In CPU design, there is Ahmdal’s law. Simply put, it means that if some process is contributing to 10% of your execution, optimizing it can’t improve things by more than 10%. Common sense, really, but it illustrates the importance of knowing how fast or slow various parts of your system are. So how fast are Linux pipes? That’s a good question and one that [Mazzo] sets out to answer.
The inspiration was a highly-optimized fizzbuzz program that clocked in at over 36GB/s on his laptop. Is that a common speed? Nope. A simple program using pipes on the same machine turned in not quite 4 GB/s. What accounts for the difference?
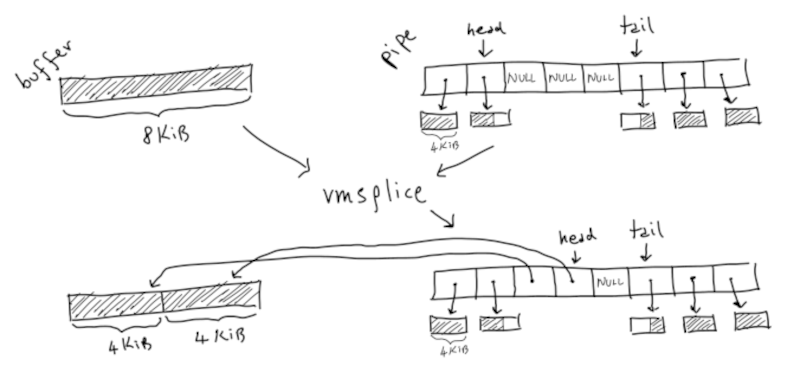
What follows is a great use of performance measuring tools and optimization. Along the way there is plenty of exposition about how pipes work inside the kernel. In addition, some other subjects rear up including paging and huge pages. Using huge pages accounted for a 50% improvement, for example.
Did he finally get to 36GB/s? No, he actually got to 65 GB/s! There is a lot to learn both in specific techniques and the approach. At each step, careful profiling identified what was eating the most time and that time was reduced. The results speak for themselves.
We’ve talked about pipes several times in Linux Fu installments. You can interact with pipes. You can even give them names.














You have blown my mind.
Unfortunately, the art of optimisation has been steadily fading for years. Hardware advanced at such a speed that it was (still is, in many cases) easier to throw silicon at the problem rather then have better software (which has a much higher initial cost).
Unfortunately? Far too often someone tried being clever with code. Later, when code was maintained or reused it often resulted in security issues.
Hate to break it to you, but people are still trying to prove how ‘clever’ they are. Generally resulting in more complex and heavyweight code…
Good reason for a programmers first job to be maintaining preexisting code bases.
Drop the old code and write new smaller code that better fits current requirements
Clever? no. But a 5% reduction in the number of servers google needs in order to host gmail more than makes up for their salary.
“Moore’s Law = Software Optimization Advancement Flaw”
its why i love arduino… optimization is still strong in that field! I managed to get a full web server, NTP, email, sd card logging, temp sensing, LCD touch screen control all on an mega 2560. Optimzation is critical!
Absolutely right. Right now with my embedded development project, I can think of at least 5 instances that are very unoptimized. I have little desire to optimize them though because they fulfill my needs and run fine on the platform.
I thought we were making headway with the tight-ish AVRs being so popular… then there were 100Mhz+ ARM CPUs around under $2
Rp2040 over 100 MHz dual core and 0.7 USD!
Having said that, optimized code uses less power. It remains relavant. Any. Its cool.
“the art of optimisation has been steadily fading”
Most programmers who knew how to deal with limited CPU resources have retired by now and their successors often “upgrade” perfectly working code to death.
Automotive.
Optimisation are still very much well and alive in many companies, if your change can bring 10TB annual memory footprint reduction and save $22M, you will get a nice performance bonus
And the rise of bloated inefficient programming languages like Python and Java.
It would be interesting to know if io_uring could improve the performance even more. For details, see https://en.m.wikipedia.org/wiki/Io_uring
Wow, I only understand this on a surface level, bit way cool!
