
Thirty-five years ago, radiation alarms went off at the Forsmark nuclear power plant in Sweden. After an investigation, it was determined that the radiation did not come from inside the plant, but from somewhere else. Based on the prevailing winds at that time, it was ultimately determined that the radiation came from inside Soviet territory. After some political wrangling, the Soviet government ultimately admitted that the Chernobyl nuclear plant was the source, due to an accident that had taken place there.
Following the disaster, the causes have been investigated in depth so that we now have a fairly good idea of what went wrong. Perhaps the most important lesson taught by the Chernobyl nuclear plant disaster is that it wasn’t about one nuclear reactor design, one control room crew, or one totalitarian regime, but rather the chain of events which enabled the disaster of this scale.
To illustrate this, the remaining RBMK-style reactors — including three at the Chernobyl plant — have operated without noticeable issues since 1986, with nine of these reactors still active today. During the international investigation of the Chernobyl plant disaster, the INSAG reports repeatedly referred to the lack of a ‘safety culture’.
Looking at the circumstances which led to the development and subsequent unsafe usage of the Chernobyl #4 reactor can teach us a lot about disaster prevention. It’s a story of the essential role that a safety culture plays in industries where the cost of accidents is measured in human life.
Anatomy of a Disaster

Two years before the Chernobyl plant disaster – on the night of December 3rd, 1984, over two-thousand people in the city of Bhopal died when a lethal cloud of methyl isocyanate (MIC) was accidentally released by the nearby Union Carbide India Ltd chemical plant. In the subsequent years, over a thousand more would die, and over half a million people were injured. To this day the chemical pollution from the plant has rendered the soil and ground water around the now abandoned plant a hazard to human life, even as people continue to live in the area.
The Bhopal disaster was the culmination of a lack of maintenance, defective safety equipment, as well as an absence of a safety culture. This combined allowed water to run past defective valves into an MIC tank, causing the production of the lethal gas in an exothermic reaction. As the US owners of the plant (today The Dow Chemical Company) failed to clean up the site when the plant closed in 1986, this task is now left to local governments.
The 1986 Chernobyl plant disaster shows many similarities, in particular the lack of a safety culture. This began with the design of the RBMK (reaktor bolshoy moshchnosti kanalnyy, or “high-power channel-type reactor”), where natural uranium was chosen to avoid the cost of 235U enrichment. This meant a physically larger reactor, leading to the decision to skip a containment vessel which competing designs (e.g. VVER) did include, as it would be too large and too expensive.
Although the RBMK design does feature many safeties, including a split main cooling loop, an emergency cooling system (ECCS), and a SCRAM emergency shutdown system, there are no provisions that keep operators from disabling these safeties at will. Thus, what should have been a simple emergency power experiment with the steam generator (using its inertial momentum to power the circulation pumps) ended up in disaster.
Playing Games with Reactor Reactivity
In every light water reactor (LWR) design that uses plain H2O for cooling of the reactor core, there are two main parameters which determine whether the reactor is performing nominally, or under/over operating conditions. These pertain to the reactor reactivity: the number of neutrons present at any given time with the appropriate velocity (neutron temperature) for the neutron cross section of the target fuel.
In the case of uranium-235, so-called thermal neutrons are required, yet the fissile reaction produces many faster neutrons (‘fast neutrons’). Fast neutrons can be slowed down to become thermal neutrons by using a neutron moderator. This process increases the reactivity of the reactor. This process is then counteracted by neutron absorbers, which include the water as well as any control rods, which are often made of boron carbide.
Most LWR designs use light water for both moderating and capturing neutrons, which also means that if the reactivity increases, the water boils quicker, which creates more steam. This steam has reduced neutron moderation capacity, which in turn reduces the number of available thermal neutrons and thus creates a negative feedback loop. This is in essence a negative void coefficient.
The RBMK as an early Generation II design on the other hand has a lot in common with the prototypical Generation I graphite pile reactors, including the use of graphite as neutron moderator. While this allowed the use of natural uranium, it also meant that the RBMK ran with a positive void coefficient: as the water in the reactor cooling channels boiled and created voids, the neutron capture capacity decreased, while the moderating effect remained unaffected, creating a potentially run-away reaction.
This trade-off was deemed acceptable as it allowed the RBMK design to output thermal power far beyond that of Western reactor designs of the time, and it was assumed that a well-trained crew would have no problems managing an RBMK reactor.
As has been pointed out ad nauseam with e.g. the sinking of the Titanic, marketing and management regularly trumps engineering, and any disaster that can be averted by proper maintenance and training becomes an inevitability in the absence of a safety culture.
Inviting Murphy
When Chernobyl-4 was scheduled to be turned off for maintenance, it was selected and prepared for the steam generator experiment by disabling the ECCS safety. However, right before the experiment was supposed to begin it was decided to leave the reactor running for an additional 11 hours as the grid needed the extra power. During this delay, the day shift which was supposed to have carried out the experiment was replaced by the evening shift, all of whom consequently had to manually regulate the water valves due to the disabled ECCS.
When the night shift — who had arrived at work expecting to manage a shutdown and cooling reactor — were told to carry out the experiment. This meant reducing the reactor from full power to about 700 – 1,000 MW thermal before cutting the steam to the generator.
