All other things being equal, signals with wider bandwidth can carry more information. Sometimes that information is data, but sometimes it is frequency. AM radio stations (traditionally) used about 30 kHz of bandwidth, while FM stations consume nearly 200 kHz. Analog video signals used to take up even more space. However, your brain is a great signal processor. To understand speech, you don’t need very high fidelity reproduction.
Radio operators have made use of that fact for years. Traditional shortwave broadcasts eat up about 10kHz of bandwidth, but by stripping off the carrier and one sideband, you can squeeze the voice into about 3 kHz and it still is intelligible. Typical voice codecs (that is, something that converts speech to digital data and back) use anywhere from about 6 kbps to 64 kbps.
[David Rowe] wants to change that. He’s working on a codec for ham radio use that can compress voice to 700 bits per second. He is trying to keep the sound quality similar to his existing 1,300 bit per second codec and you can hear sound samples from both in his post. You’ll notice the voices sound almost like old-fashioned speech synthesis, but it is intelligible.
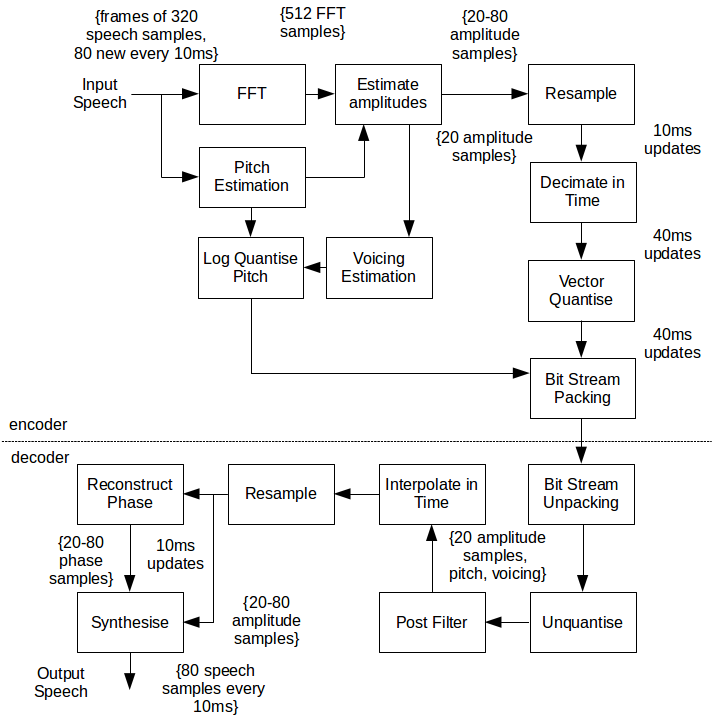
Your ears are not linear with respect to frequency response, and the codec takes advantage of this, sampling more low frequencies than high frequencies. There are other specialized signal processing and filtering steps taken to improve the audio quality. Here’s the block diagram (you can find out more at the original post):
Tight bandwidth has lots of advantages: more channels per given frequency band, less interference, and improved resistance to noise. A 700 Hz audio signal able to carry speech would have major implications for radio communications by voice.
The codec is destined for integration with FreeDV. We’ve talked before about the wealth of technology ham radio produces. Perhaps others will find use for this codec in other situations that are not ham radio-related.
Thanks to [Rob] for pointing this out.














“while FM stations consume nearly 200 kHz”
That is really not meaningful. Commercial FM stations are allocated 200 KHz, but the there are multiple subchannels occupying that space. The mono fm signal is just 15 KHz of that. The stereo multiplex channel is at 38 KHz into the band, and there are other subchannels (digital, mostly) filling out most of the rest of that 200 KHz allocation.
Okay, the mono signal itself is 15kHz of the base-band inside the carrier… even a plain mono wideband FM station, say from a FM wireless microphone, will have a bandwidth in the order of 150-200kHz.
FM comes in two flavours: narrowband and wideband. UHF CB, FM on amateur radio bands and other two-way radio systems are examples of narrowband FM. Commercial FM broadcasting including analogue television audio have always been wideband FM.
It’s all down to the modulation index: https://en.wikipedia.org/wiki/Frequency_modulation#Modulation_index
Redhatter, maybe we are talking past each other. Commercial FM radio sends mono + stereo FM, plus informational data channels, plus multiple SCA/HD channels all in that 200 KHz. It isn’t an apples to apples comparison. I also took the author to mean AM stations and FM stations to mean the 600KHz-1.8MHz commercial AM stations and 88-108 MHz commercial FM stations.
