
The word supercomputer gets thrown around quite a bit. The original Cray-1, for example, operated at about 150 MIPS and had about eight megabytes of memory. A modern Intel i7 CPU can hit almost 250,000 MIPS and is unlikely to have less than eight gigabytes of memory, and probably has quite a bit more. Sure, MIPS isn’t a great performance number, but clearly, a top-end PC is way more powerful than the old Cray. The problem is, it’s never enough.
 Today’s computers have to processes huge numbers of pixels, video data, audio data, neural networks, and long key encryption. Because of this, video cards have become what in the old days would have been called vector processors. That is, they are optimized to do operations on multiple data items in parallel. There are a few standards for using the video card processing for computation and today I’m going to show you how simple it is to use CUDA — the NVIDIA proprietary library for this task. You can also use OpenCL which works with many different kinds of hardware, but I’ll show you that it is a bit more verbose.
Today’s computers have to processes huge numbers of pixels, video data, audio data, neural networks, and long key encryption. Because of this, video cards have become what in the old days would have been called vector processors. That is, they are optimized to do operations on multiple data items in parallel. There are a few standards for using the video card processing for computation and today I’m going to show you how simple it is to use CUDA — the NVIDIA proprietary library for this task. You can also use OpenCL which works with many different kinds of hardware, but I’ll show you that it is a bit more verbose.
Dessert First
One of the things that’s great about being an adult is you are allowed to eat dessert first if you want to. In that spirit, I’m going to show you two bits of code that will demonstrate just how simple using CUDA can be. First, here’s a piece of code known as a “kernel” that will run on the GPU.
__global__
void scale(unsigned int n, float *x, float *y)
{
int i = threadIdx.x;
x[i]=x[i]*y[i];
}
There are a few things to note:
- The __global__ tag indicates this function can run on the GPU
- The set up of the variable “i” gives you the current vector element
- This example assumes there is one thread block of the right size; if not, the setup for
iwould be slightly more complicated and you’d need to make surei < nbefore doing the calculation
So how do you call this kernel? Simple:
scale<<<1,1024>>>(1024,x,y);
Naturally, the devil is in the details, but it really is that simple. The kernel, in this case, multiplies each element in x by the corresponding element in y and leaves the result in x. The example will process 1024 data items using one block of threads, and the block contains 1024 threads.
You’ll also want to wait for the threads to finish at some point. One way to do that is to call cudaDeviceSynchronize().
By the way, I’m using C because I like it, but you can use other languages too. For example, the video from NVidia, below, shows how they do the same thing with Python.
Grids, Blocks, and More
 The details are a bit uglier, of course, especially if you want to maximize performance. CUDA abstracts the video hardware from you. That’s a good thing because you don’t have to adapt your problem to specific video adapters. If you really want to know the details of the GPU you are using, you can query it via the API or use the
The details are a bit uglier, of course, especially if you want to maximize performance. CUDA abstracts the video hardware from you. That’s a good thing because you don’t have to adapt your problem to specific video adapters. If you really want to know the details of the GPU you are using, you can query it via the API or use the deviceQuery example that comes with the developer’s kit (more on that shortly).
For example, here’s a portion of the output of deviceQuery for my setup:
CUDA Device Query (Runtime API) version (CUDART static linking) Detected 1 CUDA Capable device(s) Device 0: "GeForce GTX 1060 3GB" CUDA Driver Version / Runtime Version 9.1 / 9.1 CUDA Capability Major/Minor version number: 6.1 Total amount of global memory: 3013 MBytes (3158900736 bytes) ( 9) Multiprocessors, (128) CUDA Cores/MP: 1152 CUDA Cores GPU Max Clock rate: 1772 MHz (1.77 GHz) Memory Clock rate: 4004 Mhz Memory Bus Width: 192-bit L2 Cache Size: 1572864 bytes . . . Maximum number of threads per multiprocessor: 2048 Maximum number of threads per block: 1024 Max dimension size of a thread block (x,y,z): (1024, 1024, 64) Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535) Maximum memory pitch: 2147483647 bytes
Some of this is hard to figure out until you learn more, but the key items are there are nine multiprocessors, each with 128 cores. The clock is about 1.8 GHz and there’s a lot of memory. The other important parameter is that a block can have up to 1024 threads.