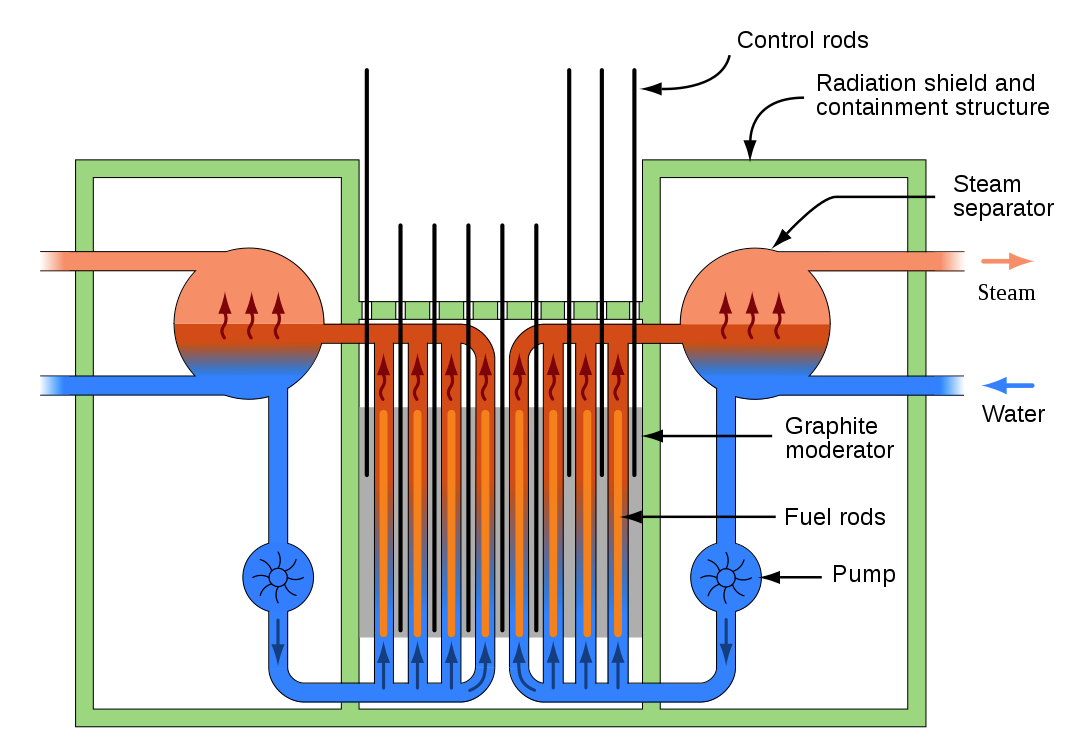
A quirk of the RBMK design is that it’s highly unstable and hard to control at low power levels. Between the positive void coefficient, the flawed design of the control rods, and the formation of neutron absorbers such as xenon-135 as a by-product, the reactivity of the #4 reactor dropped to less than 100 MW. This caused the operators to remove more and more control rods (including rods from the automated control system) in a bid to increase reactivity. This allowed reactivity to slowly increase again to levels somewhat close to those required by the experiment.
Coolant flow to the reactor core was increased to create more steam, but this decreased the reactivity and thus two of the pumps were turned off to increase reactivity again. In this configuration, with virtually all control rods removed and all safeties disabled, the experiment was wrapped up, even as the dropping power from the slowing generator caused less cooling water pressure. As a final step the decision was made to use the SCRAM feature, which would fairly rapidly insert the control rods to stop the reaction.
While these rods were being inserted, they drove the water out of their channels, increasing voids, while the graphite section at the tip of each control rod further increased reactivity. As a result of the increased reactivity at the bottom of the reactor, reactor thermal output spiked to an estimated 30,000 MW of 3,000 MW nominal. The cooling water was instantly boiled off and the zirconium fuel rod cladding was melted, causing hydrogen gas to be generated as it came into contact with the steam.
The first explosion by super-heated steam erupting out of the core flipped the shield on top of the core and blew out the roof of the building. A second explosion a few seconds later — likely caused by exploding hydrogen gas — ripped the reactor core apart and terminated the nuclear chain reaction. All that was left of reactor #4 were radioactive bits of the core slung around everywhere and super-hot corium — a lava-like ooze of many different materials from the destroyed core — melting its way into the basement of the reactor building. Meanwhile, the graphite of the core caught on fire, causing the fall-out plume that would be detected first in Sweden.
End of an Era
Today, nine RBMKs are still active, all of them in Russia. The remaining three RBMKs at the Chernobyl plant were shut down over the next few decades, after all remaining RBMKs had been tweaked using the lessons learned from Chernobyl-4:
- The use of slightly enriched uranium fuel to compensate for additional control rods.
- More neutron absorbers to stabilize the reactor at low power levels.
- Faster SCRAM sequence (12 seconds instead of 18).
- Restricted access to controls that disable safety systems.
The main effect of these changes are that the positive void coefficient is significantly reduced, the reactor is much easier to control at low power levels, and there is much less freedom for operators to ‘improvise’.
With the RBMK and similar designs now firmly out of the public’s favor, the competing VVER became the main reactor design that would come to power Russia. In its modern VVER-1200 form, the VVER is a Generation III+ design that uses light water for both moderating neutrons and cooling, as well as neutron absorption. As a design that follows international safety standards for nuclear reactors, it will be replacing the remaining RBMKs at Leningrad, Kursk, and other plants over the coming years.