The author also confuses the codec bit rate (700 bps) with the channel bandwidth: “A 700 Hz audio signal able to carry speech would have major implications for radio communications by voice.” Depending on the S/N, the analog channel could be much smaller, the same, or much greater than 700 Hz to carry 700 bps.
Commercial FM stereo does… but doesn’t have to, and not all stations in the VHF 3m band are stereo, not all of them broadcast the digital stuff either.
If used, that is indeed how those other channels are multiplexed in; it is AM within FM, but this has nothing to do with the FM carrier itself, which would be 200kHz wide regardless of the presence of those other channels.
Pretty sure that FM stations used to actually “use” up all that “unused” bandwidth simply due to shittier technology with giant amounts of side band “noise” (in other words, you couldn’t really space them much tighter without issues of them bleeding into each other). Modern technology has allowed that to be tightened up and freed that bandwidth within the allocated spectrum to be used for newer features like RDS, “HD” radio substations, etc
For *AM only*, the bandwidth of each sideband of the modulated signal is the same as that the baseband signal. But FM is much more complex – the bandwidth of the modulated signal has more to do with the maximum deviation than with the highest audio signal (or everything riding the wave – 38kHz stereo sub-carrier, RDS etc etc). Don’t get confused. For FM, the 200KHz bandwidth refers to what’s going out on the air, not what’s going into the transmitter.
Obviously, I’m not making myself clear, as you are telling me something I know. The article, in short, says “FM uses up 200 KHz, but wow this codec, which is robot grade quality, uses only 700 Hz”. But that is apples vs oranges — yes, the FM allocation is 200 KHz, and it is carrying multiple audio and data streams. Second, the codec requires 700 bps, not 700 Hz.
@Jim B, there’s a difference between the audio bandwidth (i.e. the baseband signal), and the RF bandwidth. For AM, they are identical – i.e. if you Amplitude Modulate an audio / input / baseband signal of 0 to 2kHz, you will have a carrier and two RF sidebands each of 2kHz. But FM is a whole different monkey. Unless you’re inputting silence into the modulator, or a low amplitude or low bandwidth signal, you’re pretty much using up your whole 200kHz output / RF bandwidth (and that’s after filtering it, otherwise it could be much wider – theoretically infinite).
Check out “Carson’s Rule” on wikipedia, as well as Frequency Modulation Bessel Function
@Jim B – sorry I read it all again, and you’re right – I am telling you something you already know. We’re on the same side….
It all depends on how they want to divvy up the space. First off, they are given +/- 75 Khz with some dead space between stations. A mono broadcaster can use the entire 100% modulation or +/- 75 Khz for his signal. If you broadcast simple stereo, the pilot takes up to 10 percent of your total modulation. If you add digital services, they eat in as well. That is for commercial FM.
Hams have lived with 6K deviation for a long time on FM.
Something to consider with FM is that the term overmodulation is kind of a misnomer as unless your ends are DC and light overmodulation is self imposed line in the sand, not a physical end like it is with AM.
“Perhaps others will find use for this codec in other situations that are not ham radio-related.”
VoIP?
Maybe but I think most people have higher ip bandwidth and the number of people with very slow networks decreases constantly.
Try thinking you are blocked in the middle of the Sahara Desert and you can do only AX.25 Amateur Radio Packet Data using some old trashed vacuum-tube transceiver from some abandoned Russian tank. You tune the damn thing on SW to dial home at your listening station, get the great-great-great-grandmother of the slowest connection working and try your luck to send some distress voice call.
Maybe you want to escape from a war zone and have the opportunity to encode a small voice message inside a small picture/icon and send it via whatsapp without raising any suspicions.
Very slow networks decreases constantly but not completely. Good work!
In such extreme cases, text communications would surely suffice.
…_ _ _…
Fantastic! And once you get the Russian Valve transmitter going, and code up the codec on an arduino you happened to have lying around, you send off your voice message, and … who exactly will know how to decode it?!
Voice in 700bps is amazing, but that scenario isn’t it!
Sending audio over something weird like IR, or as a fallback for VOIP, etc…
A single packet could easily hold a whole second, so you have a whole second of a latency or you break into multiple packets and have framing overhead dominate bandwidth consumption.
Just use Opus, the quality improvement is worth the extra bandwidth.
Not real-time VoIP unless you’re talking VoIP trunks, because the overhead of IP basically makes Codec2 a waste of time.
That said, I have pondered the possibility of a Thunderbird plug-in that did voice mail using Codec2…
@Redhatter (VK4MSL)…
“…because the overhead of IP basically makes Codec2 a waste of time.”
Your VoIP based conclusions are valid, but: (I’m working from memory here.)..
