
According to researchers at GTSC, there’s an unpatched 0-day being used in-the-wild to exploit fully patched Microsoft Exchange servers. When they found one compromised server, they made the report to Microsoft through ZDI, but upon finding multiple Exchange servers compromised, they’re sounding the alarm for everyone. It looks like it’s an attack similar to ProxyShell, in that it uses the auto-discover endpoint as a starting point. They suspect it’s a Chinese group that’s using the exploit, based on some of the indicators found in the webshell that gets installed.
There is a temporary mitigation, adding a URL-based request block on the string .*autodiscover\.json.*\@.*Powershell.. The exact details are available in the post. If you’re running Exchange with IIS, this should probably get added to your system right now. Next, use either the automated tool, or run the PowerShell one-liner to detect compromise: Get-ChildItem -Recurse -Path -Filter "*.log" | Select-String -Pattern 'powershell.*autodiscover\.json.*\@.*200. This one has the potential to be another really nasty problem, and may be wormable. As of the time of writing, this is an outstanding, unpatched problem in Microsoft Exchange. Come back and finish the rest of this article after you’ve safed up your systems.
Digital Dopplegangers
[Connor Tumbleson] got a weird surprise a couple weeks ago, via an email from another developer, [Andrew], who had been hired to pretend to be [Connor] for a job interview. Say what? This scam is a new one on us, and seems to go like this: Scammer picks a GitHub account with a professional picture and impressive activity, and then goes and creates an Upwork account in that senior developer’s name. This includes a deep dive into the publicly available data on the target developer. Next, our scammer contacts another GitHub account holder, with less impressive credentials — a junior developer, and makes a job offer: work with a development team that doesn’t speak English, doing some development work and working as a face of the team when working with North American clients. The only iffy part of the job is that the new hire will conduct interviews using the name of teammates.
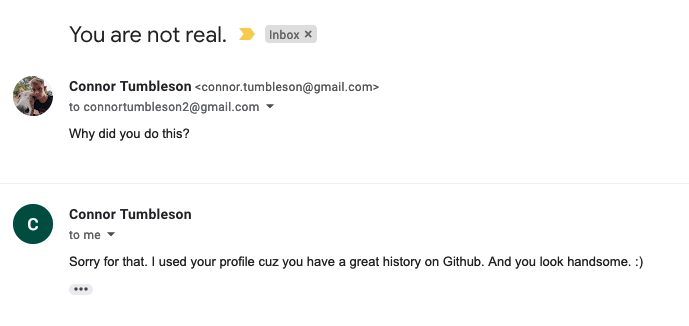
This brings us to [Andrew], who was the “junior dev” in this scenario. It all seemed legitimate, until he realized that the team member he was supposed to be representing wasn’t actually part of the team, and reached out to the real [Connor], who started digging.
It boils down to an employment scam, trying to use the name and reputation of a skilled developer to land a contract. Keep an eye out for fake profiles on Upwork or similar employment sites. And if you get an offer that sounds similar to the one that bit [Andrew], be wary. And finally, if you hired a developer through Upwork, maybe consider whether you really confirmed that your new dev is who they claimed to be.
Changing Times Byte Python in the TAR
For this bug, what we’re gonna do right here is go back, way back, back in time. CVE-2001-1267 was the original tar directory traversal vulnerability. You could include ../ as part of the file path in tarballs, and tar would happily follow the directory path wherever it pointed. Want to overwrite /etc/passwd? No problem. Well, the developers at GNU realized that was a vulnerability, and fixed GNU with version 1.13.20. Fast forward to 2007, and [Jan Matejek] noticed that Python’s tar unpacker had the same problem. After some debate, the issue was decided to be notabug, and closed with documentation updates. The issue was raised *again* in 2017, and never acted upon.
And now, we come to the recent findings by Trellix. Researchers there first thought they had discovered a 0-day in Python, only to realize it was good old CVE-2007-4559, still lurking. Even though the danger was documented, had some Python developers mistakenly introduced vulnerable code into their projects by using the Python tarfile module insecurely? On GitHub, searching for "Import tarfile" language:Python returns 300,000 hits. Checking a subset of those projects returned a 61% vulnerability rate. Yikes!
