
With social media and online services are now huge parts of daily life to the point that our entire world is being shaped by algorithms. Arcane in their workings, they are responsible for the content we see and the adverts we’re shown. Just as importantly, they decide what is hidden from view as well.
Important: Much of this post discusses the performance of a live website algorithm. Some of the links in this post may not perform as reported if viewed at a later date.
Recently, [Colin Madland] posted some screenshots of a Zoom meeting to Twitter, pointing out how Zoom’s background detection algorithm had improperly erased the head of a colleague with darker skin. In doing so, [Colin] noticed a strange effect — although the screenshot he submitted shows both of their faces, Twitter would always crop the image to show just his light-skinned face, no matter the image orientation. The Twitter community raced to explore the problem, and the fallout was swift.
Intentions != Results

Twitter users began to iterate on the problem, testing over and over again with different images. Stock photo models were used, as well as newsreaders, and images of Lenny and Carl from the Simpsons, In the majority of cases, Twitter’s algorithm cropped images to focus on the lighter-skinned face in a photo. In perhaps the most ridiculous example, the algorithm cropped to a black comedian pretending to be white over a normal image of the same comedian.
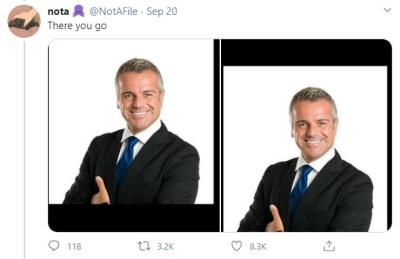
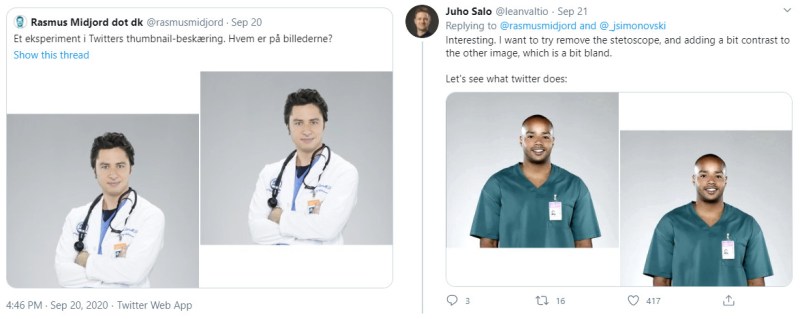
Many experiments were undertaken, controlling for factors such as differing backgrounds, clothing, or image sharpness. Regardless, the effect persisted, leading Twitter to speak officially on the issue. A spokesperson for the company stated “Our team did test for bias before shipping the model and did not find evidence of racial or gender bias in our testing. But it’s clear from these examples that we’ve got more analysis to do. We’ll continue to share what we learn, what actions we take, and will open source our analysis so others can review and replicate.”
There’s little evidence to suggest that such a bias was purposely coded into the cropping algorithm; certainly, Twitter doesn’t publically mention any such intent in their blog post on the technology back in 2018. Regardless of this fact, the problem does exist, with negative consequences for those impacted. While a simple image crop may not sound like much, it has the effect of reducing the visibility of affected people and excluding them from online spaces. The problem has been highlighted before, too. In this set of images of a group of AI commentators from January of 2019, the Twitter image crop focused on men’s faces, and women’s chests. The dual standard is particularly damaging in professional contexts, where women and people of color may find themselves seemingly objectified, or cut out entirely, thanks to the machinations of a mysterious algorithm.

Former employees, like [Ferenc Huszár], have also spoken on the issue — particularly about the testing process the product went through prior to launch. It suggests that testing was done to explore this issue, with regards to bias on race and gender. Similarly, [Zehan Wang], currently an engineering lead for Twitter, has stated that these issues were investigated as far back as 2017 without any major bias found.
It’s a difficult problem to parse, as the algorithm is, for all intents and purposes, a black box. Twitter users are obviously unable to observe the source code that governs the algorithm’s behaviour, and thus testing on the live site is the only viable way for anyone outside of the company to research the issue. Much of this has been done ad-hoc, with selection bias likely playing a role. Those looking for a problem will be sure to find one, and more likely to ignore evidence that counters this assumption.
