
At their core, package repositories sound like a dream: with a simple command one gains access to countless pieces of software, libraries and more to make using an operating system or developing software a snap. Yet the rather obvious flip side to this is that someone has to maintain all of these packages, and those who make use of the repository have to put their faith in that whatever their package manager fetches from the repository is what they intended to obtain.
How ownership of a package in such a repository is managed depends on the specific software repository, with the especially well-known JavaScript repository NPM having suffered regular PR disasters on account of it playing things loose and fast with package ownership. Quite recently an auto-transfer of ownership feature of NPM was quietly taken out back and erased after Andrew Sampson had a run-in with it painfully backfiring.
In short, who can tell when a package is truly ‘abandoned’, guarantee that a package is free from malware, and how does one begin to provide insurance against a package being pulled and half the internet collapsing along with it?
NPM As Case Study
In Andrew Sampson’s Twitter thread, they describe how during the process of getting packages for a project called bebop published in various software repositories, they found that this name was unclaimed except in NPM. As this package hadn’t been updated in a long time, they assumed it was likely abandoned, and found an entry on package name disputes in the NPM documentation. This entry has since been heavily altered, because of what happened next.
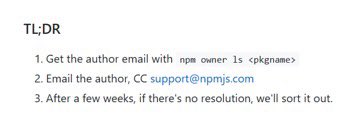
Following the steps in the NPM documentation, Andrew emailed the author of the existing bebop package and CC’ing NPM support as requested. After four weeks had passed, Andrew got an email from NPM support indicating that Andrew now owned the NPM package:

It all seemed fine and dandy, until it turned out that not only was bebop still being actively developed by one Zach Kelling, but that at least thirty different packages on NPM depended on it. During the subsequent communication, Zach and Andrew realized that the email address produced by the npm owner ls command was not even associated with the package, explaining why Zach never got a message about the ownership transfer.
The obvious failures here are many: from NPM failing to ascertain that it had an active communication channel to a package owner, to no clear way to finding out whether a package is truly abandoned, to NPM apparently failing to do basic dependency checking before dropping a package. Perhaps most astounding here is the resulting “solution” by NPM, with Zach not getting ownership of the package restored, but only a GitHub Pro subscription and $100 coupon to buy merchandise from the GitHub Shop. Andrew ended up compensating Zach for the package name.
In their thoughts on this whole experience, Andrew makes it clear that they don’t feel that a software repository should have the right to change ownership of a package, that this responsibility should always lie with the owner. That said, as a matter of practicality, one could argue that a package could be considered abandoned if it has not been downloaded in a long time and no other software depends on it.
But is NPM really an outlier? How does their policy compared to more maintainer-centric models used by other repositories, such as those provided with the various Linux and BSD distributions?
The Burden of Convenience
A feature of the NPM software repository is that it’s highly accessible, in the sense that anyone can create an account and publish their own packages with very little in the way of prerequisites. This contrasts heavily with the Debian software repository. Here the procedure is that in order to add a package to the Debian archive, you have to be a Debian Developer, or have someone who is one, sponsor you and upload your packages on your behalf.
While it’s still possible to create packages for Debian and distribute them without either of these prerequisites, it means that a user of your software has to either manually download the DEB file and install it, or add the URL of your archive server to the configuration files of their package manager as a Personal Package Archive (PPA) to enable installation and updating of the package along with packages from the official Debian archive.

The basic principle behind the Debian software repository and those of other distributions is that of integrity through what is essentially a chain of trust. By ensuring that everyone who contributes something (e.g. a package) to the repository is a trusted party by at least one person along this chain of contributors, it’s virtually assured that all contributions are legitimate. Barring security breaches, users of these official repositories know software installed through any of the available packages is as its developers intended it to be.
This contrasts heavily with specialty software repositories that target a specific programming language. PyPI as the official Python software repository has similar prerequisites as NPM, in that only a user account is required to start publishing. Other languages like Rust (Crates.io) and Java/Kotlin (Sonatype Maven) follow a similar policy. This is different from Tex (CTAN) and Perl (CPAN), which appear to provide some level of validation by project developers. Incidentally CPAN’s policy when it comes to changing a package’s maintainer is that this is done only after much effort and time, and even then it’s preferred to add a co-maintainer rather than drop or alter the package contents.