Your statement is true for OSI Layer-3 connectivity e.g., IP/UDP/RTP, even with RTP header dictionary-based compression (single payload per IP/UDP/RTP packet of-course, and after session establishment – this scenario currently favors an 8Kbps raw G.829 CELP codec for example).
However, at OSI Layer-2 (e.g., tagged VLAN, MPLS, etc.) once a link is established, the header and payload overhead will be much smaller. I believe this is where smaller codec bandwidths shine – especially in applications like push-to-talk radio. Latency is also much smaller at wired Layer-2 connections.
However, I think there may be a problem with small codec payload sizes at Layer-2 in commercial applications (not Ham Radio applications where often encryption is illegal): The codec payload is too small to allow effective encryption (entropy).
For typical HF communications environments using real-time humans in a 1-to-1 session, latency and overhead in link establishment is not really an issue. Each exchane is one-way with a long delay between hand-over. This can also apply to voice store-and-forward voice messaging over latent satellite links.
My Conclusion: Extremely efficient voice codes DO have a very strong place in communications systems engineering, you just need to know where to use them.
Yeah, regarding encryption… a single Codec2 frame represents 40ms of audio and in the case of the 700C mode would occupy 28 bits.
Let’s call that 32 bits to make it a nice round power of two. If you can put up with 160ms latency, you could stuff four of them into a 128-bit block which would work fine with AES.
Techno music.
I was thinking the same thing. I’ve tried using this app called CB on Mobile and thought that maybe this could help it out, since the delay sucks on it.
One of the nice things about VOIP is that is generally sounds better than copper. In fact there are some wideband codecs that you can use in house that are really quite nice. When I first got into VOIP I recall thinking how bad old copper sounded.
I can see it being useful perhaps in an emergency, being able to pack a lot of calls into a limited amount of bandwidth though.
I don’t think I could understand a single one of those 700 bit samples the first time round. Maybe it only works if your ears are habituated to ham radio to begin with.
I couldn’t either, but I was putting it down to older ears – but that’s something that needs to be taken into consideration here as well: hearing acuity is not the same for everyone.
and if you try the code yourself you will soon realize those _terrible_ examples were carefully selected as the best of the worst :(
I have (in my opinion) good hearing, and a pretty expensive pair of Sennheiser headphones.
I couldn’t decipher what the words were on the first listen. My brain came up with several possible words for most of them. I’m still not sure I heard them correctly.
It’s impressive on paper, but that seems to be about it. Unless you were desperate and severely bandwidth-limited, in which case this codec might be just the thing.
Look up bell labs 1939 world’s fair (Voder).
Seems like at this point it would be better to completely do voice->text, transmit (compressed?) text, and then do text->voice at the other end. In the samples I heard about 3characters/second (and even at that rate it was very hard to copy accurately) so even with no compression at all that would be 24b/s and would be very easy listening at the receiving end.
Nice comparison!
Well, if you look at the Codec, you’ll notice it’s really not that far off – it does estimate speech pitch and essentially the voiced phonem and then only sends the data necessary to reconstruct that. If you want so, it’s closer to using phonetic symbols to describe what one hears (even if one doesn’t speak the language) with a couple of side-infos like loudness strewn in, than to transmitting uncompressed audio.
Can a codec like this be used as a backend for voice synthesizer?
Exactly.
Once you make this realization you open the possibility of new optimizations. For example n-grams, or even training a neural net.
I think the idea is that you can still more-or-less hear the person’s voice, even if it sounds like they’re trapped in a Darlek.
I just had a listen to a couple of them, and they sounded fine to me. As a point of interest:
http://www.rowetel.com/downloads/codec2/newamp6/vk5qi_700c.wav
Compare the speech there to this YouTube video of the same person talking:
https://www.youtube.com/watch?v=KfZmGxGN-2A
To my ear, that isn’t half bad for 700bps.
Wow, that was a long time ago… (VK5QI here)
Yeah, 5 years ago I believe… still have the mug and other tat from that trip.
I picked that 700C sample out because I knew there was that YouTube video so it’d give people an idea of how you normally sound, versus what the CODEC does.
It would require perfect voice recognition and will work only for the languages supported by the decoder and synthesizer, and we shouldn’t assume that the users will use only one language. Of course human voice compression works only for human voice, and we can (for now) safely assume that it won’t be used by some aliens ;)
Most communications already assume that the users at either end speak the same language.
Yep, but the machines in between will have to “speak” it too. Bad luck if they decide to switch from English to Hungarian then to German or something.
