
While desktop computers have tons of computing power and storage, some small CPUs don’t have a lot of space to store things. What’s more is some CPUs don’t do multiplication and division very well. Same can be said for FPGAs. So suppose we are going to grab a bunch of three-digit decimal numbers from, say, a serial port. We want to store as many as we can, and we don’t want to do a lot of math because we can’t, it is slow, or perhaps it keeps our processor awake longer and we want to sleep to conserve power. We want a way to pack the numbers as close to the theoretical maximum as we can but with little or no math.
The simple approach is to store the numbers as ASCII. Great for processing since they are probably in ASCII already. If they aren’t, you just add 30 hex to each digit and you are done. That’s awful for storage space, though, since we can store 999 in 10 bits if it were binary and now we are using 24 bits! Storing in binary isn’t a good option, if you play by our rules, by the way. You need to multiply by 10 and 100 (or 10 twice) to get the encoding. Granted, you can change that to two shifts and an add (8x+2x=10x) but there’s no easy way to do the division you’ll have to do for the decode.
Of course, there’s no reason we can’t just store decimal digits. That’s call binary coded decimal or BCD and that has some advantages, too. It is pretty easy to do math on BCD numbers and you don’t get rounding problems. Some CPUs even have specific instructions for BCD manipulation. However, three digits will require 12 bits. That’s better than 24, we agree. But it isn’t as good as that theoretical maximum. After all, if you think about it, you could store 16 distinct codes in 4 bits, and we are storing only 10, so that 6 positions lost. Multiply that by 3 and you are wasting 18 codes.
But there is a way to hit that ten-bit target without doing any math. Its called DPD or densely packed decimal. You can convert three decimal digits into ten bits and then back again with no real math at all. You could implement it with a small lookup table or just do some very simple multiplexer-style logic which means it is cheap and easy to implement in software or onboard an FPGA.
This packing of bits was the problem that Thedore Hertz and Tien Chi Chen both noticed around 1969-1971. Hertz worked for Rockwell and Chen worked for IBM and consulted with another IBM employee, Irving Tze Ho. Hertz and Chen independently developed what would become known as Chen-Ho encoding. A bit later, Michael Cowlinshaw published a refinement of the encoding called DPD or densely packed decimal that became part of the IEEE floating point standard.
Both Hertz and Chen used slightly different encodings, but the Cowlinshaw scheme had several advantages. You can efficiently grow beyond 3 digits easily. Decimal numbers from 0 to 79 map to themselves. Bit zero of each digit is preserved so you can do things like check for even and odd numbers without unpacking.
How Does it Work?
Think of three BCD digits written in binary. Because each digit is in the range [0-9], it can be represented with four bits, so our three digits look like Xabc Ydef Zghi. For instance, if the first digit is 9 then Xabc = 1001. Since we’re only encoding numbers up to nine, if X is 1, then a and b must be 0, leaving us some space to pack other bits into. Now consider XYZ as its own three-digit binary number. This leads to eight distinct cases. The table below shows the encoding for all eight cases, with a lower case x indicates a don’t care:
| Case (XYZ) | Xabc | Ydef | Zghi | Encoding 9 8 7 6 5 4 3 2 1 0 |
| 000 | 0abc | 0def | 0ghi | a b c d e f 0 g h i |
| 001 | 0abc | 0def | 100i | a b c d e f 1 0 0 i |
| 010 | 0abc | 100f | 0ghi | a b c g h f 1 0 1 i |
| 011 | 0abc | 100f | 100i | a b c 1 0 f 1 1 1 i |
| 100 | 100c | 0def | 0ghi | g h c d e f 1 1 0 i |
| 101 | 100c | 0def | 100i | d e c 0 1 f 1 1 1 i |
| 110 | 100c | 100f | 0ghi | g h c 0 0 f 1 1 1 i |
| 111 | 100c | 100f | 100i | x x c 1 1 f 1 1 1 i |
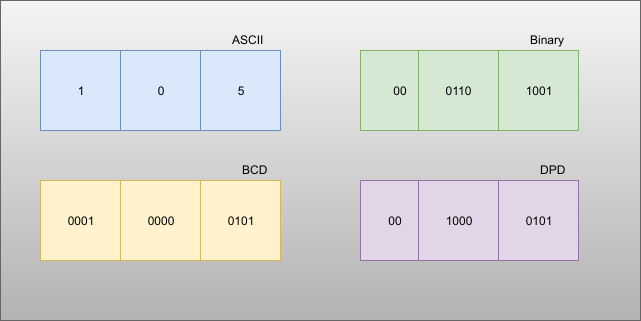
Notice that c, f, and i always pass through. The other bit positions vary depending on the case, but you don’t need any math to simply rearrange the bits and add the fixed indicator bits in bits 6-5 and 3-1 of the 10-bit encoding.
In the example figure, 105 matches case 000 — all leading bits are zero — so the encoding is 0010000101 or 085 hex. If the number had been, say, 905 that would match case 100 and would encode as 1010001101 or 28D hex. Decoding is just a matter of running the table backward. If bit 3 is zero, that’s case 000. Otherwise, look at bits 2 and 1. Unless they are 11, you can directly find the corresponding row in the table. If they are 11, you’ll have to further look at bits 6 and 5 to find the right entry. Then you just unwind the bits according to the table.