Much of these differences can seemingly be summarized by the motto “Move fast and break things“. While foregoing the chain of trust can make a project move ahead at breakneck speed, this is likely to come at a cost. Finding the appropriate balance here is paramount. For example in the case of an operating system, this cavalier approach to quality, security, and reliability is obviously highly undesirable.
One might postulate that “break things” is also highly undesirable when deploying a new project to production and having it fall over because of a pulled dependency or worse. Yet this is where opinions seem to differ strongly to the point where one could say that the standard package manager for a given programming language (if any) is a direct reflection of the type of developer who’d be interested in developing with the language, and vice-versa.
Do You Really Need That?
As anyone who has regularly tried to build a Node.js project that’s a few months old or an Maven-based Java 6 project can likely attest to, dependencies like to break. A lot. Whether it’s entire packages that vanish, or just older versions of packages, the possibility of building a project without spending at least a few minutes cursing and editing project files will gradually approach zero as more time passes.
In light of what these dependencies sometimes entail, it’s perhaps even more ludicrous that they are dependencies at all. For example, the left-pad package in NPM that caused many projects to fall over consists of only a handful lines of code that does exactly what it says on the tin. It does raise the question of how many project dependencies can be tossed without noticeably affecting development time while potentially saving a lot of catastrophic downtime and easing maintenance.
When your file browser hangs for a few seconds or longer when parsing the node_modules directory of a Node.js project because of how many folders and files are in it, this might be indicative of a problem. Some folk have taken it up them to cut back on this bloat, such as in this post by Adam Polak who describes reducing the size of the node_modules folder for a project from 700 MB to 104 MB. This was accomplished by finding replacements for large dependencies (which often pull in many dependencies of their own), removing unneeded dependencies, and using custom code instead of certain dependencies.
Another good reason to cut back on dependencies has to do with start-up time, as noted by Stefan Baumgartner in a recent blog post. While obviously it’s annoying to type npm install and have enough time before it finishes to take a lunch break, he references Mikhail Shilkov’s work comparing cold start times with cloud-based service offerings. Increasing the total size of the deployed application also increased cold start times significantly, on the order of seconds. These are billed-for seconds that are essentially wasted money, with large applications wasting tens of seconds doing literally nothing useful while starting up and getting the dependencies sorted out.
This extra time needed is also reflected in areas such as continuous integration (CI) and deployment (CD), with developers noting increased time required for building e.g. a Docker image. Clearly, reducing the dependencies and their size to a minimum in a project can have very real time and monetary repercussions.
KISS Rather Than Breaking Things

There’s a lot to be said for keeping things as simple as reasonably possible within a software project. While it’s undoubtedly attractive to roll out the dump truck with dependencies and get things done fast, this is an approach that should ideally be reserved for quick prototypes and proof-of-concepts, rather than production-level code.
Through my own experiences with (commercial) NPM-based JavaScript projects, as well as Maven and Gradle-based Java projects using an assortment of Nexus repository servers, I have come to appreciate the simplicity and stability of less-is-more. Adding a dependency to a project is something that should be considered in-depth and ideally prevented as dependency or the need for its inclusion eliminated. If it’s added, it should be considered whether this dependency should be external or exist inside the source tree.
At the end of the day, making a project bullet-proof is something that should be appreciated more. That includes decreasing the reliance on code and infrastructure provided by others, especially if said code and/or infrastructure is provided free of cost. If your business plan includes the continued provision of certain free services and software, any sane investor should think twice before investing in it.














Can’t wait till we go back to html 1.0, life was so much faster.
Many websites I follow are back to static HTML pages. Sometimes I wonder why the web became such a messy situation… or maybe it’s just me.
https://idlewords.com/talks/website_obesity.htm
i agree with the sentiment here but this sentence from the article triggers me: “While it’s undoubtedly attractive to roll out the dump truck with dependencies and get things done fast, this is an approach that should ideally be reserved for quick prototypes and proof-of-concepts, rather than production-level code.”
the example is right here in the article, npm left-pad. i simply do not believe that it was less work to import that module than to left-pad properly from scratch. dependencies *can* save time but generally they’re used for a different reason. and honestly i don’t know what tha different reason is. there’s certainly some ignorance involved (coding by google). some people probably believe erroneously that re-use is always more efficient. and others probably fail to recognize the shades of simplicity, the fact that they replaced 10 lines of code with a depedency on a module that contains 10,000,000 lines of code…they simply didn’t recognize the scale of the mistake. i’m looking at you, react.js. does corporate policy play in here?
i really don’t know the real causes, it is a mystery to me. i am just pushing back for all i’m worth against the idea that it’s actually faster. it can be faster but most of the time it isn’t, not even in the short-term.