So what’s a thread? And a block? Simply put, a thread runs a kernel. Threads form blocks that can be one, two, or three dimensional. All the threads in one block run on one multiprocessor, although not necessarily simultaneously. Blocks are put together into grids, which can also have one, two, or three dimensions.
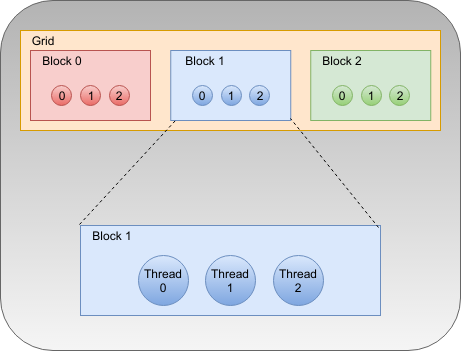
So remember the line above that said scale<<>>? That runs the scale kernel with a grid containing one block and the block has 1024 threads in it. Confused? It will get clearer as you try using it, but the idea is to group threads that can share resources and run them in parallel for better performance. CUDA makes what you ask for work on the hardware you have up to some limits (like the 1024 threads per block, in this case).
Grid Stride Loop
One of the things we can do, then, is make our kernels smarter. The simple example kernel I showed you earlier processed exactly one data item per thread. If you have enough threads to handle your data set, then that’s fine. Usually, that’s not the case, though. You probably have a very large dataset and you need to do the processing in chunks.
Let’s look at a dumb but illustrative example. Suppose I have ten data items to process. This is dumb because using the GPU for ten items is probably not effective due to the overhead of setting things up. But bear with me.
Since I have a lot of multiprocessors, it is no problem to ask CUDA to do one block that contains ten threads. However, you could also ask for two blocks of five. In fact, you could ask for one block of 100 and it will dutifully create 100 threads. Your kernel would need to ignore all of them that would cause you to access data out of bounds. CUDA is smart, but it isn’t that smart.
The real power, however, is when you specify fewer threads than you have items. This will require a grid with more than one block and a properly written kernel can compute multiple values.
Consider this kernel, which uses what is known as a grid stride loop:
__global__
void scale(unsigned int n, float *x, float *y)
{
unsigned int i, base=blockIdx.x*blockDim.x+threadIdx.x, incr=blockDim.x*gridDim.x;
for (i=base;i<n;i+=incr) // note that i>=n is discarded
x[i]=x[i]*y[i];
}
This does the same calculations but in a loop. The base variable is the index of the first data item to process. The incr variable holds how far away the next item is. If your grid only has one block, this will degenerate to a single execution. For example, if n is 10 and we have one block of ten threads, then each thread will get a unique base (from 0 to 9) and an increment of ten. Since adding ten to any of the base numbers will exceed n, the loop will only execute once in each thread.
However, suppose we ask for one block of five threads. Then thread 0 will get a base of zero and an increment of five. That means it will compute items 0 and 5. Thread 1 will get a base of one with the same increment so it will compute 1 and 6.
Of course, you could also ask for a block size of one and ten blocks which would have each thread in its own block. Depending on what you are doing, all of these cases have different performance ramifications. To better understand that, I’ve written a simple example program you can experiment with.
Software and Setup
Assuming you have an NVidia graphics card, the first thing you have to do is install the CUDA libraries. You might have a version in your Linux repository but skip that. It is probably as old as dirt. You can also install for Windows (see video, below) or Mac. Once you have that set up, you might want to build the examples, especially the deviceQuery one to make sure everything works and examine your particular hardware.
You have to run the CUDA source files, which by convention have a .cu extension, through nvcc instead of your system C compiler. This lets CUDA interpret the special things like the angle brackets around a kernel invocation.
An Example
I’ve posted a very simple example on GitHub. You can use it to do some tests on both CPU and GPU processing. The code creates some memory regions and initializes them. It also optionally does the calculation using conventional CPU code. Then it also uses one of two kernels to do the same math on the GPU. One kernel is what you would use for benchmarking or normal use. The other one has some debugging output that will help you see what’s happening but will not be good for execution timing.
Normally, you will pick CPU or GPU, but if you do both, the program will compare the results to see if there are any errors. It can optionally also dump a few words out of the arrays so you can see that something happened. I didn’t do a lot of error checking, so that’s handy for debugging because you’ll see the results aren’t what you expect if an error occurred.
