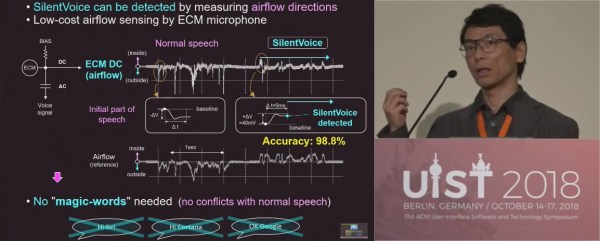
The simplest answer to a problem is not necessarily always the best answer. If you ask the question, “How do I get a voice assistance to work on a crowded subway car?”, the simplest answer is to shout into a microphone but we don’t want to ask Siri to put toilet paper on the shopping list in front of fellow passengers at the top of our lungs. This is “not a technical issue but a mental issue” according to [Masaaki Fukumoto], lead researcher at Microsoft in “hardware and devices” and “human-computer interaction.” SilentVoice was demonstrated in Berlin at the ACM Symposium on User Interface Software and Technology which showed a live transcription of nearly silent speech. A short demonstration can be found below the break.
SilentVoice relies on a different way of speaking and a different way of picking up that sound. Instead of traditional dictation in which we exhale while facing a microphone, it is necessary to place the microphone less than two millimeters from the mouth, usually against the lips, and use ingressive speech which is just whispering while inhaling. The advantage of ingressive over egressive speech is that without air being blown over the microphone, the popping of air gusts is eliminated. With practice, it is as efficient as normal speaking but that practice will probably involve a few dizzy spells from inhaling more than necessary.