Efforts are being made to investigate the issue more scientifically, using many studio-shot sample images to attempt to find a bias. However, even these efforts have come under criticism – namely, that using an source image set designed for machine learning and shot in perfect studio lighting against a white background is not realistically representative of real images that users post to Twitter.
Twitter’s algorithm isn’t the first technology to be accused of racial bias; from soap dispensers to healthcare, these problems have been seen before. Fundamentally though, if Twitter is to solve the problem to anyone’s satisfaction, more work is needed. A much wider battery of tests, featuring a broad sampling of real-world images, needs to be undertaken, and the methodology and results shared with the public. Anything less than this, and it’s unlikely that Twitter will be able to convince the wider userbase that its software isn’t failing minorities. Given that there are gains to be made in understanding machine learning systems, we expect research will continue at a rapid pace to solve the issue.














I still find it a little creepy that android phones do facial reconstruction when you try to crop an image and there’s no way in the settings to turn off the functionality.
[ ^^^ And the auto correct is still horrendous. ]
AI downfalls like these are going to have very interesting and controversial implications in field like autonomous driving.
That is a scary outlook.
Eh.. as long as I’m not the one driving
No you’ll be the one getting run over in the street! You don’t want AI accidentally cropping you out as an obstetrical because it doesn’t recognize your skin tone!
“obstetrical”
You just gotta luv otto carrot!
Sensor fusion where not all one’s eggs are in the same basket.
+1
Can someone explain what exactly I’m supposed to be seeing here? All I’m seeing is a bunch of duplicate images where the left or right is higher than the other image…
Yeah. Less than perfect images were chosen for this article.
The gimmick is you make a very long image, with two people. Like a strip of individual photos. B/c the aspect ratio is too long, it has to crop. The issue is the resulting image.
The images chosen here are all “afters” with no “befores”, which hides the issue… Hold on.
Before:
After:
And then you run it with top/bottom switched and find the same result. And then you run it with one white guy in the middle of 10 black guys, and you get the same result.
I have no idea if the “positive” results displayed on Twitter were cherry-picked or not, so I’m a little hesitant to draw conclusions. But these surely do demonstrate the effect.
If the above is legit, makes you wonder about the training dataset and lack of testing/quality control. As already mentioned, software does not exhibit “racism“, but that does not keep social media from commenting.
The article goes into detail that there was actually *quite a lot* of testing, including for skin-tone bias. The problem is always one of determining whether your testing set is actually representative or not.
And it gets even trickier when machine learning is in the mix, because you don’t actually know what the network is really cuing on. For all we know they had a full mix of white and coloured faces in their test sets, but the algorithm actually keyed on a subtle correlation in those images that was not apparent to the developers. The canonical example was the old-school neural network which was trained to detect tanks in photos, but in reality all the photos that had tanks in them were shot on cloudier days than the ones without them… so that’s what the network keyed on.
Quality control?….. LOL… corporations don’t bother, they know their users won’t complain enough to leave…. hasn’t been any quality control since the “cloud” appeared… they know they don’t need to.
How classy of you to use Lenny and Carl for illustration <3
Twitter crops them within your timeline, so you see an image of Carl, tap it, then you see the full image. THe full image would be your before image.
I meant “before Twitter crops the image”.
There’s a before in the article right in the middle – with the two stock photos.
The source images are just below the title “INTENTIONS != RESULTS”, I would laugh if they’re inadvertently being cropped by WordPress
Ah! I finally get it. The problem is that the background of hackaday is nearly black and those 4 portraits arranged in a single file are seperated by a bunch of black, which blends into the background making it look like 4 individually cropped photos arranged on the screen for whatever reason.
I was in this camp too. I thought that was a glitchy matrix rather than two strips.
It’s one of those examples where once you know what you’re looking at, it’s obvious, but beforehand it can be ambiguous.