What do you expect from people who have been taught to code with Python and/or Arduino?
LOL, don’t forget AutoIt Script and Lego Mindstorms.
Hehe, wait for GitHub AI to kick in.
:o)
Hey the Original RIS Mindstorms at least was great, all the programming logic and flow you could want but made simple enough for even really young kids to get started with, mess up and learn. And must have been a pretty tight dependency set as the early Lego ‘intelligent’ bricks really are slow, and dumb microprocessors. I assume the later ones have remained as good, but don’t really have the experience to know.
It also wasn’t at all hard to program the RCX brick in any number of ‘real’ languages as you got older and wanted more, really neat little things, way ahead of anything else you could get at the time… Heck I still think the RCX brick stands up today for many things most folk would just throw the Pi at – which is why I bought a heap of the V1 RCX with the barrel jack power option when I saw them cheap – decent motor controller, power regulation and battery power options, IR data link, the buzzer and screen, sensors you can easily build yourself… Lots of great points, and then the Lego form factor means you can easily build housings, mounts anything you need.
im so glad my first language was c.
I think you’re being unfair. The last time I tried to get performance out of an Arduino library for IO bit twiddling at high speed I ended up inlining assembler for a roughly 300 fold performance improvement, iirc….
So, it’s not impossible to acquire an understanding of bloated dependencies with Arduino…
Inline assembler is completely unnecessary.
Something like:
# define LED_BIT 1<<4
PORTD |= LED_BIT;
gets translated to a single sbi instruction by GCC.
ASM is more like 20% improved efficiency (maximum, compared to decent C or C++) but for 20x more development effort and 0% portability.
And when you get to big processors…
Managing 16 cores, cache flushes, out of order execution, keeping pipelines filled…
You want to do that in ASM?
can you trust gcc to give you absolute control, down to the number of clock cycles, over IO timing?
You can always check the result ASM for the critical sections, sometimes to find that the compiler was smarter than you and did it in less cycles
There still are some niche applications for ASM snippets in these modern days, and one of such is where cycle accurate I/O timing is critical. But when such things become critical, there is also a big chance you’re using the wrong type of microcontroller in the first place. And 32 bit ARM running at 150+ MHz is not more expensive then an old fashioned uC where all families tend to crop out around 20MHz (Do they all use the same generation of Chip factory equipment?)
Another niche application for ASM snippets is the task switching code in an RTOS.
Yet another is students of computer architecture. Knowing how ASM works (of a few different uC families) can help to become a better C programmer.
And there probably are some more niche applications for asm snippets, but not complete ASM programs, wherever a C compiler is available. The price to pay in developer hours and lack of code reuse and portability is simply too great, and people still writing complete ASM programs are probably misguided, still living in the dark ages, too stubborn to learn something new or do it just for fun.
And of course, there is the very special case of the people who actually write and maintain the compilers. There is some point in the cycle where all code has to be translated to machine code.
much like the other people replying to this comment, for me using ASM on microcontrollers is about control not speed. if gcc makes it faster than i did, that’s not necessarily a bonus, because the situations where i handcode asm i’m usually either counting cycles or carefully managing side-effects (like at entry to an ISR). and more importantly, i don’t want to deal with the fact that gcc will change over time how it compiles it…if it’s one speed today and a different speed tomorrow, that can be bad even if it’s an “improvement.”
when i do develop from scratch on microcontrollers, stm32 or smaller sort of things, i either use raw asm for the whole project or i use a very stupid pidgin forth i call ‘gforth’. it is basically a 70-line compiler that converts my .gf scripts to whatever assembler i’m using today (PIC12, PIC16, m68k, ARM thumb, whatever). it’s very stupid, just a sequence of words with prefixes to indicate push value, push address, push literal, call, etc. it’s roughly as convenient to code for as forth is, but it’s not efficient at all, and obviously not portable either. when i’m counting cycles i use inline asm.
like i said, for microcontroller development i’m always most obsessed with control over everything else. i don’t want to be second-guessing a compiler or runtime library for any reason at all. but that’s just microcontrollers. obviously for PCs i have a totally different mentality. and a lot of things i don’t really think of as microcontroller tasks wind up on smallish CPUs, like 3D printer firmware is complicated enough i’d definitely rather that be in C even though it runs on a small CPU.