If you are trying to send voice with the least amount of bandwidth and you are packing bits it is digital so you should make the most of digital. First you can do a voice to text then send every three words as a trigram code, this would be shorter for more common utterances and even include an opcode for previous parts of the same stream, such as call signs. So about 64 bits for any three words. The initial establishment of the link can include parameters that can be used as transforms to bend the speech synth at the receiving end toward the sound of the sender’s voice. i.e. Meh I can do it in 10% of those 700 bits/s. The trigrams codes are from an agreed corpus sorted by usage frequency, so that can be one of the huge sets in the public domain now, or a dynamically grown one as two stations continue to interact, or a bit of both.
Well, if hams measured “what we do” by “what technically makes sense in this world”, >95% of amateur radio would simply not happen. So, the point here is that people /like/ voice communication, and good codecs really have tremendous amounts of use in the real, non-ham world.
Low-rate voice comm not only has historic value – there’s certainly more than one situation where one is in need of communication without the possibility to have text, but with the possibility to intuitively communicate things like urgency, or panic. Think of firefighters: They tend to be stupid enough to go into buildings (with steel-armed concrete just to annoy the radio propagation), especially when significant amounts of the atmosphere inside are being ionized and thus leading to bad propagation.
I have described a voice system, one that uses 10% of the bandwidth and has a far higher quality, clearly you have no idea what I am talking. The system does not send text, it sends semantic symbols that are spoken in a good facsimile of the original speakers voice, better than the above described 700 b/s quality. Even stress and emphasis can be encoded into the stream if required. As I already pointed out, with codecs once you go across into digital encoding you may as well do it as efficiently as possible. And yeah I do get that much of AR could be described as masturbation, but if you are going to draw a line as to what tech is and isn’t acceptable you’d better have a good reason otherwise your argument is ridiculous.
The difference here, is that this vocoder is published, while yours is not.
Since no-one has pointed this out so far:
even if your channel is good, i.e. when you can do far more bitrate than your audio codec needs, the math behind channel coding allows you to take that amount of data, and add redundancy to make it more robust.
People often struggle with that concept; if I tell you, you have a 10 kb/s capable channel, why would I use a 1.3kb/s codec at all? The answer is simple: if you can *understand* what is said over that codec when the transmission is perfect 100% of time, you can add more than 6 times the original data amount in redundancy to make sure the transmission is, in effect, perfect, even if there were *a lot* of bit errors.
This error correction functionality allows us to use relatively terrible channels for relatively reliable communications – and yes, I mean, terrible, in the sense of “AM won’t be intellegible anymore, and for FM, the bandwidth is too small to be effectively more reliable than AM”.
CELP (Code Excited Linear Prediction) is a speech codec with a very low data rate. IIRC the (optional) speech chip in the Acorn BBC Model B was CELP based by Texas Instruments.
Analog Video (which includes audio) for NTSC cable is allocated 6MHz but as someone else pointed out this is not all used. Some space is needed to keep overtones from leaking onto there neighbors.
Consider me impressed. I was using the audio quality of DMR radio as a basis for comparison, and this 700 bit/sec audio sounds nearly as good to my ears as DMR which runs as high as 9.6Kbps! To have a codec that uses such a minuscule percentage of DMR’s bandwidth sound similar is amazing, IMHO.
What’s the bit rate of this?
https://www.youtube.com/watch?v=muCPjK4nGY4&t=1s
Maybe compare it to ADPCM, Alaw, ulaw, speex with the same initial audio sample?
First thing to go is usually the hard consonant sounds, indistinguishable ‘f’ ‘p’ ‘ch’
There’s a stripped down C version that creates a DLL for your experimenting. Compiles on a RPi as well.
https://github.com/ObjectToolworks/vocoder700c
NASA has release an really good text to speech codec included in their Moonbase Alpha Simulator. Even inflections are decent.
As George Lucas once said “Alpha Simulator Source code is the is the key to all of this, because if we can get Alpha Sim working then 300 Baud would be easier then teletype over IR LED’s.”
Here is a nifty sample for your listening pleasure.
P.S. Video of utter silly and odd audio.
https://www.youtube.com/watch?v=Hv6RbEOlqRo
P.P.S. I didn’t understand a single clip of the 700 sampled poop (and we watch a ton of BBC). tl;dr – Audio playback would still be a P.I.T.A. if chip providing decoding didn’t contain needed codec. FFS, I have a $2.50 MP3 player that takes an SD card and plays back 12,5k 44k audio. Codec means squat unless you can decode/playback on known codec on board chip packs. Consider that to me this feels similar to a WinAce archive being unpacked by pbgzip played back then repacked to WinAce and sent back (considering you aren’t allowed to encrypt this serves no purpose). Unless this is a streamlined hardware call of existing functions across multi platforms including a vacuum tube user it doesn’t seem to present any real value.