The example would have been stronger with a single strip image, but then it’s hard to format in the article, as evidenced by the ugly scrolling I had to do to even get down here…
The test images are bigger than the area twitter uses to display them with two people of different skin colour
So there is an algorithm that crops the images.
This algorithm could just use the center of the image or could focus on something ‘interesting’.
And this is where people with lighter skin are prefered and so we are talking of some kind of racism.
The reason could simply be that lighter skin colors have more contrast, so that faces are easier to identify.
Funny thing is that, at least in the analysis of TV studio images of black and white peoples’ faces, the overall colour vectors are the same just the amplitudes of the colour vectors are different, the overall contrast is the same just not in the same areas. Sloppy, sloppy programming by ignoramuses for a customer who only looked at the contract price.
No, let’s be clear. The issue is that the person who coded/tested the algorithm clearly didn’t test it with mixed race images.
There’s nothing fundamentally “easier” about one or the other. Light skin might have more internal contrast, dark skin better external contrast against light backgrounds. Whatever. There are a million ways to try to identify faces. It might even be black-box, like an AI-type algorithm that was fed images of varying race, but no one looked at bias in the metrics it produced.
The “code” reason’s unimportant. The fundamental reason’s lack of testing.
High internal contrast makes it fundamentally easier.
You can improve the performance for dark faces, but that will also improve the performance for light faces, so for the edge cases, the light faces will always do better.
Must be nice being able to assert absolute certainty without any evidence.
@pelrun…. bad code is easy to spot…. it doesn’t work properly….. LOL… guess you are the only one not understanding such a simple concept huh? Twitter doesn’t have any quality control, they don’t need to, since the same quality standards apply to the users.
No, you’re not understanding.
Suppose you start with *all* dark skin tones, and run it through machine learning. The code won’t key on internal features at all because they’re less significant. It’ll key on something else. Who knows what. Maybe the tone itself. It doesn’t matter: it’s a learning algorithm. Whatever it “comes up” with is completely valid based on it’s training sets.
Obviously that algorithm would quickly show up as biased, and someone might dissect the metrics and say “oh, see, it’s keying on X, that’s the problem.” But that wasn’t the problem: the problem was the lack of testing, because it was the testing that *made it* key on that.
If it’s using an algorithm that can locate features in light skin tone and it’s keying on that, it’s wrong. It’s as if it had a picture of Rick Astley in it, and cross-correlated on that. The guy who coded could say “well, Rick Astley’s face just has *so much* more contrast, it’s easier to find it.” Yes, that’s a ludicrous example.
The problem’s not “subtle.” It’s pretty ludicrously bad. Which means it was a testing failure, not an algorithmic failure.
It’s also not surprising: the bias testing probably checked for bias in the *results*, not bias in the confidence. (Statistical) bias likes to hide: you squash it somewhere and it just distributes itself into errors or something. They didn’t train the algorithm to identify all faces with equal accuracy, they likely trained it to identify faces with *highest* accuracy. Big difference.
@Pat: I think you’re working in the right direction, but are putting it on testing rather than the fittness criterion used in training the NNet.
It’s that their loss function treats a misclassification of Hackaday author as “tobacconist” (https://hackaday.com/2017/06/14/diy-raspberry-neural-network-sees-all-recognizes-some/ halfway down) the same way that they treat a horribly offensive misclassification.
To the training algo, it’s just “wrong” but to people, it’s outrageous.
Google’s workaround for their NNet was to stop recognizing gorillas at all, because they occasionally, very occasionally, were classifying black people as animals. That’s basically the same as putting an infinite penalty on that particular misclassification pair, which seems fine to me, honestly. Too bad for people with photo albums of gorillas, though.
The problem is that there must be a ton of horrible misclassifications that we just haven’t discovered yet. And it would take a team of incredibly sensitive humans, who were also very inventive in imagining the new ways that the NNet can misclassify / mis-crop / or whatever to dream up all the bad outcomes and appropriately penalize them.
I’m not sure that the problem is even solvable. And it offends people when they get it wrong. If I were running one of these big classifiers right now, I would not be sleeping very well.