You can certainly trust avr-gcc to give you complete control and to produce results consist to the cycle.
Especially when it comes to things like this, bit twiddling of registers.
There are not many optimizations even available on AVR. The only common thing that you can make faster with assembly are interrupts.
It’s not impossible, but the Arduino coding reference itself tells you e.g. that it’s a bad idea to do direct port/register manipulation (because it would break stuff they’re doing behind the curtains).
Just trust the library and use what you’re given. That’s the message.
99% of the time, it’s going to be faster and more stable to bring in an existing library than re-code something from scratch, and then discover all the edge cases yourself.
Have you tried writing something like react yourself?!
Of course, often react is more than people need, and they might have managed with handlebars.
Thankfully some libraries e.g. underscore allow you to just grab the bits you need (I almost always only need throttle).
Unfortunately what’s lacking is a good way to identify libraries which are well maintained and not bloated for your requirements.
this is a good summary of the perspective that i think is completely wrong. i mean, there are cases where it is true, but they’re not remotely 99% of the time. for left-pad, for example, it’s absolutely not true. perl’s CPAN, for example, has a bunch of modules that are literally 100 lines of object-oriented boilerplate around 1 line of perl code…it’s not rare. it is the defining case for re-use in dependency-centric development.
i honestly don’t understand how someone would write that it’s faster to re-use something than to discover the edge cases yourself…if you believed that, then you’d do a lot of re-use and you’d know that re-using code is a process of discovering edge cases, just like writing code from scratch is. i’ve done both and i know that unless it’s actually a big task, i will spend just as much time discovering edge cases in react.js as i will discovering edge cases in CSS. neither one saves me from doing the basic task of developing software.
interesting to ask if i’ve tried writing something like react.js myself. obviously, i have not. i google how to do something in html, and i often get a result showing 2 lines using react.js. i keep going, and i find the same with 2 lines of CSS. i don’t *want* react.js. the things people accomplish in real life using react.js are not complicated things that need a complicated framework. they learn react.js because they don’t know CSS, and for no other reason…but the task of learning react.js isn’t any easier!
and then to throw in this word “stable”, i truly am at a loss. the article covers well the fact that dependencies introduce an additional source of instability over time. but there’s an even worse cost, in that react.js takes walltime to load on even the fastest browsers. so now you have inherent instability in the UX, where visual elements move about the screen as react.js slowly processes your simple website. i cannot imagine anything less stable.
but i do think this rant has put me on one of the reasons people ignore the costs of react.js. they do not go through the test/edit process i do to debug something. they do it poory with react.js and it doesn’t work very well and they shrug and move on, mission accomplished. if you don’t shake out the bugs, it doesn’t matter what you do, it will be much faster than shaking out the bugs. it just happens that people who are a big fan of no-test or test-known-to-fail-ship-anyways development are big fans of dependency overuse. it’s not the dependencies that make the development faster, it’s the fact that you don’t test.
While I can see your point, I’d actually side with it being faster and more stable to bring in dependency quite often.. Many of the common dependency you should be using a great deal of because they deal with a great amount of complexity for you, are better optimised and less buggy than anything you would write, having had so many extra users feeding back to catch all the little gotcha…
The trick is looking for the right ones, not just that are supposed to do what you need right now, but are reasonably optimised and developed in a way that rarely breaks things – in the same way you need version x or newer of a lib in Linux software, and in almost all cases anything newer even if its much much newer still works with the legacy everything else, as backward compatibility tends to remain (though obviously that isn’t always going to be the case, upgrades will break things sometimes).
And once you find your personal common dependency collection I personally can understand why you would use them all, all of the time, even if this or that one is rather underutilised this time – it does function x for you, you know it does it well, but the time you write that same function as a standalone into your code the boss probably fired you for being too slow…
I completely agree with this.
