
Used for general purpose programming, data science, website backends, GUIs, and pretty much everything else; the first programming language for many, and claimed to be the fastest growing in the world, is of course Python. The newest version 3.7.0 has just recently been released.
Naturally any release of Python, no matter how small, undergoes meticulous planning and design before any development is started at all. In fact, you can read the PEP (Python Enhancement Proposal) for Python 3.7, which was created back in 2016.
What’s new in 3.7? Why should you upgrade? Is there anything new that’s actually useful? I’ll answer these questions for you by walking through some examples of the new features. Whilst there’s not much in this release that will make a difference to the Python beginner, there’s plenty of small changes for seasoned coders and a few headline features you’ll want to know about.
Breakpoints Are Now Builtins
Anyone who has used the pdb (Python debugger) knows how powerful it is. It gives you the ability to pause the execution of your script, allowing you to manually roam around the internals of the program and step over individual lines.
But, up until now, it required some setup when writing a program. Sure, it takes practically no time at all for you to import pdb and set_trace(), but it’s not on the same level of convenience as chucking in a quick debug print() or log. As of Python 3.7, breakpoint() is a built-in, making it super easy to drop into a debugger anytime you like. It’s also worth noting that the pdb is just one of many debuggers available, and you can configure which one you’d like to use by setting the new PYTHONBREAKPOINT environment variable.
Here’s a quick example of a program that we’re having trouble with. The user is asked for a string, and we compare it to see if it matches a value.
"""Test user's favourite Integrated Circuit."""
def test_ic(favourite_ic):
user_guess = input("Try to guess our favourite IC >>> ")
if user_guess == favourite_ic:
return "Yup, that's our favourite!"
else:
return "Sorry, that's not our favourite IC"
if __name__ == '__main__':
favourite_ic = 555
print(test_ic(favourite_ic))
Unfortunately, no matter what is typed in, we can never seem to match the string.
$ python breakpoint_test.py Try to guess our favourite IC >>> 555 Sorry, that's not our favourite IC
To figure out what’s going in, let’s chuck in a breakpoint — it’s as simple as calling breakpoint().
"""Test user's favourite Integrated Circuit."""
def test_ic(favourite_ic):
user_guess = input("Try to guess our favourite IC >>> ")
breakpoint()
if user_guess == favourite_ic:
return "Yup, that's our favourite!"
else:
return "Sorry, that's not our favourite IC"
if __name__ == '__main__':
favourite_ic = 555
print(test_ic(favourite_ic))
At the pdb prompt, we’ll call locals() to dump the current local scope. The pdb has a shedload of useful commands, but you can also run normal Python in it as well.
$ python breakpoint_test.py
Try to guess our favourite IC >>> 555
> /home/ben/Hackaday/python37/breakpoint_test.py(8)test_ic()
-> if user_guess == favourite_ic:
(Pdb) locals()
{'favourite_ic': 555, 'user_guess': '555'}
(Pdb)
Aha! It looks like favourite_ic is an integer, whilst user_guess is a string. Since in Python comparing a string to an int is a perfectly valid comparison, no exception was thrown (but the comparison doesn’t do what we want). favourite_ic should have been declared as a string. This is arguably one of the dangers of Python’s dynamic typing — there’s no way of catching this error until runtime. Unless, of course, you use type annotations…
Annotations and Typing
Since Python 3.5, type annotations have been gaining traction. For those unfamiliar with type hinting, it’s a completely optional way of annotating your code to specify the types of variables.
Type hints are just one application of annotations (albeit the main one). What are annotations? They’re syntactic support for associating metadata with variables. They can be considered to be arbitrary expressions which are evaluated but ignored by Python at runtime. An annotation can be any valid Python expression. Here’s an example of an annotated function where we’ve gone bananas with useless information.
# Without annotation
def foo(bar, baz):
# Annotated
def foo(bar: 'Describe the bar', baz: print('random')) -> 'return thingy':
This is all very cool, but a bit meaningless unless annotations are used in standard ways. The syntax for using annotations for typing became standardised in Python 3.5 (PEP 484), and since then type hints have become widely used by the Python community. They’re purely a development aid, which can be checked using an IDE like PyCharm or a third party tool such as Mypy.
