‘Hearing voices’ doesn’t have to be worrisome, for instance when software-defined radio (SDR) happens to be your hobby. It can take quite some of your time and attention to pull voices from the ether and decode them. Therefore, [theckid] came up with a nifty solution: RadioTranscriptor. It’s a homebrew Python script that captures SDR audio and transcribes it using OpenAI’s Whisper model, running on your GPU if available. It’s lean and geeky, and helps you hear ‘the voice in the noise’ without actively listening to it yourself.
This tool goes beyond the basic listening and recording. RadioTranscriptor combines SDR, voice activity detection (VAD), and deep learning. It resamples 48kHz audio to 16kHz in real time. It keeps a rolling buffer, and only transcribes actual voice detected from the air. It continuously writes to a daily log, so you can comb through yesterday’s signal hauntings while new findings are being logged. It offers GPU support with CUDA, with fallback to CPU.
It sure has its quirks, too: ghost logs, duplicate words – but it’s dead useful and hackable to your liking. Want to change the model, tweak the threshold, add speaker detection: the code is here to fork and extend. And why not go the extra mile, and turn it into art?
Before the release of Piper TTS in 2023, existing free-to-use TTS systems such as espeak and Festival sounded robotic and flat. Piper delivered much more natural-sounding output, without requiring massive resources to run. To change the voice style, the Piper AI model can be either retrained from scratch or fine-tuned with less effort. In the latter case, the problem to be solved first was how to generate the necessary volume of training phrases to run the fine-tuning of Piper’s AI model. This was solved using a heavyweight AI model, ChatterBox, which is capable of so-called zero-shot training. Check out the Chatterbox demo here.
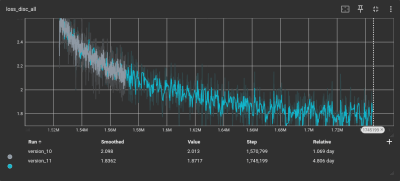
As the loss function gets smaller, the model’s accuracy gets better
Training began with a corpus of test phrases in text format to ensure decent coverage of everyday English. [Cal] used ChatterBox to clone audio from a single test phrase generated by a ‘mystery TTS system’ and created 1,300 test phrases from this new voice. This audio set served as training data to fine-tune the Piper AI model on the lashed-up GPU rig.
To verify accuracy, [Cal] used OpenAI’s Whisper software to transcribe the audio back to text, in order to compare with the original text corpus. To overcome issues with punctuation and differences between US and UK English, the text was converted into phonemes using espeak-ng, resulting in a 98% phrase matching accuracy.
After down-sampling the training set using SoX, it was ready for the Piper TTS training system. Despite all the preparation, running the software felt anticlimactic. A few inconsistencies in the dataset necessitated the removal of some data points. After five days of training parked outside in the shade due to concerns about heat, TensorBoard indicated that the model’s loss function was converging. That’s AI-speak for: the model was tuned and ready for action! We think it sounds pretty slick.
[saurabhchalke] recently released whisper.unity, a Unity package that implements whisper locally on the Meta Quest 3 VR headset, bringing nearly real-time transcription of natural speech to the device in an easy-to-use way.
Whisper is a robust and free open source neural network capable of quickly recognizing and transcribing multilingual natural speech with nearly-human level accuracy, and this package implements it entirely on-device, meaning it runs locally and doesn’t interact with any remote service.
Meta Quest 3
It used to be that voice input for projects was a tricky business with iffy results and a strong reliance on speaker training and wake-words, but that’s no longer the case. Reliable and nearly real-time speech recognition is something that’s easily within the average hacker’s reach nowadays.
We covered Whisper getting a plain C/C++ implementation which opened the door to running on a variety of platforms and devices. [Macoron] turned whisper.cpp into a Unity binding which served as inspiration for this project, in which [saurabhchalke] turned it into a Quest 3 package. So if you are doing any VR projects in Unity and want reliable speech input with a side order of easy translation, it’s never been simpler.
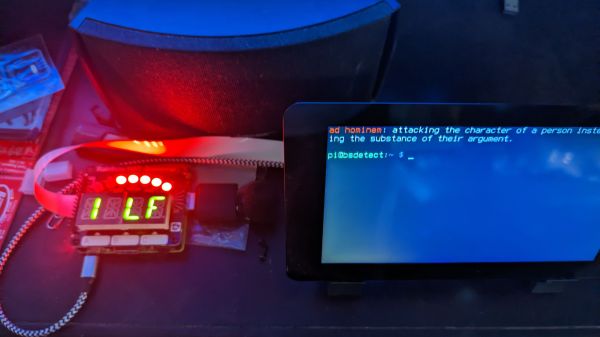
If you’re hoping that this AI-powered logic analyzer will help you quickly debug that wonky digital circuit on your bench with the magic of AI, we’re sorry to disappoint you. But if you’re in luck if you’re in the market for something to help you detect logical fallacies someone spouts in conversation. With the magic of AI, of course.