It’s Safety Culture, Silly
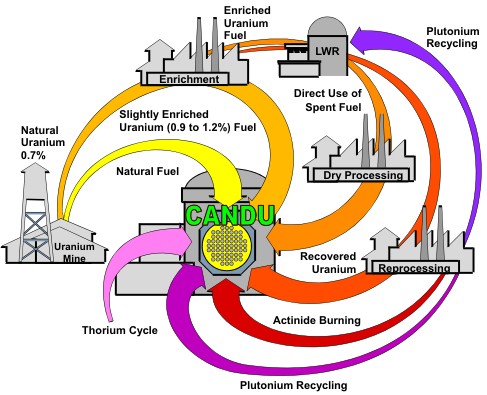
As an interesting counter-point to the notion that it was the positive void coefficient that made the RBMK so dangerous, there is the CANDU reactor. This is a reactor type that’s so uneventful that the average non-Canadian citizen isn’t even aware that Canada has a nuclear industry and has been exporting these reactors around the world.
Yet the CANDU design used natural uranium originally, while running at a positive void coefficient. Despite this, the CANDU reactor’s active and passive safety features prevent something like the operator mismanagement that happened at Chernobyl-4, or the partial meltdown at the (negative void coefficient) reactor at Three Mile Island. In the latter case, an operator overrode a safety system, in a scenario somewhat reminiscent of the botched Chernobyl-4 experiment.
A similar cause underlies the nuclear accident at the Fukushima Daiichi nuclear plant in 2011, as pointed out in the 2012 Japanese Diet report. A general lack of safety culture, and widespread corruption up to upper government levels led to safety systems not being upgraded, lax adherence to earthquake resistance standards, and failure to implement upgrades recommended by US regulators.

Even so, accidents at nuclear facilities are still exceedingly rare, which makes commercial nuclear power among the safest forms of power generating per TWh. What’s perhaps more worrying is that this lack of safety culture isn’t just an issue in the nuclear industry, but something far more pervasive, as Bhopal and other major industrial disasters show. In the US, the Chemical Safety and Hazard Investigation Board (CSB) is responsible for investigating industrial chemical accidents.
In addition to the official reports, the CSB has also made a number of documentary videos available on its YouTube channel. What these reports hammer home is that safety culture is not something that should ever be taken for granted, or assumed to not be an issue. Despite lacking a totalitarian regime, countries like the US still somehow manage to suffer regular industrial disasters that kill and injure hundreds.
One lesson which the US CSB’s reports teach is that as scary as radioactive materials may appear, something as innocent as saw dust or flour should never be underestimated. Allowing hazardous situations to even exist is the first step towards it escalating into someone’s worst day on the job, bar none.
There’s No ‘I’ in Safety
Nobody wants to be the guy on a team who has to point out the obvious safety issues in a design or procedure. Nor does anyone want to be the person who has to rat out their colleagues for not following safety procedures. Simultaneously, a single person cannot force a company or a country to implement better safety procedures.
When there’s no overarching effort to create, implement, and adhere to safety regulations, it is only a matter of time before the next easily preventable disaster strikes, no matter what form this may take. Although safety regulations aren’t exactly cool or ‘sexy’, they are often the one thing that stands between a boring day at the factory and a flattened refinery or coal fly ash spill that kills dozens and renders a large area uninhabitable.
It’s up to us to not only remember the Chernobyls, but also the Bhopals and similar disasters that took so many more lives and will continue to do so every year so long as we as a society do not make safety culture a part of life everywhere.
Heading image: The New Safe Confinement in final position over reactor 4 at Chernobyl Nuclear Power Plant. By Tim Porter, CC-BY-SA 4.0














If I’ve learned anything from nuclear disasters then it’s that safety warnings should be able to shut down the reactors without the operator being able to override it. “I know better,” policy, and regulations are insufficient safeguards.
I agree. But the issue is trust in the engineers. Nobody with the power to take decisions has any clue what all those engineers are talking about, and have no way to check an engineer’s work for oversights. So for the decisionmakers, it boils down to that they bear all the responsibility on the one hand, but have to trust these wizards (who could make mistakes as well) blindly.
This in itself will always be a recipe for disaster in the long-term.
Most of the time it’s not “I know better”, but “I will be hung o the highest branch of you make a mistake”.
This is like saying autopilots should control failing aircraft. This is not the answer. Having well trained engineers there whenever the system is in operation is the correct answer. These are not the people who are trained to keep the needle in the middle of the meter by moving the big knob, but people who understand the construction and operation of the system.
If you look at the failed automation in the Boeing 737 max, it looks like the thing that kept any of the from crashing in the US was not the automation working, but well trained (above the standards of other countries where crashes did occur) pilots.
An even better option is an aircraft designed to shed components which compromise it’s glide characteristics and don’t contribute to it’s ability to make it to a safe haven without killing it’s crew and passengers. In other words, nuclear systems should be designed to safely stabilize without external intervention wherever possible.
I’m imagining aircraft components falling through people’s roofs.