Here’s the help text from the program:

So to do the tests to show how blocks and grids work with ten items, for example, try these commands:
./gocuda g p d bs=10 nb=1 10 ./gocuda g p d bs=5 nb=1 10
To generate large datasets, you can make n negative and it will take it as a power of two. For example, -4 will create 16 samples.
Is it Faster?
Although it isn’t super scientific, you can use any method (like time on Linux) to time the execution of the program when using GPU or CPU. You might be surprised that the GPU code doesn’t execute much faster than the CPU and, in fact, it is often slower. That’s because our kernel is pretty simple and modern CPUs have their own tricks for doing processing on arrays. You’ll have to venture into more complex kernels to see much benefit. Keep in mind there is some overhead to set up all the memory transfers, depending on your hardware.
You can also use nvprof — included with the CUDA software — to get a lot of detailed information about things running on the GPU. Try putting nvprof in front of the two example gocuda lines above. You’ll see a report that shows how much time was spent copying memory, calling APIs, and executing your kernel. You’ll probably get better results if you leave off the “p” and “d” options, too.
For example, on my machine, using one block with ten threads took 176.11 microseconds. By using one block with five threads, that time went down to 160 microseconds. Not much, but it shows how doing more work in one thread cuts the thread setup overhead which can add up when you are doing a lot more data processing.
OpenCL
OpenCL has a lot of the same objectives as CUDA, but it works differently. Some of this is necessary since it handles many more devices (including non-NVidia hardware). I won’t comment much on the complexity, but I will note that you can find a simple example on GitHub, and I think you’ll agree that if you don’t know either system, the CUDA example is a lot easier to understand.
Next Steps
There’s lots more to learn, but that’s enough for one sitting. You might skim the documentation to get some ideas. You can compile just in time, if your code is more dynamic and there are plenty of ways to organize memory and threads. The real challenge is getting the best performance by sharing memory and optimizing thread usage. It is somewhat like chess. You can learn the moves, but becoming a good player takes more than that.
Don’t have NVidia hardware? You can even do CUDA in the cloud now. You can check out the video for NVidia’s setup instructions.
Just remember when you create a program that processes a few megabytes of image or sound data, that you are controlling a supercomputer that would have made [Seymour Cray’s] mouth water back in 1976.














I understand that CUDA uses its own syntax, but this doesn’t look like it even passes C syntax rules. It’s missing a closing parenthesis, and there’s no increment clause:
for (i=base;i=n is discarded
x[i]=x[i]*y[i];
Please explain…
Probably a bad case of <>:
for (i=base; i= n is discarded
Yep, got mangled in comments too :D
Correct! Here’s a link to the source line in question: https://github.com/wd5gnr/gocuda/blob/master/gocuda.cu#L14
WordPress tries to preserve things in code and randomly eats them with no pattern I can discern.
Fixed, I think.
Thanks!
No mention of Rocm HIP so you can run it on other platforms?
At first glance at the title and top photo, I thought someone had found a way to use an old Barracuda hard drive as a processor.
Notice how much bigger the newer cards are.
No, but Sprite_tm did: http://spritesmods.com/?art=hddhack
whens the transcript from that going up?
Good question, since it was posted about on HaD back in 2013
https://hackaday.com/2013/08/02/sprite_tm-ohm2013-talk-hacking-hard-drive-controller-chips/
Seems biased against OpenCL, and goes against the hacking principles of openness, since CUDA is proprietary.
I agree that OpenCL’s interface is clunky and has a lot of boilerplate, though HSA promises a more transparent interface for using GPUs.
Personally, learning (and really understanding) OpenCL GPU programming was one of the most intellectually stimulating things I have done in the past few years. The SIMD concepts that I was taught in university years ago don’t fully teach the potential of GPU programs that often described as Single Instruction Multiple Thread instead of SIMD.
I mentioned OpenCL but it is clunkier, in my opinion. I happen to know how to use CUDA and I don’t know OpenCL well, but it isnt’ to imply I am endorsing one over another.
Yeah. I too would have much preferred this to be an OpenCL thing. Yes it looks a bit clunkier initially, but that’s the price of portability and a pretty powerful API, that’s intended to support things like FPGAs too.