If you haven’t discovered the edge cases, and you get a bug report, you don’t even know if it is in your code or in a dependency. Just figuring out what a bug is and where it is blows up the “lots of dependencies” model.
For the initial builders of a pile of code, it probably saves them time compared to figuring out what code they need, but anything worth implementing is going to need maintenance, and that will require somebody to learn the edge cases.
This is something that Golang really does well, though it is often complained about.
Programmers are lazy. They would rather import a package or library they know than write their own code. Who cares that it creates more bloat and wastes computing time? If your computer thingy can’t open the page because it’s too old, then just get a new one, right?
In dark ages of Unix people wrote many, many scripts to be able to do anything. Some of them were dependent (ekhm…) on the bugs in the software. Some of those bugs were there for years, because otherwise scripts would fail, and whole world would collapse. Eventually they fixed them, when user base shrunk, and other systems replaced many of the Unix variants…
On related note: I had a scanner from 2010 that used software written in 1997, and the software (except for tray icon app/launcher) worked fine. It still works (under Windows 10 x64), but the scanner had a mechanical failure. My daughter picked up the box with the scanner and pretended it was her laptop, banging it against few walls and dropping it from the desk…
“My daughter picked up the box with the scanner and pretended it was her laptop, banging it against few walls and dropping it from the desk…”
Now who could have taught her that behavior?
B^)
Forgot to mention she was doing whatever any 4 yo kid does: jumping, running, sliding on the tile floor, etc. Anyone who has young kids, also has some casualties in electronics and computer equipment.
She also peed on my oscilloscope, when we were trying to potty-train her for the first time…
lol, that must have been an intense potty session.
Yeah, you don’t have to teach kids how to drop things or bang them into stuff. That’s the default setting. The trick is teaching them to be careful. My daughter knows the words, but putting them to practice is a little harder.
@John.
It was a soviet scope. She just sat on it, played with some toys and just “let go”. Scope was covered in some bubble wrap, but she took it off. I had to disassemble it and clean up with IPA..
I have a saying (sounds better in Polish):
Little children make it hard to sleep, bigger ones make it hard to live…
I laughed out loud.
Never leave your scope on the floor.
Perl has an added aspect, in that it will incorporate useful modules into its standard installation, and frequently these are compiled C code rather than native perl (and frequently managed by the compiler directly).
I keep a list of frequently used perl modules needed for a new OS install, and year over year the module list has gotten a lot shorter. The install script returns a few “this is already in the default install” messages each time.
If you want to combat bloat, make things more efficient, and keep malware out, maybe extend your language to add the features that people use the most?
Perl also has the feature that if it’s not already installed it squawks, requiring manual intervention… And it IS a feature.
NPM is built so as to encourage runtime download on use.
Very bad practice IMHO, but it’s great for knock-it-together-and-run… Until you realize that it telegraphs what you’re users are doing to outside entities.
Security? Security?! We don’ gotta have no security!!
“…to make using an operating system or developing software a snap”. Interesting and potentially contentious choice of words for an article on dependency issues!
Referring to the (perhaps) inadvertent “snap” pun? If not, I don’t get it.
Or snap packages.
https://en.wikipedia.org/wiki/Snap_(package_manager)
that’s the pun I’m referring it.
The left-pad thing shows another aspect also : if enough $$ complains, you are not the owner of your package anymore, as showed by them “undeleting” a package.
Also, the blind inclusion of dependences and packages is a combination of laziness, a wrong concept of “develop it quick”, and a lack of knowledge about the whole thing. Like someone who knows enough to do a passable job, but not enough to do a *correct* job. And then those vaporous theories of “quick release cycles”, “release-then-fix”, etc, get tossed around to justify.
A good inchantation to hang on the wall and profer when deciding on some kind of feature : “If we can´t spare one hour to make it right, when will we be able to spare one full day to fix it ? “
not a software developer myself, not even much of a GNU/Linux user (so no “apt get” or similar) but the fact the he could pull his packages in the first place is kinda odd to me.
I’d have assumed that once you publish a package AND there are dependencies you can’t just unpublish it at any later point in time. With of course exceptions on vulnerabilities or freshly published ones.
I mean it’s his code but couldn’t NPM put such a requirement in the ToS or something?
I suppose that if they clearly state that “If you publish it here, it becomes ours” people wouldn´t be so keen to put their packages in their platform, and then they would lose money , so ….