Thats what made 3 mile island so frustrating. There were several instances during that disaster that had the engineers in the control room just STOP TOUCHING THE DANGED THING, the automated systems would have either SCRAM’d or stabalized the reactor. They kept touching it, thinking “oh I know better” and they kept making it WORSE.
I really recommend “Who Destroyed Three Mile Island?” by Nickolas Means [1].
While your statement (and capitalization) is technically correct in hindsight the operators/engineers alone kinda weren’t at fault while it was happening.
As usual it’s a combination of several factors, many not related to the operators that day, which lead to that disaster.
They actually “knew better”, just for reactor a fraction of the size and a slightly different main objective (nuclear sub).
I can recommend all other presentations from him as well (Eiffel Tower, Race to Mach 2.0, Original Skunkworks, Building on Stilts, …)
https://www.youtube.com/watch?v=1xQeXOz0Ncs
The flawed MCAS system in the Boeing 737 Max only operates when the plane was being fliown manually. There were no accidents in the US because they took off under automated thrust management by the navigation computer. Required in the US to mininimize take-off noise.
That’s good until you realise that there’s a flaw in the design and the safety system is causing the problem – or things have broken and the safety system is no longer doing what it was supposed to.
A qualified engineer on site should be able to override things.
“the safety system is causing the problem”
Exactly. The tips of the control rods were graphite which when they were all dropped into the reactor in a SCRAM sequence caused the event within a reactor that had already been perfectly primed for the catastrophic event by grossly incompetent operation. This control rod issue was a known flaw that had been covered up and it was eventually corrected in the remaining reactors of that type.
Exactly what happened and how it happened is beautifully explained in great detail in the final episode of the outstanding HBO series, “Chernobyl.”
I wouldn’t trust the series though, since it takes too many liberties in explaining the details – such as pushing the point that the reactor could have undergone a nuclear explosion worth several megatons.
Good article, you earned it, here is your likidator medal:
https://www.ebay.co.uk/itm/141393107528
Titanic and coal bunker fire, as well as rivets.
Twenty years in non nuke steam power plants, the common connection is the operator pushing the buttons.
Next step downhill is the engineer changing “Specs” of steam boiler internals, in a misguided effort to save money.
A third guilty party is the purchasing agent, that actually allows the engineer to buy cheaper internals.
I could go on, however, it serves little purpose, and whistleblowers always come to a bad end.
As a previous purchasing agent, I object to the statement allowing the engineer to buy cheaper materials. I was told by engineering the specifications they needed, and subsequently told by finance how much to spend, my task was to buy materials at the cheapest price that would make the specifications
Is it tested to see if it meets those specifications?
And There You Have It..
Only when the cost for the tests is already factored into the money reserved. Otherwise, things are just mounted as-is, and “damn the torpedoes”.
And did we trust the EU certificate rather than re-testing the cladding to U.K. standards?
I only heard about this cladding debacle recently, so forgive me if I’m wrong, but weren’t the UK standards the problem? Everywhere else limits combustible cladding on buildings taller than more or less 20m, but the UK does (did) not. There’s no test to perform when the standards have no limits.
Is this some kind of pro-Brexit story that was spread to validate the vote?
I could not find any reference to EU in the article: https://en.wikipedia.org/wiki/United_Kingdom_cladding_crisis
All it says is “In 2006, changes to UK building regulations, intended to facilitate greater energy efficiency at lower cost, arguably made combustible cladding and insulation in buildings over 18m legal, and opened the way to its widespread use.”
The heart of the Grenfell cladding, was that the manufacturer had fudged the safety test. They knew that that type of construction was flammable, covered it up, and carried on selling it with what was effectively a fake certificate. There were also flaws with the landlords’s policies, among others. What has come out of the inquiry, which is ongoing, is that there was no proper safety culture involved. Lots of buck passing went on, which is showing up as “we thought [INSERT NAME OF SOME OTHER PARTY HERE] had done it.” A ship of knaves and fools!
I’ve worked on hardware where beancounters forced purchasing staff to buy “something cheaper”, in one case to save 10c off a component, but they bought the wrong part that didn’t work in the circuit. So that was quite obvious.
Now if it’s metalwork you are talking about, it might sort of work OK if you use something cheaper, but will it fail under load, catastrophically? And who is interpreting the specifications? Not an engineer by the sounds of it.
True story.. We were scheduled to do a pre-heavy load turn around, each 6 months. It makes sense to avoid tear downs during peak earnings periods. Cheap super heater tubes purchased, saving tons of money. (Ha!) 3 months later, the tubes ruptured, system was down for 1 1/2 months losing $1,000.00 per hour, plus the repair cost, parts a labor. Didn’t work out too well. Lucky us, it was not a nuke.
Where was this? What AI/agency and regulator? Code? Mill certs for the tubes?
This screams more to the story.
@cliff More to the story? Sure.. Local government has no oversight. The do whatever they want.
That’s the story. Engineer changed the metallurgy in the tubes in an effort to save $ and perhaps get a promotion. Didn’t work. I’m retired now, so I don’t have to see the stupidity in action every day.
Engineers rarely choose to make something cheaper, if made to do so they’ll usually say “this will increase the risk of failure from 1 in 10,000 to 1 in 100”, it’s for someone else to weigh the risk versus the reward. Often the reward looms large and the risk is some far off chance.