One of the really nice things about OpenCL (apart from the openness and portability) is that you effectively build a dependency graph of your computations. So you can line up a whole bunch of different kernels, interconnected by memory buffers that they read from or write to as necessary. You specify their dependencies and then send the whole lot off to get churned on by the GPU.
This is not to bash Cuda because I assume that it has similar features. The point is that when you’re writing GPU code, you’re explicitly writing extremely concurrent code so the whole computational model is different from a single CPU, which means that to leverage the full performance, you need to think about and structure your computations quite differently. You’ve got:
– concurrency within a kernel (massively parallel SIMD)
– concurrency between multiple kernels operating on different arrays
– concurrency between GPU kernels and code running on the CPU
– probably multiple threads on the GPU.
Designing efficient and reliable (the hard part) software that utilises all that concurrency efficiently is *hard* and requires different ways of thinking. IMHO that’s what this sort of intro article should be talking about: data-flow design etc.
Oh yeah, and don’t use one vendor’s proprietary interface, even if it is popular :( You wouldn’t write a DirectX article for HAD would you?
that’d be “multiple threads on the CPU”. Damn you edit-button.
Erlang/Haskell and GPUs.
way to drive take-up, lol
This. OpenCL ftw!
Just face it that sometimes open-source stinks compared to proprietary alternatives. Android is an over-complicated mess to program for that had too many cooks in the kitchen. Maya 3d interface from 10 years ago is still easier to use than today’s Blender. I could go on…
Supercomputer is a relative term. Cray 1 existed before the 8080…
If losing a few lines of boilerplate was enough to get me interested in proprietary languages, I’d be one of those people who uses 12 different IDEs for different parts of a project and thinks it was easier! *roflcopter*
The reality might be, if you’re the sort of person who needs hello world to be really easy, you might not really need to worry too much about GPU programming and should focus on learning high level APIs in a simple language. Because that way they can build a complete app, without learning that hard stuff that is full of complicated details that they’re avoiding. :)
Appreciated this write up, and for those going on about how this could be better if it was about OpenCL, why not publish an equivalent article?
Probably because most of those ‘advocating’ OpenCL aren’t writers. There’s a very big difference between writing code and writing about code in a way which those unfamiliar with it can understand.
Then there’s the inevitable abuse from the CUDA fanbois…
Oh, and the Al Williams fanbois :)
Because there are plenty of such articles and tutorials out there already. Why would I add another one?
I mean sure, I could blather on for a bit about how I had a play with OpenCL and wrote a mandelbrot zoomer and blah blah blah… but you can find plenty of that online already.
snark: same logic applies to Cuda :P
I’ve dabbled in OpenCL and CUDA, and generally found CUDA development to be friendlier, better documented (in terms of examples and tutorials), and better supported.
I’d love to see an article that changes my opinion of OpenCL. Open source is great, but sometimes proprietary is just better. Why else would Windows and Mac still exist? As for people saying proprietary is opposed to hacking, well that’s why it’s called “hacking” instead of “using as designed”. The only downside to CUDA’s proprietary nature is that it only works with Nvidia GPUs.
Agree with Josh, fanboys on either side are why we can’t have nice things.
I’m pretty preferential to AMD, however for the years I’ve been reading about CUDA/OpenCL. Almost without exception I’ve read that CUDA is ‘easier’ to start with, a la Verilog/VHDL.
No where in the article did I detect any bias or promotion of CUDA aside from the stated fact that the author simply knows CUDA and not OpenCL. Where it different, then I’d see where some of the whiners might have had a point.
HAD really should start giving triggered trolls a week’s timeout.
Do you really want to give Benchoff the authority to block comments from people who don’t agree with him?
As a HaD editor, doesn’t he already have it?
Cuda is propriety and so support can come from Nvidia fanbois. OpenCl is universal and open and so NOT tied to AMD nor Nvidia.
And obviously an open thing that runs not only on both Nvidia and AMD but also intel and any other system that has a GPU/CPU has a wider audience and supports more operating systems and platforms and is therefore objectively preferable I would think.
As for Williams and bias, I think the headline of this article reads like a nvidia ad. But I nevertheless for now trust it’s true that he just dabbles a lot with Cuda and wants to share his enthusiasm, like so many writers do with their articles on HaD, they use what they are into and share it in a writeup, that’s the HaD format.