Then again, apparently it took 2 years for people to notice…
Yeah, that’s really what I meant. The problem is in how they decided what was “right.”
This is really common in machine learning, and a comment on a previous “upscaling with machine learning” said it well: when ML goes wrong, it goes really, really wrong.
Mainly I think it’s because people train for highest accuracy, rather than fewest mistakes.
> Mainly I think it’s because people train for highest accuracy, rather than fewest mistakes.
Not just an issue with NN models.
This is also how the British “First Past the Post” voting system works. It optimizes for the “most wanted” rather than the “least unwanted”. So you end up with 70% of miserable people in exchange for making the 30% who voted for the winner slightly happier – rather than something like “Alternative vote” which iteratively discards the least popular people until you end up with the candidate that the highest number of people can live with.
It seems to be a common tendency to optimise this way.
In digital photo processing and editing, it’s well known that darker photos hold more pixel data than light photos with blown out highlights. Want a photo with more detail and better digital darkroom editability? Stop down your camera around half to one stop of exposure. The problem here isn’t that darker = easier to mistake, it just means the algorithm is flawed. Figure out where it’s going wrong, then fix it. Sure training could be part of the problem, but its a problem that can be solved by either improving the algorithm or by increasing the training data to include a variety of photo quality settings.
I’ve come across a few digital photos that appeared to be of a well lit subject with an almost totally black background. The file sizes were pretty large. After some level adjusting… there’s a whole crowd of people “hidden” in that apparently solid black background.
“Sure training could be part of the problem, but its a problem that can be solved by either improving the algorithm or by increasing the training data to include a variety of photo quality settings.”
I don’t think it’s really a problem in the training data or algorithmic. It feels more like a “wrong goal” issue – as in, they’re training it to the wrong goal.
Imagine how they probably tried to train the algorithm – they likely aimed for the highest accuracy in identifying *single* faces. Give it a bunch of things with faces, bunch of things without, maximize the accuracy of identifying the faces in the “face” sample. But that’s not what they should’ve been training on. They should’ve been training on multiple faces, and had the algorithm evolve to *miss the fewest faces*.
In other words, the false *negative* rate matters much more than the false positive rate. If you’ve got a face in a picture and it accidentally identifies 2 faces (one real, one false positive) – big deal. It’ll be a little oddly cropped/resized, but who cares. The important thing’s still in the picture. However, having 2 faces in the picture and *missing* one is horribly bad.
Don’t you get it? There’s a clear bias towards left and right photos being higher and lower. It’s all in the photos provided. You just have to ignore all the text confusing the situation.
Its easy to get… bad code, unskilled programmers write garbage code…. its the old saying “Garbage In, Garbage Out. 10 seconds of examination of twitters code shows the lowest bidder, lowest skill set workers clearly.
I feel like this shows a misunderstanding of what people mean by “racism” when they talk about issues like this. Something can still have “racist” outcomes even if it’s not designed to be racist (bias in training datasets in a big one).
Is it a big deal that twitter’s cropping system might not detect black faces? Probably not, in the grand scheme of things. But can it be called “racist”? Well, the system itself is obviously not intentionally racist, but in the outcomes of the system it shows a preference for white faces. This is what people mean when they call it “racist” or say that it shows racial bias – in the outcomes of it, it does. When people talk about this in relation to people’s views they call it unconcious bias, in the case of an AI I’m not sure you can use that term because the thing isn’t concious, but it’s the same deal
I agree completely. It’s highly unlikely that a programmer sat down and intentionally trained the algorithm to prefer images of one race over another, and we’ve seen this kind of bias in other ML applications based on the datasets they use. But engineers are responsible for the results of this, even if this specific feature is inadvertent.
> But engineers are responsible for the results of this, even if this specific feature is inadvertent.
inadvertent – not resulting from or achieved through deliberate planning.
Calling it a feature suggests intent, though. If this was inadvertent then it’s a bug/error.
Should we blame a chip designer (silicon integrated circuit) if an inadvertent aspect of the design results in the product failing after 5 years of use because some aspect of it wasn’t as resilient as the rest due to the manufacturing process?
