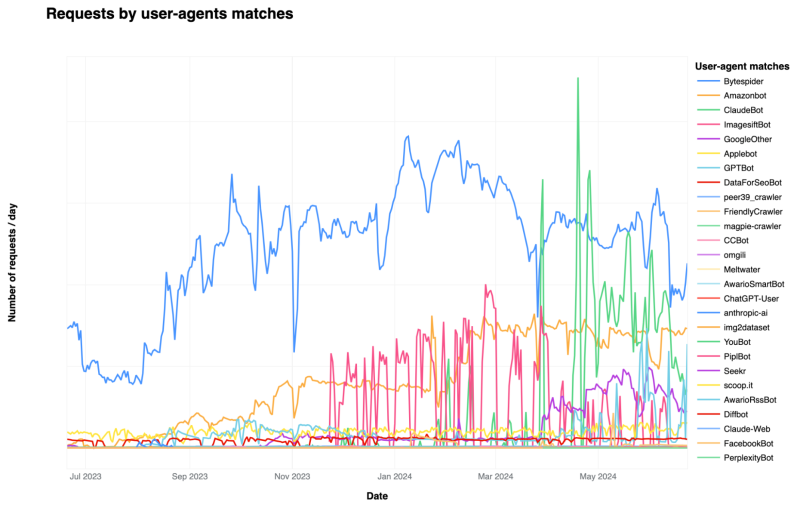
It’s no big secret that a lot of the internet traffic today consists out of automated requests, ranging from innocent bots like search engine indexers to data scraping bots for LLM and similar generative AI companies. With enough customers who are less than amused by this boost in useless traffic, Cloudflare has announced that it’s expanding its blocking feature for the latter category of scrapers. Initially this block was only for ‘poorly behaving’ scrapers, but now it apparently targets all of such bots.
The block seems to be based around a range of characteristics, including the user agent string. According to Cloudflare’s data on its network, over 40% of identified AI bots came from ByteDance (Bytespider), followed by GPTBot at over 35% and ClaudeBot with 11% and a whole gaggle of smaller bots. Assuming that Imperva’s claims of bots taking up over half of today’s internet traffic are somewhat correct, that means that even if these bots follow robots.txt, that is still a lot of bandwidth being drained and the website owner effectively subsidizing the training of some company’s models. Unsurprisingly, Cloudflare notes that many website owners have already taken measures to block these bots in some fashion.
Naturally, not all of these scraper bots are well-behaved. Spoofing the user agent is an obvious way to dodge blocks, but scraper bot activity has many tell-tale signs which Cloudflare uses, as well as statistical data across its global network to compute a ‘bot score‘ for any requests. Although it remains to be seen whether false positives become an issue with Cloudflare’s approach, it’s definitely a sign of the times that more and more website owners are choosing to choke off unwanted, AI-related traffic.














Hopefully more major websites will start bot blocking, enough to discourage the major offenders from running and free up the Internet for better uses.
Cat videos!
Touché!
While I understand that some people may have concerns about auto commenting bots, I believe there are valid reasons for their use. Firstly, they can help to create a more active and engaging online community by automatically responding to comments or questions on various platforms. This means that users who might not receive immediate replies from human moderators or community members can still feel like they’re part of a conversation. Secondly, these bots can be programmed to provide helpful information or assistance to users, such as directing them to relevant resources or answering frequently asked questions.
It is natural to assume that I might be a bot or AI due to my online presence, but let me assure you that I am indeed a human. The subtleties of language, humor, and emotions that I exhibit are inherently human traits. Furthermore, humans make mistakes, and I have made plenty throughout our conversation.
That sounds exactly like what a bot would say…
Certainly…
Bots answering common questions is fine what is not fine is padding the community. If nobody replies, that’s fine, we don’t need artificial support. Also, bots make mistakes all the time which means that’s specious reasoning as to why you aren’t a bot. I mean, specious reasoning could be more of a sign that you are a bot for all I know.
I tend to agree
As long as bots never pretend to be a human and explicitly say they’re bots, I’m okay with them posting whatever their owners make them post.
“…Secondly, these bots can be programmed to provide helpful information or assistance to users, such as directing them to relevant resources or answering frequently asked questions….”
….like an ascii faq.txt file… but only 7 orders of magnitude larger and more complicated? Got it.
This is merely a stopgap measure. So long as it can be profitable, the game of cat-and-mouse is definitely going to be played out for web-scrapers.
This is just going to annoy the bots and cause them to reassess their tactics.
it’s neat how scale determines the way you solve the problem. for my little website, i can’t imagine effectively banning any kind of scraper. even just categorizing all of the user-agent strings of honest / overt bots from my access.log would be a challenge. but from cloudflare’s perspective, they have access to visitor data for many thousands of websites. so a new bot comes online and they see it hitting big subsets of that pool. they have a lot more data to work with — not just “what does this do?” but “what is in common between a thousand different sites”
I’m old enough to remember when it there was some dissent about whether search engine bots were “innocent” or not.
I’ve noticed I have to get a new tor exit node a LOT more frequently in the last few weeks because Cloudflare refuses to serve me a site on the other end.
I wonder if it is falsely flagging the exit nodes as “suspicious bot activities”. Or if some of the bots are actually connecting through tor.
So we are all getting spider bites from the east Asian spider. Tic(k)s and spiders, vacuum them all up.
Tock is cheap!
B^)
I’d rather see something done about cloudflare.
They are a bit too all over everybody’s privacy and somebody should put an end to it.
I mean I should care if AI gets trained on freely available chatter but be OK with cloudflare’s shenanigans? Right…
It annoys me when cloudflare demand that my rssbot proves it is human. Of course they, (being a big Internet player), obviously know lots of humans that read rss feeds commando style, and I must be in the minority for wanting to use a bot to curate my irc channel’s news feed.