Implementation
I was mostly interested in this for FPGA designs, so I wrote some simple Verilog to do the work and you can try it online. The testbench included runs through all 1,000 possible numbers and outputs the DPD code in hex, the 3 input digits, a slash, and the 3 output digits like this:
0fd = 9 7 1 / 9 7 1 1fc = 9 7 2 / 9 7 2 1fd = 9 7 3 / 9 7 3 2fc = 9 7 4 / 9 7 4 2fd = 9 7 5 / 9 7 5 3fc = 9 7 6 / 9 7 6
The encoding is very straightforward. Here’s a snippet for two rows of the table:
3'b000:
dpd={digit2[2:0],digit1[2:0],1'b0,digit0[2:0]};
3'b001:
dpd={digit2[2:0],digit1[2:0],3'b100,digit0[0]};
You’ll notice the code used no clocks — it is pure logic and makes extensive use of the case and casez statements. These are like switch statements in C although the casez statement can use ? as a don’t care when matching.
I left both Verilog and C implementations on GitHub for you. Both are pretty naive. For example, the Verilog code doesn’t take advantage of the fact that some of the bits “pass through.” However, a good compiler or synthesizer may turn out some pretty good code anyway. But if you were really worried about minimizing floorplan or code space or minimizing power consumption, you’ll need to tune these to fit your architecture and your needs.
Algorithms
It used to be when you learned about computers one of the first things you were taught was algorithms and data structures. I’m not sure that’s the case anymore. But the world is full of obscure algorithms we might use if we only knew them. I’m surprised there aren’t more catalogs of algorithms like [Sean Anderson’s] famous bit twiddling hacks page. Probably the best one for everything — which means it is overwhelming — is the NIST DADS dictionary. Be warned! You can spend a lot of your day browsing that site. Even as big as that site is, they specifically exclude business, communications, operating system, AI, and many other types of algorithms.
I mean, sure, most of us know a bubble sort and a shell sort, but do you know a cocktail sort or how to do a Richardson-Lucy deconvolution? The DADS doesn’t either, although Wikipedia is helpful. We couldn’t find consistent overhead byte stuffing or Chen-Ho in either place. Seems like this would be a great AI project to catalog and help locate algorithms and data structures for particular uses. But for now, you can at least add dense packed decimal to your bag of known tricks.














There is an archive of sorts here: https://github.com/algorithm-archivists/algorithm-archive
and here is the website: https://www.algorithm-archive.org/
Can somebody explain this in baby language? I didn’t understand it at all.
Let’s say you are receiving data as ASCII (because else, there is absolutely no need for this). You’ll receive ‘9’ then ‘7’ then ‘8’. You are very very miserly so you can’t afford to loose 8bit * 3 = 24bits in memory to store this. Since you’ve chose the cheapest microcontroller you could find, with the cheapest compiler possible, you can’t use a division by anything else than a power of 2, nor any multiplication.
So instead of doing the sane (‘9’ – ‘0’) * 100 + (‘7’ – ‘0’) * 10 + ‘8’ – ‘0’ and store this in a 16 or 32 bits register, like any sane person would do (you are also trying to save on the register size at the time), so how do you do ?
You’ll spend a week implementing an encoding that’ll convert (‘9’ – ‘0’) to a 4 bits number, and so on for other digit, then you’ll twiddle the bits following a dark magic table, and finally with only OR and shift, you’ll get a 10 bits number.
Please notice that multiplying by 10 or 100 is also possible with only addition and bit shift, as any decent compiler would do anyway, but, well, it’s much more fun to write code you’ll never be able to debug/understand the next week/month.
By the time you’ve debugged all of this and wasted most of your precious time, you’ll probably realize that, it’s probably easier to send the initial message in binary (instead of ascii) so you have no work to do, or simply pay one more cent for a decent compiler/microcontroller/FPGA and don’t care about voodoo anymore.
haha great answer, I actually know what’s going on now, and know not to try it.
Okay, it’s the unused space from [9d or 1001b] to 1111b , to encode more usefull use of the bitspace . an interesting approach to numeric compression. Personally I prefer Huffman, it does about 50% compression ,lossless , does ASCII/numbers, and whatever other characters in the source file
Except this isn’t about saving space for text. It’s about storing decimal numbers without wasting space, while leaving them numeric so they can be processed easily.
Not too sure there’s much processing you can do with the encoded values. If you add the encoding of S to the encoding of T, and then decode the result, do you get S+T ? Seemed scant on examples but it looked like if S<T, encoded(S) < encoded(T) not guaranteed for all S,T .
I think about all you can do is save the values for later reconstitution. And that might be useful, there are places where you want to log data and you don't have much storage or cpu power. But then if things are *that* cramped, 10 bits is an awkward size to deal with. Doesn't fit in a byte. If you use two bytes, easier to have just BCD'd it and done just as well. To really eek out the best data:memory ratio, you'd probably need to cram 3 of these into 4 bytes, but that only represents 1,000,000,000 values out of 4,294,967,296 bit patterns, so jeepers probably should go after those two bits or .. or ..
Or yeah, don't try to cheap out and build your mnemonic memory circuit using stone knives and bear skins
Yes I too wondered “what the hell’s the point”. After a bit of thought I came up with “cheap ASCII to binary conversion”. Given that the DPD is a well packed binary key it should be possible to use it to directly map to the pure binary equivalent of the ASCII by simply using it as an index into a lookup table.
Anyone out there in cyberspace knows how NASA does their telemetry, is it on top of a encryption stack, or in the clear?
Don’t forget rosetta code for all your algorithm examples!
https://rosettacode.org/wiki/Rosetta_Code
Since you are doing this in an FPGA… could you use it in tha phase accumulator of a DDS signal generator?
Given a 32 bit accumulator, you could have a nice range of 4,000,000,000 instead of 2^32. That in turn means you have a nice basic oscillator value like 40.000 MHz.
COBOL had this figured out decades ago