Look at the big dig in Boston. Corruption at it’s finest. Substandard materials were substituted and it did not work out so well. The wiki is an interesting read.
This is where team oriented project review processes such as hazard and operability studies, or even just systematic “what if” analysis, properly documented, and management of change processes, all required by upper management has its absolutely necessary place in the ecosystem.
Even the California debacle, San Onofre, the failure was the superheater tubes. I’m not sure, but I see a trend. And guess what, no one knows who to blame. I’ll leave you to you own guesses.
That the Chernobyl “accident” were due to a lack of safety is a bit of an understatement.
It is well documented that they did a safety test, something that the people originally scheduled to conduct the test had done a couple of times before, though with unsatisfactory results, thereby there were a need of a new test. But at the day of the accident, the test were postponed a couple of hours and the people in charge shrugged their shoulders saying, “the next shift can do the test.”
Even if the next shift had never done it before, had nothing to go on then the documentation provided for the test, all while the engineer in charge were not even following the documentation either. Though, the other engineers in the room were likely shrugging their shoulders saying, “they probably read more about this test than I have, so I better follow their command.”
In a safety driven culture, the test wouldn’t be postponed by a few hours, but rather to the next time the people who have actually trained for it are back.
Though, another part of safety is to not do a live test of anything unless one has considered at least most of the logical safety risks associated with the test. This is true for anything to be fair, be it operating a hammer to running a nuclear power plant.
Then we have Fukushima, calling it an accident is a bit like running out in front of a speeding bus as “unlucky”.
The original building plans for the power plant did take considerations to a lot of things, but the cost cutting nature of the construction made it the disaster that it turned into.
It were originally going to be built on top of a cliff, but lifting up all the heavy equipment were apparently cited as expensive, somehow it is cheaper to bulldoze the cliff side and lower the whole power plant down some 20 meters bellow the original design. That the power plant also had a severe issue of sea water being able to flood the power plant’s basement if hit by a more severe wave were also known not long after the plant were finished.
Then one can also question the logic behind not using sea water to cool the reactor on the day of the accident. Pipe corrosion were cited as the reason, but a secret about corrosion is that it takes a lot of time to develop. Salt is corrosive, but pumping sea water for a day or two while a supply of fresh water is delivered isn’t going to be the most major issue. (Though, one can also question why more fresh water weren’t stored at the premise itself, or at least in the local area…)
In this case, if one makes design changes, then make sure that the new design actually works. And if this seems like too much work, then stick to the original design…
There is though other nuclear accidents, like the Three mile island is something that were more a result from safety features providing a bit too much information in regards to a problem. Or rather pointing out the later faults in a cascade failure, making the engineers waste their time working with things that weren’t the actual problem.
In this case, too much information can actually lead to a problem seeming larger than it actually is, and make people hunt for the wrong things.
But the most interesting nuclear power plant accident I can think of is the one at Ågesta, being a nuclear plant for primarily district heating, it did have a small cooling tower to handle excess heat. And given the plants construction being underground inside a hill, then the cooling tower were placed on top.
So when the valves opened for discharging the excess heat, the pipes in the pump room burst. And since the pump room also were the electrical cabinet, the whole plant suffered a power outage and loss of control. But last I checked, this isn’t whole accident isn’t mentioned on Wikipedia’s list of nuclear related accidents, even if meanwhile in Belgium a casual spill of a few thousand liters of cooling water without any interruptions to operations is on the list… So I guess the Ågesta accident went rather smoothly. In this case, just make sure the design is built to actually survive normal operation….
Both “Were” and “was” refer to something that has happened or going to have happen in the past.
But to be fair, it is a difference between how these words work grammatically, all though, the difference is fairly small and in most cases pointless. The main thing of importance is that the massage is clearly formulated and easy to read.
But I can agree that I use “were” a lot in that text, considering how the only “was” in the whole text has a “-te” on the end.
Almost a gracious acceptance of assistance. Almost.
Fukushima, and others, and this can be extended to our own little projects, had/has a lot of decisions based on a “this won´t ever happen” kind of thinking. Overvoltage protection on a little board ? “Nah, voltages over 12V will blow the regulator and it shuts down”. Until someone connects it to a live 220V outlet.
“Nobody will put so much weight over it”. Yeah, sure.
Making a competent project/product is about asking the “what if” questions that are relevant, but at times some that are bordering on down right idiotic.
Though, one also got to work within what is reasonable for the application, and also realize that some projects aren’t actually realistic to finish.
In addition to asking “What if?”, you should also ask “So what?”. In other words, don’t design something to not fail, design it so that failure is tolerable.
That’s one of the problems with nuclear safety culture. Nothing is allowed to fail, there’s no give or crazy anywhere, and as a result the whole thing becomes like a Prince Rupert’s Drop – all around you can hammer it without a chip, but snip the end of the tail and it explodes into millions of tiny shards.
If a different approach of “So what if it fails?” had been taken, we would be running modular reactors that cannot go into massive runaway reactions because they’re too small individually to do that.
Please…
Three Mile Island progressed as far as it did due to the design of the control systems. It was from the era of “steam gauges”, blinking lights, and toggle switches. Controls like that are bulky and take up a lot of room, so they need a lot of space to spread out. Operators have to keep moving around to monitor things.