This may be an area where AI can help us by iteratively speeding up this stuff, imagine starting at 1 or 2 GiB/s and then it optimizes itself to 40-50. Might not quite be what we achieve, or might turn into 80GiB! Interesting
Linus used to work at a company called Transmeta, where they worked on a thick firmware system that took x86 code, then converted it to RISC (I think), and then did JIT optimizing so that blocks of code that got hit a lot were repeatedly optimized for speed.
They got away from hardware and focused on licensing their IP, and now it’s in a lot of places, including Intel, Fujitsu, and NVidia, among others.
XD. I had a Transmeta Crusoe III and some VIA Cyrix with that tech way back in the day.
Intel does it super quickly, if you run a cpu test it climbs in speed quickly after a couple iterations. Unfortunately not at a level far back enought to see what the user program is accomplishing to optimize that.
That has more to do with memory caching, but it is true that modern x86 cores have a cache for holding “decoded” x86 instructions too.
They pay a high price for that hefty x86 ISA decoding btw, which is part of why apple’s M1 runs rings around them in power efficiency while having a much wider instruction issuing pipeline.
“Premature Optimization Is the Root of All Evil”
https://stackify.com/premature-optimization-evil/
On the subject of optimization, one of my CS professors quipped “Any program can be made arbitrarily fast if it doesn’t have to be correct.”
Yes, optimization can be a good thing, but its easy to do it wrong.
Non-sense, optimization is essential part of refinement we simply skip often, like many other parts to get delivery faster and further deliveries faster. Making part fast either means more complex or two separate paths with one being fallback, that adds up to costs. Question is whether it’s worth it ? It’s not as simple to answer, we have to take into consideration not only throughput or latency, but also thermal conditions, and power draw which may mean batter life.
What most people have in mind is that people jump too naively or too aggressively at optimization and/or implementation before working out problem and to be fair we most do that, as how many times we write something and throw it away because there turned out to be better way, usually there is no time for that. Personally if one have enough time, writing a prototype or establishing some characteristics of system helps writing it in a way that is aligned with it.
I personally think most people treat optimised code with ugly code, poorly documented and left out with magic constants all over the place.
Instead of citing some words as if they were holy grail I recommend thinking and using gotos ;)
Amdahl, not Ahmdal.
Deserves a lot of credit for the IBM 360 architecture, later jumped ship to set up his own mainframe company.
Exactly! Brilliant man
re. optimisation. I’m not a programmer, but I know my Arduino code would run “faster” if I wrote it in raw assembly, instead of writing it in Arduino code in the Arduino IDE, But the advantage of writing “proper” but slow code in the Arduino IDE is that running that code on a different platform is as simple as setting a new target microcontroller. For example, I started a project on an AVR328 (bog standard Arduino) As the feature creep progressed (an OLED screen, some graphics from an SD card etc) the program became laggy. Could I have optimised the graphics routines? Maybe. A better coder than me probably could:-)
But instead, I could drop in a cortex M0 board, which was pin-compatible. A few voltage tweaks for 3V3 and it was good to go.
I get that if you’re improving servers for Amazon or Google, a few percent of performance is worth millions. But for getting the job done in small-scale stuff, an RPi2040 is cheaper and faster than the AVR328.
I write software for living and I would say that writing code in high level language instead of assembly is usually the best thing to do. That way you can focus on data structures and algorithms better.
When you think data structures and algorithms are so good that those cannot be optimized any further (and trust me, this will take quite some time in most cases), then rewriting the final logic in assembly might allow maybe 1-6x performance boost. However, usually getting a bit faster hardware is more sensible than re-writing the whole thing in assembly.
Mass produced hardware is different situation, though. There re-writing the software may make sense if you can use lesser chip to run the software and you can save $1 per unit. If your company manufactures 10 million units, it’s always worthwhile investment because rewriting the hot code in assembly is not going to cost 10 million dollars. (And even here you definitely want to profile the code to know which parts are taking the time. It’s never the whole program that needs to be optimized.)