Sounds like Nexus and Mods.
Would it need to become theirs?
He did publish it under a compatible open source license into a package management system. -> Anyone can use/republish it in compliance with that license.
I don’t quite see how it stops being his code. He’d still have all rights of licensing it to third parties under non-OSS licenses but once published in NPM he shouldn’t just be able to remove it from the PMS = package management system ;-)
I dont see why that’s necessary. If its GPL licensed then it can be freely distributed. Rather than the repro taking control of the package the question should be what right does the dev have for pulling the code? If you didn’t want people using it without permission you shouldn’t have licensed it that way.
I think the big issue with node.js is that the bare language is so sparse that people are compelled to write and use lots of little bits of code in modules that should have been part of the language in the first place.
For example the string handling functions in node.js are totally minimal and you have to use miserable hacks or external libraries to do to even simple things like string replace all. Bizarrely, parsing numbers is not even a feature in node.js, you either have to write it yourself or trust some random crap from the internet that probably doesn’t work right.
I totally agree. Something like left-pad should be folded into the language’s standard libraries, or in the language itself.
But then, node.js itself always felt like a terrible idea to me anyway. Using JavaScript to do back-end processing, especially on something performance critical (Like generating pages), seems like a massive waste of server resources.
Node.js is really wonderful for writing selenium web browser tests. Performance is not an issue because you are waiting for the browser. Web testing is always tweaky and weird so an interpreted language like node.js is essential for quick turnaround.
You can and should write your web browser tests in a different language from your web application.
What you aren’t writing automated tests for your web applications? Shame on you.
JavaScript is rather performant, though a massive amount of developer effort has been put in to make that so.
Though I agree that JS as a language feels incomplete, incoherent, messy, inconsistent and confusing and I’d rather stay as far away from it as possible.
I guess Node.js got popular because front-end developers realised they needed to write a backend and didn’t want to learn another language (though the whole idea of isomorphic JavaScript is interesting but never seem to have caught on).
It’s the same reason I’m interested in Web Assembly – to avoid JavaScript if I need to write front-end code 😄
“one gains access to countless pieces of software, libraries and more”
Well, not countless, since there are only so many people maintaining the repository and they can only keep up with so much stuff. You can very much count them. Example:
https://repology.org/repositories/packages
The central repository software distribution model starts to break down around a few tens of thousands of packages, which may represent only a few thousand individual software titles in all. You can’t effectively have a “googleworth” of software in there – unless every package is a complete deal that comes full with its own dependencies, maintained solely by its supplier, and the whole repository is just passing them along and acting as a search engine. Basically, a database full of download links to setup.exe files.
> constant integration (CI) and deployment (CD)
and there it is… someone maliciously replaced a low level dependency without the authors knowledge and suddenly “continuous integration and continuous deployment” turned into a “constant” dilemma.
;-)
But srsly, interesting, informative read and simultaneously depressing and funny :-/
seems to me the whole issue here was caused by a name collision with the word bebop. If the author of the second package had simply chosen a name that did not collide with an existing package, the ownership of the original package would have been a non-issue. The moral of the story is to pick a unique name and then you do not have to deal with “abandoned” or “no so abandoned” projects that have the cute name you wanted. He could have called it something like “bebop thingamajig” with thingamajig with something that might tell you what it does to avoid confusion like “bebop terminal emulator” or something helpful to let people know they have the correct package. In fact, I prefer names that tell me something about the function of a package rather than cuteness.
No – the issue is that the package got stolen from the guy who rightfully owned it. You can think of unique names all you like, but if I can steal them and replace them with my code, that’s an RCE waiting to happen.
Kind of like domain names.
It’s a lot like domain names. If you forget to update your contact info, payment info, or whatever and your domain expires, is it your fault or the next person who pays the domain fee?
I ran into something like this somewhat recently with a MeetUp group name. My electronics group was getting quite popular, so I paid for more member slots. It went on for a year or so more, but then I got tired of maintaining it and active membership was dwindling, so I wanted it to die a respectable death on my terms. Instead MeetUp whored it out before it completely expired and sold the whole group to some random person. They might have been doing me a favor in their mind (both of them), but usurping my group when I would have preferred it ended gracefully is a rotten thing to encourage people to do. Whose fault was this mess? Mine for not realizing MeetUp would take my group and zombify it. Now I avoid MeetUp completely. What a scam for the paying members.