While the TMI reactor was busily eating itself, the guys in the control room were gathered in one area, attempting to figure out what was going on, while across the room was a blinking light indicating a valve was open in the cooling system, venting into the containment building.
Eventually, someone took a wander around the room, noticed the light and used the control to manually close the valve. Meltdown stopped but reactor ruined. If the valve itself or its motor or the wiring from the control room to the motor had been damaged, then there would have been a very bad problem. Like Spock dying in the warp core to save the Enterprise sort of problem. Someone would’ve had to go in there to manually close the valve, most likely receiving a deadly dose of radiation.
Newer control systems put everything in front of the operators on video monitors. They can cycle through all the readings and use controls without having to physically move, and if there’s an alert or alarm, the system can bring it directly to the operator’s attention instead of waiting for an operator to happen to notice a light in the midst of a wall of lights.
Three Mile Island with that kind of system would have been an alarm about the valve popping up on a CRT, then the operator hitting a few keys on his keyboard to close it, then entering a note in the log for maintenance to check the valve. The valve would have been serviced or replaced at some point and TMI would likely still be chugging along, with dozens more LWR power plants around the USA.
But what do we see? 40+ year old nuclear power plants that have control rooms that look like they’re that old, because they are that old. Never updated, for reasons of cost and/or because of regulations that won’t allow major changes. To do such a control upgrade would likely require shutting a reactor down, and without enough excess capacity (especially from more nuclear plants) it’s a not going to happen thing to shut one down for months while the upgrades are made. See also NYC’s water tunnels 1 and 2 that haven’t ever been shut down for maintenance since they opened in 1917 and 1936. Tunnel 3 was started in 1970 and is umpty times long overdue and over budget for completion. Sort of like how it’s always taken far longer and cost much more than it should to build nuclear power plants.
“To do such a control upgrade would likely require shutting a reactor down, and without enough excess capacity (especially from more nuclear plants) it’s a not going to happen thing to shut one down for months while the upgrades are made. ”
No, the problem there is mostly regulatory. Doing the upgrades in the long run would likely work out cheaper and safer in the long run, but changing the control systems and control room architecture on an existing reactor requires basically complete re certification of the entire reactor control and safety system. Since the vast majority of the cost of building a new reactor is in the paperwork and certification, it works out to be nearly equally expensive to just build a completely new reactor, as weird as that sounds. Especially if reactors are already 60 years into their 50 year expected lifetime, with a maximum lifetime extension of maybe 10 or 20 years at most for a lot of older reactors, doing that scale of upgrades just doesn’t make sense anymore.
We should have been building many, many more NEW reactors to make the old designs obsolete. Many of them simply shouldn’t have been running anymore.
blaming the control system because of bulkiness and requiring the operators to move around?!
> Eventually, someone took a wander around the room, noticed the light and used the control to manually close the valve.
What’s your source? Mine is “Who Destroyed Three Mile Island? – Nickolas Means”[1] and I got a very different impression on what the reasons for that debacle was.
The presentation appears to me to be well researched…
[1]
https://www.youtube.com/watch?v=1xQeXOz0Ncs
When it comes to Fukushima there’s a lot at play. Some of it as you point out being politics and cost saving before and during the build. Some is politics and cost saving during operation. Then when the accident occurred there was more politics and problems involved in depressurizing the reactor (which required venting radioactive steam) and hooking up external pumps in order to be able to pump water from firetrucks (and then seawater) into the reactors. Pumping seawater into a hot nuclear reactor means it’ll require at the very least very very major inspection and re-certification, more than likely it would mean the reactor is a write-off. The operators knew that and it wasn’t a call they could make lightly.
If you want a really good description I can highly recommend the blog/explanation on Hiroshimasyndrome.com (http://hiroshimasyndrome.com/fukushima-accident.html).
The book the author wrote on the accident and what exactly happened was a very interesting read and it contains many many details on what exactly the operators did, what problems they encountered and what happened when with which reactor from the moment the earthquake struck the station to the point the reactors were finally fully back under control 5 days later. (No I’m not involved with that website or the author in any way. It’s simply the best and most informative website I’ve found on the issue with many many details I’ve not seen anywhere else. I found it while the accident was unfolding and it quickly became my primary source of information as most news providers couldn’t get past “ZOMG RADIATION, WE’RE ALL GONNA DIE!”)
The blog with accident updates is also very good and contains some very good information. Too bad it’s very hard to get back to the early updates (https://www.hiroshimasyndrome.com/fukushima-accident-updates.htmll)
Addendum to the post above: Turns out the author was smarter about the webpage setup than I was expecting and there’s an easier way to get to earlier blog pages. First blog post can be found here: https://www.hiroshimasyndrome.com/fukushima-first-days.html, starting at march 12, 2011. (bottom of the page)
You can flip through the rest of the blog pages by appending a number after fukushima- in the url (eg: https://www.hiroshimasyndrome.com/fukushima-2 for the second page or -127 for the latest)
Would that it were so simple.
Speaking of accidents and incidents, one also has to consider “what next?”
The ground water at the Bhopal affected area is permanently tainted with toxic chemicals and metals that won’t go away, while the nuclear fallout from Chernobyl has a half-life and the radiation will eventually disappear. However, thanks to persistent propaganda, the public perception of the matter is exactly reversed: that nuclear accidents render a place uninhabitable forever, while other industrial accidents just clean up by some magic and people can move back in after the media frenzy dies down.