If our string comparison program had been written with type annotations, it would have looked like this:
"""Test user's favourite Integrated Circuit."""
def test_ic(favourite_ic: str) -> str:
user_guess: str = input("Try to guess our favourite IC >>> ")
breakpoint()
if user_guess == favourite_ic:
return "Yup, that's our favourite!"
else:
return "Sorry, that's not our favourite IC"
if __name__ == '__main__':
favourite_ic: int = 555
print(test_ic(favourite_ic))
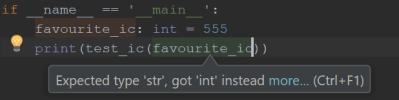
You can see that PyCharm has alerted me to the error here, which would have prevented it going un-noticed until runtime. If your project is using CI (Continuous Integration), you could even configure your pipeline to run Mypy or a similar third party tool on your code.
So that’s the basics of annotations and type hinting. What’s changing in Python 3.7? As the official Python docs point out, two main issues arose when people began to start using annotations for type hints: startup performance and forward references.
- Unsurprisingly, evaluating tons of arbitrary expressions at definition time was quite costly for startup performance, as well as the fact that the
typingmodule was extremely slow - You couldn’t annotate with types that weren’t declared yet
This lack of forward reference seems reasonable, but becomes quite a nuisance in practice.
class User:
def __init__(self, name: str, prev_user: User) -> None:
pass
This fails, as prev_user cannot be defined as type User, given that User is not defined yet.
To fix both of these issues, evaluation of annotations gets postponed. Annotations simply get stored as a string, and optionally evaluated if you really need them to be.
To implement this behaviour, a __future__ import must be used, since this change can’t be made whilst remaining compatible with previous versions.
from __future__ import annotations
class User:
def __init__(self, name: str, prev_user: User) -> None:
pass
This now executes without a problem, since the User type is simply not evaluated.
Part of the reason the typing module was so slow was that there was an initial design goal to implement the typing module without modifying the core CPython interpreter. However, now that the use of type hints is becoming more popular, this restriction has been removed, meaning that there is now core support for typing, which enables several optimisations.
Timing
The time module has some new kids on the block: existing timer functions are getting a corresponding nanosecond flavour, meaning greater precision is on tap if required. Some benchmarks show that the resolution of time.time() is more than three times exceeded by that of time.time_ns().
Talking of timing, Python itself is getting a minor speed boost in 3.7. This is low level stuff so we won’t go into it right now, but here’s the full list of optimisations. All you need to know is that the startup time is 10% faster on Linux, 30% faster on MacOS, and a large number of method calls are getting zippier by up to 20%.
Dataclasses
We’re willing to bet that if you’ve ever written object-oriented Python, you’ll have made a class that ended up looking something like this:
class User:
def __init__(self, name: str, age: int, favourite_ic: str) -> None:
self.name = name
self.age = age
self.favourite_ic = favourite_ic
def is_adult(self) -> bool:
"""Return True if user is an adult, else False."""
return self.age >= 18
if __name__ == '__main__':
john = User('John', 29, '555')
print(john)
# prints "<__main__.User object at 0x0076E610>"
A ton of different arguments are received in __init__ when the class gets initialised. These are simply set as attributes of the class instance straight away, ready for later use. This is a pretty common pattern when writing these kind of classes — but this is Python, and if tedium can be avoided, it should be.
As of 3.7, we have dataclasses, which will make this type of class easier to declare, and more readable.
Simply decorate a class with @dataclass, and the assignment to self will be taken care of automatically. Variables are declared as shown below, and type annotations are compulsory (though you can still use the Any type if you want to be flexible).
from dataclasses import dataclass
@dataclass
class User:
name: str
age: int
favourite_ic: str
def is_adult(self) -> bool:
"""Return True if user is an adult, else False."""
return self.age >= 18
if __name__ == '__main__':
john = User('John', 29, '555')
print(john)
# prints "User(name='John', age=29, favourite_ic='555')"
Not only was the class much easier to setup, but it also produced a lovely string when we created an instance and printed it out. It would also behave properly when being compared to other class instances. This is because, as well as auto-generating the __init__ method, other special methods were generated too, such as __repr__, __eq__ and __hash__. These vastly reduce the amount of overhead needed when properly defining a class like this.