Chrome Root
Google Chrome is doing something new, that’s potentially controversial, that just might break things — so just another Friday. This one is a bit special, though. Google Chrome is going to begin shipping its own root store. That’s essentially the master list of what HTTPS certificates are considered valid by the browser. The big advantage here is this means that Chrome will behave the same across all platforms, no longer depending on the list of certificates provided by the OS. Of course, this also means that Google controls who gets to use HTTPS. If there is a certificate that has been manually added on the OS side, Chrome will pick it up and also honor it. We’ll see.
Intermittent Encryption, and Other Byte-Sized Stories
Ransomware campaigns have a new trick up their collective sleeves — intermittent encryption. It’s the observation that not every byte in a target file needs to be encrypted, in order to make it unusable for the owner. Encrypting every other 16 bytes makes for faster encryption and slower detection. There are other trends Sentinel One have discovered, like ransomware written in Rust and Go, and even more variations in Ransomware as a Service.
WhatsApp just published an update for iOS and Android that fixes a pair of remote code execution vulnerabilities, both relating to the handling of video. In one case it was an integer overflow reachable through a live video call, and the other was an integer underflow in handling a video file.
Twitter had a really nasty issue, where a password reset didn’t actually invalidate app tokens. So if someone took over an account and logged in on the mobile app, changing the password didn’t terminate access. The problem has been fixed, and anyone affected has been notified.
HP has issued firmware updates for many of their printers, fixing a pair of vulnerabilities that can enable RCE on many of their network printers. There’s not a lot of information about the problem available, but an attacker with persistent network access in an oft-overlooked device is scary enough. Just wait for the inevitable wave of driver vulnerabilities where a malicious printer can trigger arbitrary code execution on a machine trying to print to it.














Sometimes (often) the all-caps headlines are a pain in the TAR. Who can blame the python?
While quite a few of these stories are rather serious news its the Chrome part that makes me most worried personally. When nearly every browser is just Chrome in drag abuse of this could very easily become nearly universally widespread.
The encrypt every x bytes approach is cleaver, but I wonder if it would actually be relatively too easy to decrypt by automated tool. How much fingerprint of the type of file and its content would there be left that means you are not missing enough data to matter, the ‘missing’ byte is in context only plausible to be one of say 3 or 4 options* that when taken in context with the rest of the file can be narrowed down further. I’d not expect a flawless decryption easily, but get close enough a few times and the key used should start to emerge.
*yes those numbers are likely hopelessly optimistic, but I expect hugely varied by file type – something like a video for instance where each frame is nearly identical to the previous ones much of the time may be much easier to partially decrypt. And in the case of an operating system’s files a known clean system to compare to shows up every change made, giving you a size for x and potentially a very large portion if not all of the encryption key for free- as how big will the key really be, its not going to be non-repeating is it?
If you had a raw, uncompressed video, that might work – though with a loss of quality. For any other video – and most type of files – stuff like this is eliminated by compression.
Indeed, as I said hugely varied by file type, but folks that are that bothered by encrypted video probably do have the raw or at least a comparison file exists readily, and even a compressed video when you find one byte in every 16 buggered you know what it should be pretty well despite compression unless its a really really low quality compression content stored as a higher quality file – some minor quality loss still to be expected, but then you got close enough if they encrypt enough of your files you can reverse the whole key from it, as the next time that portion of key rolls around the valid potential values are going to converge.
For instance you could encrypt my music directory, even to the point every file name and structure is gone but doing it this way as I know x,y,z tracks are on there I can scan through the whole thing to find the point at which that track occurs, and I can always buy the source again cheaply… The file is going to be unique enough to find all the chunks of and know what the xth byte was changed to – at which point you get a part of the key used. Do that a few times you might well get the whole key.
“The encrypt every x bytes approach is cleaver, but I wonder if it would actually be relatively too easy to decrypt by automated too”
Problem is now that fox is in the hen house and the damage done. Sure you look for patterns and maybe figure out how to undo the damage with a program, but that takes ‘time’ and computers are idle or off-line. Easier to just ‘restore’ from current backup and done or if using VMs (a past snapshot). May have to go back a ways depending on when the problem is detected, but still get back in business. Seems to me a good backup is solution to all successful ransom attacks, and of course plug the hole that allowed the malware in in the first place. In my way of thinking, ransomware shouldn’t be a huge deal… But I guess there must be places where you talk ‘backup’ and you get a blank stare (what are you talking about?) as it appears to still be a profitable exercise…. Here at home, periodic data backups is just the normal routine. Necessary part of maintaining and using computer equipment. Here at work, the same.