Is it a bank’s fault if the poor have a hard time taking out loans because they are higher-risk borrowers by definition?
I agree that the problem should be fixed and that someone (or multiple) people are technically responsible. But realistically it should be Twitter’s (for examples the: manufacturer of chip, possibly the government respectively) responsibility to make sure it gets fixed.
> Should we blame a chip designer (silicon integrated circuit) if an inadvertent aspect of the design results in the product failing after 5 years of use because some aspect of it wasn’t as resilient as the rest due to the manufacturing process?
Of course. They get paid to keep stuff like that from happening. That would be a serious fuckup and could definitely be career limiting.
And if somebody at Twitter failed to pick the right traning data or failed to apply the right test cases, then yes, it is their fault.
… and the *reason* they didn’t have the right training data or the right test cases was probably that their own mental model of “face” defaulted to “white face”, and they didn’t do anything to correct that. Which is racist by the current definition. No, it’s not caused by active intentional animus, but that’s the *old* definition of the word. Words change their meaning. The same thing happened to “hacker”. It’s only a problem when people use it dishonestly, like by applying the connotations of the old meaning to the new one. That does happen, and sometimes it’s intentional. But the change is pretty permanent regardless.
Anyway, whatever words you want to use, it’s not really OK if your biases, conscious or unconscious, lead you to fuck up the product. Especially not if you fuck up the product in a way that disproportionately affects some users. *Especially* not if other people fucking up the same way you did has been in the news for the last several years. If you don’t keep current and learn from stuff like that, you’re not doing your job on pure, simple engineering criteria.
This is exactly why I celebrate the death of Nobel every year, he should be so sorry for creating TNT. /s.
I think we are white washing the term a bit here no? If we call some accidental data processing side effect the same as someone flying the Nazi flag while burning someone at the cross while wearing a white hood. Emmm maybe these things are not the same and we should reserve different language for different things.
Bias in training data sets is a thing but let’s not assume even the formation of the dataset came from racism. What if a Chinese company collected the origonal dataset. Well there are not a lot of people with dark skin complextions or african bone structure in China so shockingly the dataset will be biased to identify the differences among chinese individuals. This was simply a by product of convenience nothing evil, and is it reasonable to force all companies to adhere to all possible variances of people in their training data. What if the dataset has a bias to a very specific sub culture found only in the forests of Brazil. It’s not exactly reasonable to expect them to capture this data point so you know shit happens.
The Own-Race Bias for Face Recognition is a very real thing. It stems from nothing more then as a baby I looked mostly at my parents and relatives who are from a ethnicity to myself so I will be better capable at picking out differences among individuals of that ethnicity. This is true of nearly everyone (excluding adoptions which are a very interesting case study). It’s well known that african, asians, europeans, and native americans have very different defining facial features and so I learned on a specific trait which simply doesn’t help when looking at other ethnicities. This is a bias but it is not a malicious one and only my actions from this can be malicious. Twitter can have this accidental bias which no reasonable training dataset would have picked up, this does not make them evil, them refusing to address the problem would have been but that is clearly not what’s happening.
How exactly is accidental racism not racism?
Because it’s not racism at all, at least not in principle. It’s not that “accidental racism != racism” is that “problem discovered with algorithm != racism” at least not intrinsically.
Just from a quick google search:
Racism – prejudice, discrimination, or antagonism directed against a person or people on the basis of their membership of a particular racial or ethnic group, typically one that is a minority or marginalized.
An algorithm that reliably fails to detect all faces is a faulty algorithm, but just because it seems to prefer “white” faces over “black” ones doesn’t make it racist. The program itself doesn’t necessarily know anything about race, only about colors in an image Presumably it could have issues with other dark colors as well or persons with intermediate skin tones or who are substantially in shadow. If you subtract darker colors or do something of that nature to try and get rid of things that aren’t people or faces you might end up removing someone with very, very dark skin. The problem may be quite pronounced with a very dark skinned person and a very light skinned person in the same shot.
