The simplest answer to a problem is not necessarily always the best answer. If you ask the question, “How do I get a voice assistance to work on a crowded subway car?”, the simplest answer is to shout into a microphone but we don’t want to ask Siri to put toilet paper on the shopping list in front of fellow passengers at the top of our lungs. This is “not a technical issue but a mental issue” according to [Masaaki Fukumoto], lead researcher at Microsoft in “hardware and devices” and “human-computer interaction.” SilentVoice was demonstrated in Berlin at the ACM Symposium on User Interface Software and Technology which showed a live transcription of nearly silent speech. A short demonstration can be found below the break.
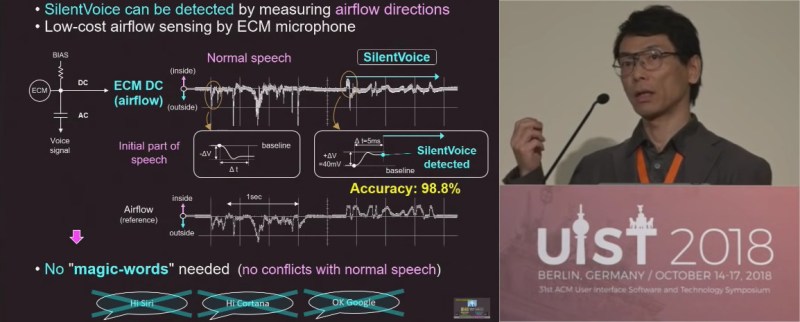
SilentVoice relies on a different way of speaking and a different way of picking up that sound. Instead of traditional dictation in which we exhale while facing a microphone, it is necessary to place the microphone less than two millimeters from the mouth, usually against the lips, and use ingressive speech which is just whispering while inhaling. The advantage of ingressive over egressive speech is that without air being blown over the microphone, the popping of air gusts is eliminated. With practice, it is as efficient as normal speaking but that practice will probably involve a few dizzy spells from inhaling more than necessary.
Signal to noise ratios are stellar and the microphone can act as a flow sensor to know when it should start listening. This means there is no need for activation phrases like, “Siri,” “Alexa,” “Google,” or “Cortana,” and the sound that does escape is approximately 40dB which is on par with the sound levels at a library, yet it can function someplace as noisy as public transit.
For true subvocalization, MIT is taking a crack with an equally unobtrusive device paired with bone conduction speakers.














Let me know when phones can do ASL. That would be useful.
Yeah, because kissing your phone all the time is so sanitary.
But seriously, I would guess the MEMS microphones used in modern phones could work with negative pressures, as they respond to changes in pressure already (from sounds) so maybe just an app would be needed, or maybe just turn the mic sensitivity way down.
With the right video app I’m sure they already can. The question is why? Why not just use the keyboard already built in? Is the stock memo app really that bad? Could you (or someone) not write a script to update your amazon dash orders when the memo file changes size or md5?
People use ASL instead of typing for the same reason you use your voice: it’s faster, more expressive, and you don’t need a gadget. But Deaf people can’t hear spoken English and need a voice ASL interpreter (at $70 an hour and up). Many can’t speak, some can’t read or type.
Recently HAD had a glove-based fingerspelling project…. no. We need a camera that interprets gestures into words (written OK, spoken better) plus the opposite: a microphone input voice-to (word) to-ASL converter (cartoon figure on a screen). I’ve seen one but it was very expensive.
This looks interesting. Open source it. I wonder how this ingressive system can be mounted like in a partial, denture or on a tooth like some bling. :-)
In regards to the ASL phone… Amazing there isn’t an app! There seem to be plenty of databases of images related. Seems like an easy project technically to translate and even streamline into a stick figure like version to ease resource handling requirements. Either communication way too… using a vision system to interpret and display/speak or using audio to interpret and display.
In regards to speech recognition… I’m going to drop this reference here also since isn’t the same technology… though has potential also:
https://hackaday.com/2018/09/14/speech-recognition-without-a-voice/
> lead researcher at Microsoft
Dear Aunt, let’s set so double the killer delete select all
I haven’t heard that in years!
Hehe, you beat me at it:)
One has to admit they learned something during all those years.
https://www.youtube.com/watch?v=-0kDcUEDfmY
Whatever happen to KISS? Simply use the phone’s key board to create and maintain text lists? Simple AI is ma kinking humans stupid and lazy. Humanity is really screwed, when AI become more advanced.Personally I rarely find a need for siri, the echo dot is used to use as a timer that don’t have timers and if they do have very week audio. A plus side I never expected every post to be some I’d need.
>”Simply use the […] key board”
*Stares in Stephen Hawking*
So the intent is to surreptiously dictate notes in public ?
Why ? Why not just take out a simple notepad and write it down ?
Reminds me of this comic
https://xkcd.com/530/
Also, I think they are behind the curve for signal to noise discrimination science at least for spoken audio.
https://www.youtube.com/watch?v=LD68Tz1lFvw
By the way – that is *NOT* – absolutely NOT the Motorola cell phone division – it’s the core company that spun off the cellular division, and returned to their roots (two way police radios). The half of the company that makes cell phones is not related to Motorola Solutions.
By the way – that *SHOULD* – absolutely should by included in the Motorola cell phone division.
Most cel conversatons consist of repetitions of “beg you pardon? can barely hear you!”
Hmm… Sticking my lips all over my phone. I’m less than excited. Wake me when I can just have a direct neural interface, until then I’ll use the touch screen in loud places and activation words elsewhere.
On second thought, given how much control the telecom barons maintain on our devices even after we purchase them I don’t think I want to plug one of those into my brain either. Touch and activation words forever it is then.