Ah, if only.
https://youtu.be/4Xyy1ypRG_Q
Yoiks.
Like we tell to recently hired people here, you only understand the necessity of a safety shoe when that big and ugly piece of steel lands on your feet.
a good write up on chernobyl. all the same details i remember from repeatedly reading the wikipedia article :)
in the case of chernobyl, it is pretty obvious that a handful of operators made some really stupendously bad decisions that they had been explicitly warned not to do. pulling all the rods out and still not having good power output, and then removing cooling! breathtaking stupidity!
but i’m also fascinated by events like challenger space shuttle and fukushima. in both cases they had high-level committee meetings while the situation was still a very wide lattitude to make different decisions with none of the “oh shit the sky is already falling” sensation that operators must feel. and at the meeting, someone said “if we have less than X, then it will explode” and the committee came to the conclusion, “so it is unanimous, X-5 will be safe.”
when we think of corruption, it is hard to imagine this kind of group doublethink. it is hard to devise any sort of protection against it. “at least one non-moron should have veto power” is impossible to implement, when we all seem to be capable of such blatant wrongness.
Similar situation the several times a pilot has crashed an airliner while things were going wrong because the co-pilot with fewer flight hours deferred to the greater experience of the captain rather than speak up about something he or she thought could be wrong. In some cases the co-pilot also failed to notice the problem.
One such was the 737 that crashed into the end of a runway in the UK. It had an engine failure and fire, causing smoke to enter the cockpit. Both pilots had extensive hours in 737’s so they “knew” which engine had to be on fire, the one that provided cabin pressurization from its compressor.
However, they were in a NEW 737. The latest model provided cabin pressure from BOTH engines. Despite what the instruments said, despite the flight attendant coming in to tell them which engine was on fire, the crew shut down the good engine and throttled back the one on fire.
That slowed it so the vibration reduced enough to not be felt inside the plane and the fire went out, stopping the smoke blowing into the cabin. They proceeded to declare an emergency and got airspace cleared for immediate landing. Meanwhile they failed to notice the excessive sink rate and low RPM reading from the damaged engine unable to produce the thrust it should have been at its throttle setting. IIRC they said something about they thought the RPM indication must be faulty. They “knew” they’d shut down the damaged engine.
Too late they finally noticed they were too low, restarted the good engine and pushed both throttles forward. If they’d had another minute they might have just squeaked it in but it bounced off the roadway and slammed nose first into the embankment at the end of the runway.
What made it even worse was both pilots had very recently read through the manual for the new 737, which did mention that cabin air was now from both engines and I’d bet also said that smoke in the cabin could not be used to determine which engine was on fire. But their knowledge of that one thing from previous 737’s was what they relied upon, ignoring all other information to the contrary, and resulted in the loss of many lives.
This problem is something that’s been discussed a lot in recent police shootings.
If you train or habituate people to a certain response, and then subsequently introduce them to a new idea, even with some training, it’s going to take a long time to overcome the previous training, because that’s the whole point of experience.
People can look right at contradictory evidence and ignore it because their experience says “this is a complex system and I know how this should work.” We make bayesian decisions all the time, and that’s hard to overcome regardless of how much information we have.
We need an international day of recognition and mourning of these “accidents” starting at grade school level. Engineering school is too late to learn these lessons. Hindenburg, 16 US astronauts, Titanic, and on and on. Oh the humanity!
Let me correct you about the Canadian Nuclear program. The Chalk River facility had two severe accidents, one in 1952, and another in 1958. Former President Jimmy Carter helped in the cleanup of the 1952 accident, as a US Navy officer. See Wikipedia for details.
Anyone ever thought of up-scaling a US-type nuclear submarine reactor for use as a commercial power-plant reactor? Of course, the reactor-designer / builder lobbyists will do their absolute damndest to convince the power industry that EVERY reactor MUST be a custom design.
How many disasters have occurred with nuclear-submarine reactors and their very standard design?
Then all it will take is the guts–on the part of politicians–to say, “Here. Here’s your Standard Nuclear Reactor Design. If you’re going to build a Nuke Reactor, it WILL be this design. Period. End of Discussion.” This will, of course, have to be mandated at the national level.
I think this (a well-engineered, safe, bog-standard reactor design) is the case in France (where Nuclear is a large percentage of total capacity, and which has been a net exporter of electricity for a very long time); and Canada, which is referenced in the article.
submarine reactors are designed to be extremely compact and take into account the fact that they’re usually surrounded by cold ocean water. They’re simply not suitable or efficient for civilian power use. IF a standard reactor is to be chosen, the CANDU would be a better candidate. Apart from that, the biggest naval reactors were 500MW units, most are more like 100 to 150 MW, which is very small compared to most commercial/civilian reactors which average about 1 GW.
Complicating things further is regulations. Reactors when build have to meet the absolute top end of as safe as possible (and damn the expense). This means it’s impossible to build an exact bolt for bolt replica of a 30 year old reactor because the rules say it must be updated to incorporate the new safety features. And that requires so much redesign you’ve basically got a new reactor. Available space, availability of a source of fresh water, climate, it all has an influence on the overall design of the plant and the reactor systems. There’s really no such thing as a one size fits all reactor.