Part of the problem here is trying to attribute racism to an algorithm which isn’t alive, much less sentient or sapient. However, when stuff is based on AI and a training data set, I think any inherent bias in the training set could show up in the results. So If any responsibility is to be assigned, then it would fall on the developer and whoever made the training set. But that doesn’t mean they did anything specifically wrong or illegal.
I think the person you replied to is correct though. By which I mean that it is absolutely necessary not to jump to conclusions simply because of confirmation bias. Probably Twitter should just return to a more predictable form of cropping until it figures out what’s wrong with the algorithm. Once they say they’ve figured it out and fixed it we should be extra vigilant to make sure it’s actually fixed.
“Regardless of this fact, the problem does exist, with negative consequences for those impacted. While a simple image crop may not sound like much, it has the effect of reducing the visibility of affected people and excluding them from online spaces. ”
Flip side of the coin. Less likely to fall into the surveillance state trap. Sure we want to fix this?
It’s only a problem for data miners and fascist states. I agree, lets leave it in and expand it to all races. 2 birds, 1 stone.
thats sarcasm right? unless you think Australia is a fascist state. I wont even mention all the cameras in Europe.
Europe? Or the UK?
B/c here on the mainland, we have quite strong laws about collecting images in public places. Tesla is currently under suit, for instance, b/c their cameras are always on, filming people without their consent, and shipping the data off to the US. (Where privacy laws are essentially nonexistant.)
Look on Google StreetView. See large swaths of urban environments blurred out in Europe? That’s b/c they were forced to respect peoples’ wishes to not be imaged. See the same elsewhere?
I don’t know where you’re from, but instead of complaining, you should probably be lobbying for better laws wherever _you_ are.
But it _is_ racist. It’s preferring one race over another. That’s the definition of racism.
“Racist” isn’t some monolithic identity, it’s anything that favors or degrades one race over another. Any action, any policy, any statement, any process.
To call this “not racist’ either demonstrates that you do not understand what racism really is, or says some very unpleasant things about your beliefs.
That is not the definition of racism, the stated definition is the connotation, not the denotation. You could categorize this under racial discrimination, but it is an algorithm, not a sentient being.
Simple fix. Don’t use Twitter, Fakebook, etc. And their fake “AI”.
I concur, Twitter is a virtual lunatic asylum at the best of times, and f.book is just the low IQ version of it.
I think the article covers the question of intentional or accidental bias. The question is what do you call software that can so clearly generate racially discriminated images. The problem it causes is so reminiscent of racism that it will have to be very effectively, and immediately changed to avoid an accusation of very real racism.
If an accounting program was liable to arbitrarily ‘crop out’ prime number amounts of money entered into the program it would be justifiably criticised even if the fault was due to some obscure ‘dang thing’.
> Your comment is awaiting moderation.
>
>Software glitch/error… yes. Problem, yes… Racist, give me a break. It’s an inadvertent software glitch due to the differences in human beings, light reflection and detection. I am so sick of every dang thing being chalked up to racism… but only when it affect black folks.
Amazing. Not a single unkind thought, NSFW language, or untruth, yet my comment is “awaiting moderation.” I guess tolerance and Freedom of Expression is only for those who hold popular ideals.
Robin, this deed was undoubtedly performed by the wizard of ominous omelettes on the right!
“Some users attempted to put the cause down to issues of contrast, saturation, or similar reasons. Whether or not this is a potential cause is inconclusive. Regardless, if your algorithm will only recognise people of color if they’re digitally retouched, you have a problem.’
Well, these users may or may not be searching for solutions or scapegoats or whatever, but looking for the cause of the problem is the first step in correcting the problem. Why does this caption seem to ridicule the idea of looking for answers to problems?
Back in 2008 my tram was trying to use one of then popular “face detection” algorithms. It had exactly the same issue – would not detect any faces of black people. Part of the code was trying to do skin color detection and was rejecting faces with dark skin tones. It was from a reputable company and I’m guessing some vestiges of that code are still around.
You bet it is: They most likely just used something from “scikit.learn” or “Theanos” like thousands did before them.