Dataclasses use fields to do what they do, and manually constructing a field() gives access to additional options which aren’t the defaults. For example, here the default_factory of the field has been set to a lambda function which prompts the user to enter their name.
from dataclasses import dataclass, field
class User:
name: str = field(default_factory=lambda: input("enter name"))
(We wouldn’t recommend piping input into an attribute directly like this – it’s just a demo of what fields are capable of.)
Other
There are other miscellaneous changes aplenty in this release; we’ll just list a few of the most significant here:
- Dictionaries are now guaranteed to preserve insertion order. This was informally implemented in 3.6, but is now an official language specification. The normal
dictshould now be able to replacecollections.OrderedDictin most cases. - New documentation translations into French, Japanese and Korean.
- Controlling access to module attributes is now much easier, as
__getattr__can now be defined at a module level. This makes it far easier to customise import behaviour, and implement features such as deprecation warnings. - A new developer mode for CPython.
- .pyc files have the option to be deterministic, enabling reproducible builds — that is, the same byte-for-byte output is always produced for the same input file.
Conclusion
There are some really neat syntactic shortcuts and performance improvements to be had, but it might not be enough to encourage everyone to upgrade. Overall, Python 3.7 implements features that will genuinely lead to less hacky solutions, and produce cleaner code. We certainly look forward to using it, and can’t wait for 3.8!














“… you can still use the Any type if you want to be flexible”
It would be great if you could tailor the flexibility to fit, like allowing not only Any, but “Some” (more than one type allowed, but not just any type, only expected ones), or “Any but …” (all types allowed except listed, … although this is just for logic symmetry, as I can’t imagine when that would be useful).
I think you can use Union for allowing multiple types. https://docs.python.org/3/library/typing.html#typing.Union
But I don’t think you can do ‘Any but’ – which is perhaps for the best, so that you’re not claiming to support types that you don’t explicitly state.
You’re sort of fighting the nature of python at that point.
You can write code to convert types but that gets clumsy fast and as the saying goes ‘isn’t pythonic’. Int 4 and string “4” can be manipulated as either as the setting fits.Other number types can be manipulated together without trouble.
You can declare a bounded TypeVar (available in the typing module) to get some flexibility. Although defining your own abc is also a good solution to this.
It has been 11 years since I dabbled in Python.
This looks like a good way to get back into it.
Is there any way to get some kind of overview of the libraries (always the most worthwhile part of a language)?.
Search.cpan.org (or now, metacpan) has spoiled me…
I used to have MFC memorized (no really) but it took a couple years and now I don’t do windows anyway.
There are two places to look, the included batteries: https://docs.python.org/3/py-modindex.html and the add-on batteries https://pypi.org/
https://docs.python.org/3/library/ for standard libraries. There are lists of ‘libraries you can’t live without’ but the most efficient way is probably just look at projects solving the problems you’re interested in. SciPy, NumPy, and matplotlib are probably 3 big ones you can do just about anything with.
Thanks guys.
A modern day “Basic”. ;-)
Very nice. I’ll update as soon as Intel’s Python and MKL support it.
I hate that the libraries I do most of my work with don’t support anything past 2.7 :(
The photo shows a corn snake, not a python.
I believe you’re mistaken. There are numerous differences, but notably, corn snakes don’t have slit pupils.
Can someone suggest a reference to get started in Python? And a programming environment that would work on a MacBook? I have experience in Basic and Fortran but am a little overwhelmed looking at all the Python reference materials.
after exploring a few options I landed on LiClipse. It’s a bit difficult to set up, but lacks only a couple of features from a big money microsoft type OOP dev environment.
Check out https://learnpythonthehardway.org don’t be fooled by the name ????
As for an environment, your Mac book will probably already have a Python interpretor (but likely out of date), but that aside standard cpython from Python.org. For an IDE PyCharm is still the best by far, the community edition is free to use and more than capable.