People may be thinking modular reactors.
https://youtu.be/cbrT3m89Y3M
Any particular reason the following reply, posted more than a day ago, has not been published? —
“Well, with all due respect, I think you missed, absolutely, the very basic intent of the comment. The only information you offered is that which we all know, and certainly nothing we don’t.
i) The size of the reactor is not at issue here. It never was.
i) The cooling media and methods available is certainly not a consideration AT ALL.I know you are not unfamiliar with the very large cooling towers at nuclear plants, and your comment is about as relevant as saying that you cannot design and build a larger amplifier because the heatsinks of the original design are too small.
i) “Reactors when build [sic] have to meet the absolute top end of as safe as possible…”. Is your position that there is a safety problem with nuclear-sub reactors, relative to one-off nuclear power plants?
i) “Available space, availability of a source of fresh water, climate, it all has an influence on the overall design of the plant and the reactor systems. There’s really no such thing as a one size fits all reactor.”–sounds very much like the script to be used by lobbyists for the custom-design nuclear reactor builders.
I, in no uncertain terms, did say “…up-scaling…”.
The intent of the comment was two-fold:
1) It IS possible to build a VERY SAFE nuclear reactor. All one needs do is simply refer to the US’s nuclear sub history for an ideal example.
2) It is VERY possible to arrive at a scalable safe, standard design for a nuclear reactor whose standard design carries the benefits of lowest cost construction and standardized operation and maintenance.
US sub reactors use HEU fuel. Not a viable option in today’s environment of counter proliferation rules.
The original commercial PWR reactors were essentially scaled up submarine reactors as I understand, it’s just that when you scale something up in size other things like robustness of safety systems doesn’t necessarily scale at the same rate.
Just throwing my two cents in. There’s a book by Dyatlov “Chernobyl, how it all happened”, (Чернобыль, как это было) in Russian. It’s written by one of those who worked at the plant at the very moment of the disaster and covers in-depth his perspective. A worthy read for anyone who knows Russian and had a basic knowledge of how a reactor works. If I remember correctly Dyatlov died somewhere about 1995, radiation got him in the end.
His point was that the problem was the design flaw, and that could’ve happened with any of the reactors of the same type that were all quickly fixed to prevent any further disasters. And the crew just followed the flawed protocol. I don’t really remember the details, I read it over ten years ago while still at university.
Safety, while always in the top ten, and probably in the top 5, is never first. Because putting safety first means not getting the job done.
A much better mantra is “Safety is everyone’s business.”
“The guy in the other seat is trying to kill you.”—
Airplane pilot famous old saying…and by old airplane pilots.
The number of people here who talk about the nuclear industry while apparently having no knowledge about it is stunning. I’m a field operator in a nuclear power plant (no control room for me, I like moving around too much). As operators in this field, we actively study events like Fukushima and Chernobyl along with all the other events you don’t hear about, (not swept under the rug, just nothing big enough for the public to take note of) to prevent the same accidents from happening here.
First thing you need to know is that engineers are nothing. Operators run the plant. You can tell them apart in the field with a simple visual test. Clean clothes, neat papers, vacant expression on their face while they look at the equipment like they’ve never seen it before? That’s an engineer. They have no integrated system knowledge or understanding of how the plant works. Just their own stuff.
Filthy, climbing on the equipment or beating on the equipment with their hard hat, swearing at it? That’s definitely an operator. And what they are doing is “mechanical agitation”, and they have to get it just right to make it work.
Interesting development: There has been an increase in neutron counts coming from the basement underneath the reactor, indicating that fission within the corium is increasing rather than decreasing as expected. The leading theory is that the new protective cover is preventing rainfall from reaching the sarcophagus and the structures beneath (as it was designed to do) and this is having the unexpected result of drying the basement out. Apparently, previous high water levels moderated the neutrons too well and stopped most reactions from occurring, but now the water levels have dropped low enough and have reached the sweet spot that allows fusions reactions to pick up. Scientists working at the site are worried about the excess radiation caused by this and the possibility of a steam explosion if reaction rates get too high. The new containment structure is designed to hold in such a steam explosion but it would make future clean up more difficult as it would further weaken the already damaged section of the plant. Nothing but further monitoring is being done at this time and predictions are that the reactions will probably fizzle out as the basement areas continue to dry out.
Fission* reactions, not fusion. Good job auto correct.
Someone is going to have to go in there and drill some holes, likely with a thermic lance for fear of the vibrations bringing down the entire structure then hook up GdNO3 or some other moderator pipe and flood the area with it to bring the reaction back under control.
The only good thing here is that radiation exposure treatments and shielding have improved substantially since 1986 so they will likely survive.
Vaguely recall an article about shielding coveralls that can be worn which use Bi/Au granules encased in high MW polymers.
Au of course makes an excellent radiation shield and apart from being very expen$ive is actually better than Pb.
Hate to be pedantic, but several times in the article an experiment with the “steam generator” is referred to. The experiment involved the *turbine generators”. They were concerned that if all power from the outside system blacked out, it would take 60 seconds for the diesel generators to get up and running and continue to power the cooling pumps. So they wanted to see if through the remaining inertia in the turbine generators as they ran down when the steam was cut could produce enough power to bridge the time gap.