Ugh, I just went back and checked, and MeetUp still has all my personal photos, art, and projects displayed as part of the group’s page. I wonder if I can send a letter to get that stuff removed. It looks like it hasn’t even been used in the last two years, but my IP is still being displayed. What a crappy business.
Sort of like domain names except you keep your domain active by continuing to pay for it so the registrar has up to date contact info for the billing. When you stop paying the name becomes available. For packages there is no way to know if you abandoned it, “finished it”, dont care any more, etc. Problem is you cannot know if another package is dependent on your package in perpetuity. I could create a package tomorrrow that is dependent on your ten year old forgotten package. As a developer it becomes my responsibility to now make sure your build remains compatible. The name collision thing is bad though because a lot of package managers are looking for packages by name and now they can have a completely unrelated package. Bottom line is if you recycle a name you are breaking an untold number of packages that depend on that name. Think of the implication to systems that try to automatically update to newer versions on their own. Just dont reuse names.
That too but if you choose a unique name for your new project you wouldn’t “steal” from the guy who rightfully owned it in the first place. Who can decide if a package is abandoned or not if you can’t communicate with the owner. Seems his contact email was not correct. Mistake happen. If you don’t have a name collision the whole thing is a non-issue. Records get out of date, people make data entry mistakes, just avoid the whole issue and don’t re-use package names. Linux does not care how catchy the package name is so use a unique one. You can jump on the repo guys all you want but remember you are not paying them for services in most cases so if you make life difficult for them, they owe you nothing.
This is how we get carol987698740.
Maybe some better way to address namespaces?
That implies a central management of names somehow which is gonna get really dicey. Who wants to take that one on? Using packages seems easy when writing code but becomes a nightmare for ongoing code management. I have just recently worked with a large commercial package from a major software vendor that took weeks to get installed because a major dependency deadlock caused by a stupid small utility. Mr major software vendor could only fix the problem by replacing that package with a built in function. Cause of the deadlock was the problem package was dependent on yet anothe r package that got removed due to a zero day security hole. Over time the odds of install failures go up as backward compatibility degrades.
If you want millions of tiny dependencies, most will be named dep12354523.
Being able to steal dep653 because it has a shorter name doesn’t actually fix the problem at all. The solution isn’t to have more Authorities to Manage the names, the solution is to treat a used name as not available to new projects, and to treat project7634543 as a legit name choice if an ecosystem has a lot of packages.
It wasn’t exactly stolen. Yes you could obtusely refer to it in that way, but it’s disingenuous at best. It was mistakenly reassigned. It wasn’t even the package, it was the package name. The package is the program that the owner clearly still owns and unless he/she is a moron, still has the source code to. You have to understand and agree on the true nature of the problem or you’ll never find a solution.
I guess that if you don’t put your proper contact information on your package name, or update it in case of changes, you lose your claim on some repositories. That’s not overly unfair. Can you truly claim to be actively maintaining a package if you don’t even keep contact info updated? You might be updating, but maintaining is more than updating code.
At some point almost all code stops being maintained due to loss of interest, end of usefulness to the author, etc. I was just thinking one way to show that you still have interest in code would be to digitally sign it with a certificate with a valid date. The other issue is that I might put my code in a repo and not care about it any more but there could be thousands of other apps with a dependency on it that are actively maintained. If you reuse my name even on a different repo, you can break a lot of applications depending on where a particular system picks up its repos. Just imagine that some repos have package bebop doing one function and other repos have a new version of bebop with a newer version number that is completely different. That is plain ugly. Even if the original “owner” of bebop had maintained his “ownership”, there is nothing stopping someone from uploading a new bebop to a different repo.
It was exactly stolen, and calling people names won’t change that.
A quick google search turned up the following.
Bebop – a drone
Bebop – a compiler
Bebop – a remote video and audio editing platform
Bebop – a game on the Linux platform
Bebop – an mvc framework
Bebop – a KDE desktop theme
Maybe it is time to find a new cutesy name for your next app.
It is also a bear.
You missed a space cowboy.
It’s the name of the ship that the space cowboys fly around on.