CUDA is property of Nvidia Corporation and it’s not cross-vendor tech. E.t. if you learn CUDA and create a program with it you will lose 50% of the market – the non- CUDA (ATI) GPUs. The first GPGPU code which was portable was done using OpenGL and fragment shader programs. Nowadays OpenCL aims at cross platform GPGPU support.
Sure OpenCL promises portability but isn’t the dirty little secret, that in order to get good performance you have to optimize for each specific target platform to the point that you basically have to write completely different code for each different target? the whole point of using GPU compute like this is high performance right? If your gonna right OpenCL code that’s going to run on different platform, say for example Nvidia, AMD, and Xeon Phi, can you really just write one piece of code that will fully leverage those 3 very different platforms to the fullest? Or do you still just wind up having to write a different one for each?
Half true. You can write some OpenCL and it will run on a bunch of different things, and it will run a *lot* faster on most of them than it would on a CPU.
Yes, you need to do some tweaking to get the best from each architecture, but a lot of that tweaking is not in rewriting the code but carefully selecting (often by experimentation) appropriate data sizes/strides to balance the bus bandwidth/latency, cache size and processor count for each device.
Dirtier secret: you need to do the same tweaking to optimise for different devices within the same product family, whether you use OpenCL or Cuda.
I just wanted to state that the use of MIPS in this article was confusing to me. MIPS can be used to describe a processor architecture (and it is a RISC architecture at that) and “Machine Instructions Per Second”. The second is what I think the article was referencing.
And number of instructions per second isn’t a great measure of performance, as different operations can take different amounts of time (integer multiplication vs floating point multiplication, for instance). FLOPS – floating point operations per second might be considered a more ‘taxing’ measure of performance.
tl;dr MIPS – machine instructions per second != MIPS the RISC processor architecture.
“Sure, MIPS isn’t a great performance number, but clearly, a top-end PC is way more powerful than the old Cray.”
Both of your complaints are addressed in the article.
But the acronym MIPS is not expanded upon within the article.
MIPS is an architecture, that is correct.
MIPS being “machine instruction per second” is incorrect. It actually stands for “Millions of Instruction Per Second.”
Otherwise the article wouldn’t have stated 250 000 MIPS, but rather 250 000 000 000 MIPS. Since if one spends 1 million clock cycles to do 1 instruction, then one is likely doing something wrong…
Too bad NVIDIA prioritizes trying to gain market share over trying to develop good technologies. They’re doing everything they can to lock people in to their products. It’s hard to get behind a company that would rather spend time hurting other companies than to just work on having good products.
Just look at NVIDIA’s GeForce Partner Program if you have any doubts.
“rather spend time hurting other companies”
Kinda like M$ ??
I’m though curious to the “A modern Intel i7 CPU can hit almost 250,000 MIPS and is unlikely to have less than eight gigabytes of memory, and probably]…”
Since if we go and look for I7 CPUs, and check their MIPS performance, as in Cores times the processing speed in MHz, since this will be roughly the lowest expected MIPS performance we can get. (Yes, out of order execution does increase our max performance, but I’ll get into that later.)
Then the currently fastest I7 CPU on the market seems to be Intel Core i7 Extreme 6950X. (The Intel Core i7 7820X comes a close second though.)
But this only has 30 000 MIPS (10 cores at 3 GHz), that is a bit less then 1/8 the claimed performance that we can get out of an every day I7. (since the “is unlikely to have less than eight gigabytes of memory” part makes it sound like you talk about a regular I7 gaming computer or something….)
Then we have out of order execution, that at times can run multiple instructions in parallel.
There is still certain things within a program that simply can’t effectively run in parallel, dragging down our average performance closer to the minimum.
But I personally have never heard of an out of order implementation able to keep an average speedup of 8 times, I have looked, and even found systems that during certain instruction sequences can give well over 20 times the execution speed, though, this has been in systems that are catering for more application specific tasks. Rather unlike a general purpose X86 CPU.
Hyper threading will though help in the out of order execution by ensuring that two consecutive instruction are from different threads, meaning that as long as they aren’t the same instruction, we can run them in parallel. (Sometimes we can run them in parallel even if they are the same instruction. But this isn’t always the case.) So this will in practice generally give a performance speedup, for parallel execution, serial execution (single threaded applications) is though now half as fast.
So where the 250 000 MIPS in modern I7 CPUs came from is a good question, since even the highest performing I7 currently on the market would have a semi hard time reaching that. (Maybe some super optimized applications can run that, but who develops such?!)
