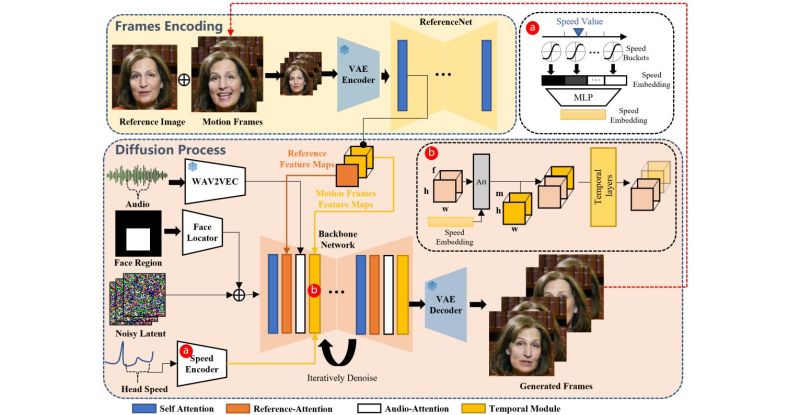
Alibaba’s EMO (or Emote Portrait Alive) framework is a recent entry in a series of attempts to generate a talking head using existing audio (spoken word or vocal audio) and a reference portrait image as inputs. At its core it uses a diffusion model that is trained on 250 hours of video footage and over 150 million images. But unlike previous attempts, it adds what the researchers call a speed controller and a face region controller. These serve to stabilize the generated frames, along with an additional module to stop the diffusion model from outputting frames that feature a result too distinct from the reference image used as input.
In the related paper by [Linrui Tian] and colleagues a number of comparisons are shown between EMO and other frameworks, claiming significant improvements over these. A number of examples of talking and singing heads generated using this framework are provided by the researchers, which gives some idea of what are probably the ‘best case’ outputs. With some examples, like [Leslie Cheung Kwok Wing] singing ‘Unconditional‘ big glitches are obvious and there’s a definite mismatch between the vocal track and facial motions. Despite this, it’s quite impressive, especially with fairly realistic movement of the head including blinking of the eyes.
Meanwhile some seem extremely impressed, such as in a recent video by [Matthew Berman] on EMO where he states that Alibaba releasing this framework to the public might be ‘too dangerous’. The level-headed folks over at PetaPixel however also note the obvious visual imperfections that are a dead give-away for this kind of generative technology. Much like other diffusion model-based generators, it would seem that EMO is still very much stuck in the uncanny valley, with no clear path to becoming a real human yet.
Thanks to [Daniel Starr] for the tip.














I just think where this sort of technology could really be used is instead of translating simply to flat images, you work on translating a 3D mesh– I.e. for so long now the ‘lip-syncing’ of 3D characters in games has been simply utterly *awful*. Something like this would do so much of a better job.
Start from 1999 era animated textures?
That’s pretty amazing. And it can only get better.
Aaaannd, this will instantly be used to make videos of people (ie, politicians) saying things they never said in real life.
Who cares? That already happens
I can think of some politicians I’d like to hear wishing everyone a Happy Pride Month. And maybe expressing their desire for womens’ rights? Perhaps even acknowledging the institutional racism in the country and supporting efforts to eliminate it?
So, perhaps not entirely a bad thing? (I can dream…Nixon: “Yeah, I am a crook, after all”)
More preferably, it will be used by politicians to deny whatever they said in real life was real :D
NVidia CEO : “Everybody in the world is a now a programmer…”
We’re doomed !
I’m going to relocate in an area without electricity and grow my own vegetables.
Yep…. Where are the checks and balances…. Hate to be a politician that has to ‘defend’ against this stuff all the time and still get their job done. Or anyone that has an agenda can ‘speak for you’ and ruin your day…. “See, you said it, we have a video of it” Yowsa. Not a good place to be. Exciting? Not so much. Who really wants it? I bet there is some countries that will love this tech to hold control of their people…. And it only going to get ‘better’ and more realistic.
And remember anything that is said or uploaded ‘stays’ somewhere on the internet. So even if a video (or whatever) is found bogus…. It is still out there for someone to exploit and use…. No tin foil hat here. It just is.
This isn’t exactly new. Those with appreciable resources have been able to engage in this sort of trickery for decades. The only thing that has changed is a lower barrier to entry. In my view, this is a positive because it makes us all acutely aware that media we are exposed to might be forged.
Think of Photoshop, in the days of chemical photography, photo manipulation was entirely possible but people were more likely to fall for a hoax because subtle manipulation was uncommon. Now, anything vaguely non-credible will be accused of forgery because anyone with a computer can do image manipulation.
I’m not sure whether that is the exact quote he said/may have said — Though note, what he definitely did *not* say is “Everybody in the world is now an IC designer !” ;)
Someone should train it to not make the eyes stare … the pupils never move and it’s quite obvious on the Mona Lisa example where she stares directly at the camera like a 1986 local yokle used car salesman
Like many generated videos, you can still spot where it is falling background details because it isn’t consistent, so look at details around the edge of the head and they subtly change.
I’m sure this will be fixed eventually, like the inability to count fingers and teeth in early image generators
These tools are useful for everyone. It even lets you find harmful patterns in comments. Here is what ChatGPT 4-o says about the content of your comment:
– Conspiracy Thinking
– Hostile Intent
– Us vs. Them Mentality
– Extreme Language
– Misinterpretation and Generalization
– References to Specific Individuals
These points suggest that the writer may be experiencing paranoid thoughts, characterized by distrust, suspicion, and a belief in hidden threats.
I’m sure Jensen will hire all these “i dont know how to code” monkeys. :)
It’s impressive, and quite honnestly, the quality is already useable.
Yes, when you know you are looking at an AI generated video in best quality, you will see background glitches or whatever.
But now change the context and the platform.
A video reuploaded on social media on a smartphone, and the glitches are gone (well, pass as encoding artefact). As for the context, well, it depends on what the sender is willing to tell. And if it’s a reupload, fat chance you even know it’s an AI generated content.
I don’t juge here the usage of this tech (is it good or bad), I just point out that all the defaults talked about earlier are moot in daily usage.
This tech is already useable in daily media. Take care of what you see.
“Obvious visual imperfections”… Obvious to who?
Half the US can’t see what is right in front of them, or disbelieves it when they see it. Do you really think some visual imperfection will enter into their thought processes? Or enter in a linear manner? I can see it now- “visual imperfections were added to the recording to make us think that the video was AI generated….”
I wonder if the algorithm would work for animals? I’d love to see a singing ‘possum or a tardigrade.
I wonder if the algorithm would work with the other end of the human digestive tract.