Yes. PyCharm.
pycharm annoys me.
several systems crash, daily (x-servers crash) when the guys at work use pycharm. on an old ubuntu, it works fine for them. on newer mint, it crashes all of X11 and the session-mgr restarts. I don’t use pycharm but the users tell me their systems are unstable with it. and its not an opensource project, exactly, is it?
anyone else experience this?
I would avoid pycharm. I am told its ‘great’, but its written in a bad way, and I have not run into an app that crashes all of X for a long long time! I do give X some blame, but why on earth is pycharm so crashy?
PyCharm CE is open source. The non-CE version is closed. CE is only lacking a few features.
I’m a fan of JupyterNotebook (formerly IPython) which gives you matlab cell type code execution. Useful for testing snippets and scientific work. PyCharm is nice but some of it’s features get in my way sometimes, I also don’t work on vast bodies of code regularly so I’m sure it’s more than I need.
I’ve heard good things about that JupyterNotebook thing. for people starting out with python, it might be something to look into.
I use emacs, I save files and run them. occasionally I’ll use pdb. dunno, don’t need all that much. I break things down into smaller parts, those can be edited with simple editors (emacs colorize mode is most of what I would want) can be tested on their own and then combined at higher layers, easily.
if your python program is so large that you ‘need’ an IDE, seems that you may be pushing python too far, or you need to restructure.
if I need to run something quickly and with some line editing, then ipython. all on linux, of course.
I’m a huge fan of Spyder for my editor and it’s free.
at-signs. sigh.
I know, I should like them, or try to like them, or at least act like I like them.
I just am not used to them, even 2 years on, to be honest. they don’t flow, they don’t read well, they cause me to stop reading and stumble. (all imho of course).
maybe I’m too stuck with C style languages (even most c++ annoys me). did we -really- need that at-sign stuff in python? I KNOW that it does useful stuff, but I can’t be the only one who simply cannot read code with them in there.
I had trouble for a while too until I realised a decorator is simply a function that returns a function. I.e. a wrapper.
If you @mywrapper in front of a function, then the mywrapper function will be called with your function as the arg and the resulting function is returned and is what is called.
A trivial example would be to create a debug decorator function that printed out args and then ran the function and then printe dout the result before returning, Then you could use it temporarily to see what the args and results were for a function you needed to debug.
This page is quite good in a useful way:
– https://www.thecodeship.com/patterns/guide-to-python-function-decorators/
This one has some tips:
– http://hangar.runway7.net/python/decorators-and-wrappers
even though I realize its a function that takes a function and returns a function, it still doesn’t READ well. it does not let me read code from top to bottom and have the lines on the page assemble meaningful sense in my brain. the decorator stuff still just does not read like code. its like “below, you will find lines of code. but that is not what will get run. something behind me will get run and that will run THIS code.” and I just find that too annoying and it blocks my reading and quick understanding.
perhaps just seeing it over time and accepting it will make it ‘make sense’ to me. but it has been a struggle for the 2+ years I’ve been actively using python. (I have been writing code since my teens and I’m over 50, so that may have something to do with it; this decorator concept was not in the early languages I learned and I’m having trouble finding a place to put it, in my internal brain wiring)
Agree with this 100% and it equally applies to some other concepts that are creeping in to the language. Python used to have a certain cleanness, but it seems like too many new features sacrifice readability for the sake of saving a couple of keystrokes. It’s not as if they even add any real functionality.
Life is too short to deal with funny abstract notation. I’ll stick with C and maybe a little JavaScript. I don’t really need any other languages, especially when they don’t seem to solve any problems for me. What I have will get me to retirement.
and yet there is no word about fixing the indentation mess…
99% of my python bugs are caused by indentation.
And yet the *only* time I have ever had indentation errors was when I was first learning Python and experimented with it when I learned about that. I played around enough to see what it meant by warning me about mixing tabs and spaces, and then *NEVER* had an issue. And I’ve been working heavily in Python for scientific computing since 2007, and have strong C and Java experience prior, and Basic and Fortran from when I was a kid. So one time in a decade (and intentionally at that) seems like it’s not really as much a mess as being implied.
