on the philosophy of star treck transporters, and I recommend it for further reading.
Furthermore, if the brain dwells entirely in matter, be it either purely deterministic or random, then we can both model it. If our model models it sufficiently (which is possible as the brain is equally model-able as anything else, being comprised of only deterministic and random processes and no magical other), and we define the human brain as intelligent, the model can also be said to be intelligent. I’d like to point out here that most statistical and even neural nets do not attempt to model the brain, but rather seek to emulate a very tiny portion of it’s behavior, being trained specifically on data representative of the problems to be solved.
A lot of good could be done if people would stick to rigorous proof and argument rather than philosophical spit-balling, in this area more than most.
>”Thus, we can conclude that the brain is either not different than any other thing which dwells in matter, or what element that does not doesn’t exist in any meaningful sense.”
Yes and no.
Yes, the brain is governed by the same reality as everything else. No, the brain doesn’t need to behave the same as everything else. For example, we can observe that planets adhere to classical physics, while an electron in a transistor’s gate does not. In certain circumstances we can make a piece of dust behave like the planets, in other like the quantum-tunneling electron. While quantum physics can model both, classical physics can only the other. Therefore we can claim that a stone tumbling down a hill can be qualitively different from a brain tumbling through life, and so it can be meaningful to say that one is intelligent while the other is not, and one has a mind while the other does not.
>”Furthermore, if the brain dwells entirely in matter, be it either purely deterministic or random, then we can both model it. ”
You can’t produce true randomness by any program. That’s the point. You can’t -compute- a mind; a deterministic model of a mind is no different from watching a movie or a computer game – you can rewind it back and watch it go over and over. Surely that is not what we mean by thinking, so how could such a thing be a mind?
>”Do you’re neuron’s chemical exchanges understand the signals they transfer? Of course not.”
Searle never claimed you couldn’t build an analog to a mind. He was only against hard/strong AI which claims that a mind can be built out of mere syntax. The chemical exchanges in your neurons aren’t “transferring a signal” – they are the signal, and the processor at the same time. When the vibrations in your ear turn into a train of pulses in the brain, the pulses aren’t recieved and processed as a symbol, but more like a key that physically turns a lock – the lock is meaningless without the key, and vice versa.
Interesting, it hadn’t really occurred to me that you’re right, nowadays we’re using quite a bit of neuron-based systems. I distinctly remember hearing about a point where they’d reached their limit, at least as far as research-funding was concerned. I think it had something to do with a self-tuning PID system and a disastrous flight. Funny how we had that technology way back then, then resorted to explicitly-programmed stuff, and now back to neural-nets…
https://www.youtube.com/watch?v=X7HmltUWXgs
Aw yiss… got the DTs for season 3… Rick is my spirit animal…
.. I think I’m about 33% Rick Sanchez, 33% Professor Farnsworth, 33% Doc Emmett Brown, 33% Algernop Krieger, 33% Flint Lockwood, and 33% Red Green.
Perhaps using OpenCyc with a realistic knowledge base might make for a more interesting ‘Eliza2k’ experience.
Now this is what I’ve been looking for. From just glancing so far at their website, they seem to have a knowledge base already to get you started.
Thanks for the Tip !!
I’ve used Heuristic programming, Neural Network and Genetic Algorithms before it was in vogue as today. But I was not as fortunate to have supercomputers at my disposal. The AI winter wasn’t necessarily a drain of intelligence on the matter. The lack of funding may have spurned research projects. That was just Ph.D peeps whining about losing work. The engineering projects have suffered too but they had their share of work. But looking from the publications during that decade, both textbooks and papers, there was still quite a bit of work happening.
Has there ever been a new and updated version of Eliza developed which actually can carry on a conversation, with a bigger vocabulary, and also stay in context ??
The original Eliza was extremely limited, not just for the home computer version but also the MIT version. And the current state of these supposedly “AI” tools such as the Amazon Echo and others are just glorified Butlers — say this and do that. I would think theses RPi’s whic are small enough to embed into a robot, would have enough horsepower and maybe install enough vocabulary possible for even today to make them intelligent enough to go beyond the traditional Eliza. And then you could link this with OpenCV to make it more interesting.
Meet your new best friend..
http://www.eviebot.com/en/
Not much of an inprovement
It’s just Flash Eliza.
To be fair, ELIZA was written in the 60’s and the source could probably fit on a single page. Not a great foundation.
I think you’re missing some brackets here, since I can’t make heads or tails of this formula:
The perceptron will have two weights, one for each input, called W0 and W1. Let’s consider the inputs as X0 and X1. The value of the perceptron (V) is then V=X0 W0+X1+W1.
From the next paragraph I think it should be V = X0*W0 + X1*W1. Sloppy.
You can make simple nerve like devices with digital logic. Each “cell” has two types of inputs which either make an internal counter go up, or down. A spike counter. If the counter reaches a given value (the threshold value, this is the bit where the learning is stored) then it raises it’s output high. There is also a clock signal and a counter for that which resets the spike counter if it has not counted up to it’s trigger value in time, this timer counter is reset if a trigger count is reached in time. Then the rest of the network is what cell outputs connect to which other cell inputs.
To become (somewhat) intelligent, the artificial mind must interact with the environment, and learn from this interaction. This is how all animals learn. So all attempts to program higher level intelligence into the computer that has no means of interaction (robot arms, wheel/leg movement, etc.) are very limited. This conclusion was reached by many people working in the AI field, and this is why many turned to basic sensory and reflex stuff in moving/arm equipped robots, and go from there up.
Maybe they need to interface them with artificial skin and get the Borg Queen to blow on it.
Where is the github link for the code to try ourselves?
https://github.com/wd5gnr/perceptron — Sorry, the link did not take for some reason.
The linear separability issue can be addressed by using mod. If you mod(X0 * W0 + X1 * W1, 1), you get an ‘xor’ if the weights are from -1.5 to -0.8 or 0 to 0.2 (among others). The ‘or’ as well as the ‘and’ function also repeats from -2 through 2.
Somehow the GitHub link didn’t get in (fixed now). If you are looking for the spreadsheet: https://github.com/wd5gnr/perceptron