Do mind, the Intel Core i7 Extreme 6950X also costs the better part of two grand, so isn’t going to be a typical CPU in most computers. Meaning that the run of the mill I7 is going to have far lower performance, and an even harder time reaching those 250 thousand MIPS.
If you would state that a Intel Xeon Platinum 8180 could reach 250 000 MIPS, then I wouldn’t be too surprised, since it would be expected to give at least 70 000 MIPS based on its 28 cores and 2.5 GHz clock speed. And from there to 250 thousand MIPS isn’t a too huge step anymore, so hyper threading and out of order execution will likely takes up there.
Also do mind, all of this is based on X86 running only single cycle instructions, and that isn’t the case in reality.
Cray 1 can’t do 150 MIPS.
It’s a scalar processor (1 instruction per clock maximum) with a frequency of 80MHz -> maximum 80 MIPS.
It is however also a vector processor with several vector units which means it can create a chain of vector operations IIRC* with a maximum of one load, one store, one multiply and one addition per clock -> 160 MFLOPS, 320 MOPS** maximum.
This is very important to understand (in order to see the advantages of vector processors) that performance doesn’t scale linearly with instructions executed.
If a vector could be infinite long 3 instruction could do a sum of products with infinite operands while approaching 0 MIPS (3 instructions/ (x clocks) where x -> infinity).
(* ages since I read up about it, most likely not correct)
(** not standard terminology, Million Operations Per Second)
Would have liked the article on SPIR-V and OpenCL. The Khronos Group is making some pretty cool advances that aren’t NVidia centric.
OpenCL can be used for some heavy lifting. One example is the Strongene OpenCL HEVC decoder. That can make an old Socket 939 dual core Athlon 64 able to play 1280×720 HEVC video with a nVidia 8800GT. Disable the Strongene decoder and it’ll stutter in scenes with fast motion or high detail. Such a setup will *almost* handle 1080p HEVC. If there’s no high detail or fast motion it’ll do it. Oh, you’ll also need Potplayer. Other media players don’t handle HEVC near as well, especially on lower performance computers.
This article illustrates the problem that has existed for too long now…highly parallel code is difficult which is the same problem is the supercomputer world. One thing Open Souce has been weak on is highly optimized compilers that can use the parallelism we have access to without the brute force techniques in the source code. A follow up article showing a real world proble being solved might be more illustrative and a good description of the kinds of computation that are worthy of the effort of parallel programming would be great.
An optimizing compiler could look at your source code and make decisions on whether the overhead of parallel processing is worth it and can include code that examines the capabilities of the systems it is running on to make the code portable. For example it can include OpenCL and CUDA modules which it branches to depending on the hardware detected. That is a lot to hand code but an optimizing compiler can automate that in the same way that numeric co-processors used to be detected and used.
You need a compiler smart enough to evaluate what the program is trying to do and then optimize for the available resources.
REALLY, Is a top-end PC more powerful than a Cray computer, or is it maybe FASTER.
It would be really dependent on the problem you are trying to solve. Most of the supercomputers out there now are really good at a specific type of problem and really bad at general computing. They are more like a co-processor than a system. The key to supercomputers are their interconnects, the best interconnect network is very dependent on how tightly coupled the system needs to be and what kind of speed it takes to move the I/O. A very computationally intense problem with a small data set can get away with slower, low bandwidth interconnect and a very parallel but not difficult problem requires a faster tighter interconnect to keep the processors fed efficiently. A large scale weather system I worked with had an older Unisys mainframe front ending the Cray processing machines just because it was so much easier to interface with.
Your PC is pretty good at a very wide variety of stuff and ease of interaction and programmability is designed into it. The one thing they are not so good it is highly parallel processing which is why we have GPUs in the first place.
Supercomputers of old were a lot more impressive from an engineering perspective. Cray wrung every last big of horsepower out of not so powerful hardware and pioneered things like liquid cooling and memory architectures that are still in use, the secret sauce was the system. Newer supercomputing is a lot more commodity based. Many are just data centers of off the shelf 1 U hardware with fancy interconnect networks, the secret sauce is the programming. In fact, some of the Top 500 systems are distributed like folding@home which is actually YOUR PC hardware. If it was looked at that way probably the top supercomputer recently would be the Bitcoin network which is also a distributed problem.