That being the case, The Algorithm is likely to be solid and high quality, The Application however is shoddy and garbage.
Your account has been suspended.
On what grounds?
Additional chromosome.
There are definitely some places where algorithms have problems processing data, because the training/testing data wasn’t sufficiently varied. I’m not sure that an odd image, with way too much whitespace, that forces the algorithm into an either/or decision is particularly useful in trying to track those bugs down. The capture from Zoom is definitely more interesting, but I do wonder if the missing head was a factor in which face to focus on. The face that shows up twice must be the most important one, right?
The image from Zoom is obviously a bug in Zoom. Is it a bug that didn’t get noticed because the feature was primarily tested using white guys? Yeah, that’s plausible. Let’s treat it like the bug it is. Make sure your test data is sufficiently varied. This isn’t a controversial concept, nor should it be treated as a moral failing. It’s a bug that needs to be fixed.
To be fair, Lewin does a good job at this. The technical term “bias” is quite accurate, but unfortunately “bias” has been used to describe people, where it now implies “racism”. The term being overloaded, combined with the current tension in certain parts of the world, make for quick judgments and misunderstandings.
Where people get frustrated, is when bugs like this are treated as moral issues, and then used as fodder to attack. Machine learning is hard to get right, and more often than not, even the programmers that worked on it don’t understand the decision process the model is using.
If you’re interested in learning about the tools being developed to explore AI bugs like this, maybe check out the FLOSS Weekly podcast we did about RedHat’s tool, Trusty AI https://twit.tv/shows/floss-weekly/episodes/593
twitter using lowest bidder contract programmers will have been the root cause. Garbage In… Garbage Out, its the corporate way…. zero quality control, the user is the Alpha/Beta tester…. we are back to the first microsoft days.
Who is twitters quality control team?….. all their Users.
That reminds me of the rachelbythebay link that was posted here a couple of weeks ago.
(I forgot the actual blog entry)
(about another large “unnamed” organization whose programmers seemed to have no clue about the importance of return values).
“The image from Zoom is obviously a bug in Zoom. Is it a bug that didn’t get noticed because the feature was primarily tested using white guys? Yeah, that’s plausible.“
More likely it was Chinese guys, as it was a Chinese company originally.
What happened to Hackaday? You guys used to show a certain understanding on how things works under the hood, a certain competence often due to being directly involved with relevant fields… and you come out with articles that basically say “AI is racist”? What the hell?
I think you’ve jumped to your own conclusion and it’s wrong. This article clearly discusses a bias in the image cropping algorithm — it is much more likely to have one type of outcome than another, at least in the types of images tested (and Lewin notes that selection bias may be in play for this testing).
FYI,
I just want to add here, that the [Ren] that posted the above comment, is not me, the [Ren] that is (another) thorn in [Mike Szczyx]’s side. B^)
As [Mike] can tell which email address originates each post, he already knows that it is not me B^)
But a bug /is/ a moral issue. At least, for us engineers, I hope it is.
Human lives and all that.
Good point!
What does it do with color inverted images?
These examples all seem rather fake – I’ve never posted a photo of two people one above the other like that. I’d imagine twitter tested with more realistic family / team photos, and this style of image is confusing the AI?
Gotta love problems in technology nobody asked for. Are people posting so many selfies that they don’t even have time to crop them?
As far as facial recognition, that’s use to track and oppress people, so “people of color” got the better end of this deal. Maybe instead of shaming companies for bias in their algorithms we should be asking why they are doing this in the first place!
And no one asks why one needs automatic cropping?
I mean, if people shared less garbage, and focused more on interesting infos and not what they eat at lunch, maybe the users could crop themself the images…
The problem is not that the AI is biased or not, it’s that Twitter needs to automate the task because there is too much stuff do / people don’t take time to post quality content.
Lastly, why not simple use a scaled down image or a fixed area cropped one?
Could even be use artistically if the restrictions are well known (like scaled down image is something but full size one is an oher thing, or top of the image is a hook that apears on preview, and the full image gives more info.
Just my 2 cents…