Yep, my search was just for Linux related stuff and I could have found a ton more. My point is that your compiler would not care less if the package was named “notreusingnamesforpackageshere” instead of cute little bebop and all the drame could have been avoided and your cute little package would be less likely to get stepped on in the future. By all means show a nice name is the user interface but we would like “sometechdescriptionofthisfunction” for the package name.
When I was in grade school, bebop was a music genre and a pencil trademark.
hol up, so Andrew stole Bebop from Zach via NPM, and instead of giving it back, they just threw some money at him?
Also, what is all this talk about ‘abandoned’ code? I don’t know about you, but my goal with code is to get it to a point where it works and I never have to touch it again. I WANT to abandon the code, lol.
Yup, I get nervous around code that has rapid changes, some of the best code I’ve used goes months, or even years before getting a change. Or when it does get changed, its something simple like modifying some dialog box, swapping out a function for another, or removing support for a platform that isn’t used anymore.
I mean, its kind of the Unix philosophy that you write things to do one thing and do it well. Once you get something working well, you step back from it and only touch it again when it stops working well.
“Yup, I get nervous around code that has rapid changes,”
Just about every time I log into my home Linux box, the Brave browser has an update waiting…
…or, as we used to say MANY years ago–
“WHY IS THERE NEVER TIME TO DO IT RIGHT, BUT ALWAYS TIME TO DO IT OVER?”<
******************************************
pssst… : “incantation
and “proffer”
Making a tiny module and uploading it to npm is a popular way to pad a resume. Find some niche function in a major package. Copy it into a new package then upload to npm. Submit a pull request to the popular package to use your version. Repeat until you can now claim your code is running on 75% of major websites.
Any competent recruitment person or developer will see through this straight away as they’ll ask what code you’ve written but it helps you get past the initial HR round.
I don’t see anything particularly unsound about building a business relying on free software, so long as it is software which you are happy with in the current condition ( no need for updates ) and can run locally on your systems with no reliance on external services. It’s specifically when you rely on something which is a service, not a product, that the maintainence becomes an issue.
If you are building a business on your code it becomes your responsibility to keep,tracking dependencies which can get impossible if there are too many. You are also staking your business on there being no major security flaw in one of those dependencies. I would spend a lot of time trying to build the more obscure packages functions into my own code and limit my dependencies to majpr well maintained packages used across major OS repos. If you want to base your business future on a bunch of code maintained (or not) by people you don’t know and count on them to find a fix bugs, you are on some shakey ground. Dont get me wrong, the repo system is great for fast coding and deploymemt but it has its drawbacks for business critical systems. In major enterprise there are often automatic updates for security reasons and it breaks lots of applications with almost no way of knowing without extensive lab testing every application. I have to say that it is much harder on *nix based systems due to widespread use of package and library sharing from countless sources. Every *nix admin has been in dependency jail at some point.
I am not smart enough to fix all that myself (and no one probably can without compromising on some positive aspects of the ecosystem) but avoiding previously used package names you know exist is a no brainer to me.
“The Dark Side Of Package Repositories: Ownership Drama And Malware”
…and outdated software versions. If you need an up-to-date version of a piece of software, there’s usually only one choice: Compile from source, which immediately lands you in Dependency Hell, stuff being put where it doesn’t belong, and environment changes that leave you spinning in an episode of the Twilight Zone.
Downloading the latest binary is usually an option on the official website of the project, but you’re definitely right about outdated software being on repositories.
I was building a toolchain for some somewhat obscure SoCs, and finding the right versions of things was a pain in the ah… neck. Then when attempting to compile my program SDL2 had trouble finding the right dependencies. I eventually went down to SDL1 and managed to get things done. Programming certainly isn’t easy.
I don’t understand why Maven got lumped in with the other repository systems for having lax requirements. Maven requires developers to prove ownership of a domain name that corresponds to the namespace they want to publish artifacts to. Maven Central doesn’t allow removing artifacts either, so your Maven-based Java 6 project ought to still build today, provided you’re using the same JDK and Maven version.
Except there is a new JDK every few weeks and they often get pulled for security bugs.
That npm ownership change protocol is brain-dead. Ownership should never change involuntarily. If abandoned packages are a problem, then you build a package forking/replacement protocol, where new packages can declare that they have forked a particular version of a package and are continuing development. Then you can mark packages as inactive and suggest the forks if the original package is ever referenced in a new project or when updating dependencies on existing projects.