What mess?
It’s easier than counting braces or parentheses, according to many it makes the code more readable, and it’s certainly easier than debugging spaghetti code.
Modern IDEs count braces or parentheses for you.
Modern IDEs also have the option to show whitespace. People who struggle with Python indentation should probably try that.
using spaces for indentation is the second worst thing about python, though it is close. The worst is what this article highlights “it looks like favourite_ic is an integer, whilst user_guess is a string” – any language that doesn’t have typing to at least Cs level is useless apart from small simple programs – unless you want the code to be not be maintainable or debug-able by anyone apart from the author – and often not even them..
Unless the program fits on a single page I wouldn’t go near python..
All this discussion of static typing vs dynamic is a bit of a canard. You can accomplish any task with either, but you can’t use the same thought process to write the code. Either can be a crutch for poor practices. The example of ‘expected int’ “user string” isn’t a failing of the language, it’s a failing of the dev. Static types don’t solve the user entering the wrong type they just offer a different error. No one complains that sql boxes need to sanitize user input to guard against injections but if you have to pay attention to the type you’re getting all of the sudden it’s a terrible language?
“Aha! It looks like favourite_ic is an integer, whilst user_guess is a string.” — This is what I very much hate about Python and the likes! You have to jump through hoops just because you never know for sure what type your variables really are, or else you might run into all sorts of bugs. I like being able to specifically define what type I want a variable to be, just so I don’t have to go guessing at runtime.
strongly typed makes more sense to me. the ‘duck typing’ is lame. sorry, guido, but you are wrong. you are wrong a lot. you are also right a lot, but not 100%.
indentation was wrong, as a concept (ie, pasting in code is always risky in python, and never in C, etc).
and the duck typing is also brain-damaged.
I use python a lot, but I’m honest about the parts of it that were badly thought or reasoned out.
I thought that the User class declaration used here was the “old style”. I thought class Foo(object) was the rule now, and the old style classes are going away. But I just tried it in python 3.5 and hmm – more than one way to do it? How un-pythonic!
I find “whilst” as annoying as “@”. Much prefer “whenst”.
I agree with the ‘flow’ broken using ‘@’ … Don’t use the feature much.
Don’t see anything above that would cause me to ‘jump’ to 3.7 as a ‘must have’.
As for indenting, I like the indent rule because it is how I write ‘c’ code too. It forces ‘structure’ on new coders which is good and keeps the rest of us in line (pun intended). I use a 3 space indent rule and all is well. No tabs allowed. Same with C/C++. In C, the braces and statements in a block are all in a vertical line for easy reading. I very much dislike the style where { is put after a control statement (same line) and the following brace is somewhere else under the statement. That said, I see the problem with pasting Python code, say off the web, but a few clicks here and there and your back lined up. Off course, I’d do the same for any ‘c’ code I pull in to my code. I can’t stand willy nilly coding styles in a code file that I have control over!
As for Python, I really like it for a lot of things. I do wish it was strongly typed though… But so it goes. Use it at work for all kinds of data manipulation and communications. None of which requires bare metal speed or GUIs for the most part, so very acceptable, and being a script, can be modified on the fly when needed. Very readable so others can jump in if needed – unlike Perl which we use a bit also. Python has lots of libraries for math, reading csv, reading/writing excel spreadsheets, plotting, communications (http, https, ftp, sftp, etc). Also supports threading after a fashion. Has good Linux/Windows support. At home I use it in my RPIs and other tasks that again don’t require ultimate speed. Very handy easy to use language that gets the job done. When I need speed or large projects, I go back to basic ‘c’.
Been coding since a teen, BS CS, in my 50s now.
All this makes me look at my 1st ed. copy of Kernighan and Ritchie kinda wistfully — we didn’t even have enums then. It’s still on my 3-foot shelf (you know: the three feet of classic books, 3 feet from your desk. Look it up. Kids these days…)
If you want to learn more about Python 3, I would recommend checking out this website, they do a great job of covering everything: https://www.activestate.com/activepython/python-3