First, a quick review: logic fallacies are errors in reasoning that lead to the wrong conclusions from a set of observations. Enumerating the kinds of fallacies has become a bit of a cottage industry in this age of fake news and misinformation, to the extent that many of the common fallacies have catchy names like “Texas Sharpshooter” or “No True Scotsman”. Each fallacy has its own set of characteristics, and while it can be easy to pick some of them out, analyzing speech and finding them all is a tough job.
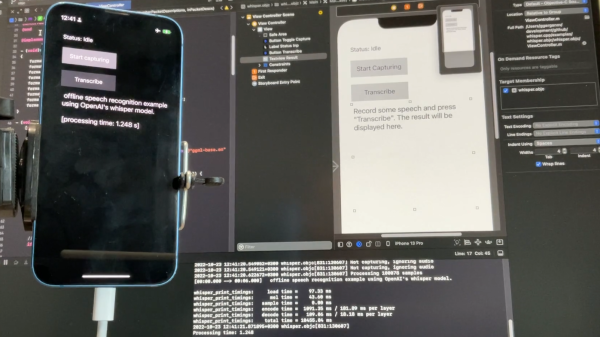
[Georgi Gerganov] recently shared a great resource for running high-quality AI-driven speech recognition in a plain C/C++ implementation on a variety of platforms. The automatic speech recognition (ASR) model is fully implemented using only two source files and requires no dependencies. As a result, the high-quality speech recognition doesn’t involve calling remote APIs, and can run locally on different devices in a fairly straightforward manner. The image above shows it running locally on an iPhone 13, but it can do more than that.
Implementing a robust speech transcription that runs locally on a variety of devices is much easier with [Georgi]’s port of OpenAI’s Whisper.[Georgi]’s work is a port of OpenAI’s Whisper model, a remarkably-robust piece of software that does a truly impressive job of turning human speech into text. Whisper is easy to set up and play with, but this port makes it easier to get the system working in other ways. Having such a lightweight implementation of the model means it can be more easily integrated over a variety of different platforms and projects.
The usual way that OpenAI’s Whisper works is to feed it an audio file, and it spits out a transcription. But [Georgi] shows off something else that might start giving hackers ideas: a simple real-time audio input example.
By using a tool to stream audio and feed it to the system every half-second, one can obtain pretty good (sort of) real-time results! This of course isn’t an ideal method, but the robustness and accuracy of Whisper is such that the results look pretty great nevertheless.
You can watch a quick demo of that in the video just under the page break. If it gives you some ideas, head over to the project’s GitHub repository and get hackin’!
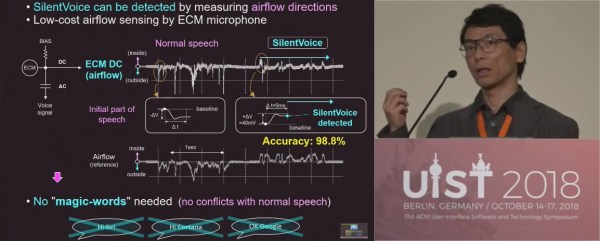
The simplest answer to a problem is not necessarily always the best answer. If you ask the question, “How do I get a voice assistance to work on a crowded subway car?”, the simplest answer is to shout into a microphone but we don’t want to ask Siri to put toilet paper on the shopping list in front of fellow passengers at the top of our lungs. This is “not a technical issue but a mental issue” according to [Masaaki Fukumoto], lead researcher at Microsoft in “hardware and devices” and “human-computer interaction.” SilentVoice was demonstrated in Berlin at the ACM Symposium on User Interface Software and Technology which showed a live transcription of nearly silent speech. A short demonstration can be found below the break.
SilentVoice relies on a different way of speaking and a different way of picking up that sound. Instead of traditional dictation in which we exhale while facing a microphone, it is necessary to place the microphone less than two millimeters from the mouth, usually against the lips, and use ingressive speech which is just whispering while inhaling. The advantage of ingressive over egressive speech is that without air being blown over the microphone, the popping of air gusts is eliminated. With practice, it is as efficient as normal speaking but that practice will probably involve a few dizzy spells from inhaling more than necessary.