Absolutely, but if you spent several million on everything since the last complete know good backup yesterday/last Sunday/last month (which could easily be low balling it for a big company by orders of magnitude) even after restoring from clean backup you probably want to recover it all if you can, there is so much work locked away. And this encryption method means you probably can get it back really rather cheaply.
You can destroy a company by changing a single byte in a single spreadsheet, an irretrievably wrong decision is made at a big meeting and bankruptcy results. Or you can alter one byte in a build script and introduce malware into every shipping product.
Between software updates and manual configuration changes and uniquely generated keys it is not really possible to determine that a machine is “known clean”. The keys are different on every machine so there is no way to tell if they have been compromised.
Halfway security is no security.
Also you are assuming that the malware is really encrypting the data and not just destroying it, do you really trust the hackers to be carefully encrypting your data so you can recover it?
If their motive is to disrupt your business and waste your time then they will be very successful. All the stuff you talk about is “too late”, “damage control”, the hackers have to be stopped before they gain access to your machines.
Very true, but no matter how good your security is its possible to have a breach.
This is concept for what happens after the excrement has hit the rotating aerofoil – and as it is not in their interests to issue ransomware demand and have it instantly get around they don’t fix what they break even if you pay, as then only one or two suckers will… So applying situational reasoning with a little research you can make that determination as if its worth your time to try a recovery, pay etc.
Also the odds of changing just one byte that matters without a real understanding of what you are changing is basically zip – encrypting the whole file is very different to falsifying it plausibly for gain. Both can be done, and require some similar steps but they are entirely different ‘games’. One of which requires very very selective changes so it does not become obvious the file(s) have been tampered with, which then requires a reasonable degree of comprehension of the whole structure surrounding what you changed – way way more difficult to pull off.
Your comment “the ‘missing’ byte” implies that you think one byte in 16 is encrypted, but the article actually states “[e]ncrypting every other 16 bytes …” which means that 16 bytes are encrypted, then 16 bytes are plain text, and so on. English is highly redundant, but I am willing to bet that this technique would render any plain text effectively unreadable, and numeric files (such as spreadsheets) would be completely sabotaged.
16 bytes missing isn’t very much with context, if you have absolutely no idea what should be in the file maybe it would make no sense, but with some context on the right types of file I expect it to possible to recover the content pretty trivially. Probably even just read it and know what the missing chunks must be, some people are really really great at filling in the blanks – and you don’t need to be able to manually human read every file, just find enough files you can figure out enough details of to put the key back together. Going to cost some compute time decoding n different ways and human time in then reading the files to know the recovered parts are now sane. But you do have a vast amount of the file still untouched.
For instance muddle your or my comments with unknowns every 16 bytes and depending on how the text is encoded you are going to often get enough of two, three maybe even more consecutive words often enough to know what those words almost certainly should be, while you are only likely to actually loose one perhaps two entire words. So with just the tiniest bit of context, so you know its text talking about this encryption scheme the missing bits of words can only be one of a few possibilities. And for things like images (still file type dependent) its way way easier to have a good collection of best fit guesses.
Around a dozen years ago, I read of a way teachers could find if an essay was written by the student, or if the student was handing in someone else’s work.
Every tenth word was blanked out and the essay was handed back to the student to (re)complete. If the student was the original author, they could reconstruct the essay with ~90% accuracy.
> Google Chrome is going to begin shipping its own root store.
Doesn’t Firefox already do this? I seem to recall it had its own certificate store and had been shipping its own for years.
it would explain why some sites are blocked for cert-revoc in some browsers but not others…
all on the same computer/O.S.
the only reasonable explanation is that the two browsers use seperate cert-stores…
most using the O.S.’s
furthermore, why else would firefox even still be used?
firefox’s selling-point was it was lean mean no-nonsense small and fast;
none of which describe today’s version!
but people download it because its one of the few browsers to allow browsing to websites that a malware infection is targeting. esp when said malware is broken and causing a valid site to suddenly stop working for months on end.
i once used firefox to use the web version of windows update (now microsoft update)
to then be able to use windows’s built-in auto-update; the auto-update uses internet-explorer in the backround (winXP) but if the O.S.’s cert for microsoft.com is bcorrupted (pronounced buh-crupted lol)