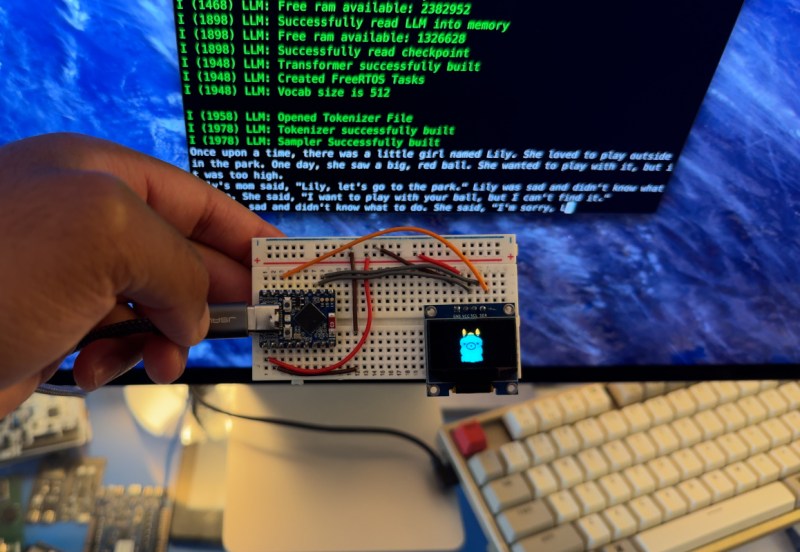
As technology progresses, we generally expect processing capabilities to scale up. Every year, we get more processor power, faster speeds, greater memory, and lower cost. However, we can also use improvements in software to get things running on what might otherwise be considered inadequate hardware. Taking this to the extreme, while large language models (LLMs) like GPT are running out of data to train on and having difficulty scaling up, [DaveBben] is experimenting with scaling down instead, running an LLM on the smallest computer that could reasonably run one.
Of course, some concessions have to be made to get an LLM running on underpowered hardware. In this case, the computer of choice is an ESP32, so the dataset was reduced from the trillions of parameters of something like GPT-4 or even hundreds of billions for GPT-3 down to only 260,000. The dataset comes from the tinyllamas checkpoint, and llama.2c is the implementation that [DaveBben] chose for this setup, as it can be streamlined to run a bit better on something like the ESP32. The specific model is the ESP32-S3FH4R2, which was chosen for its large amount of RAM compared to other versions since even this small model needs a minimum of 1 MB to run. It also has two cores, which will both work as hard as possible under (relatively) heavy loads like these, and the clock speed of the CPU can be maxed out at around 240 MHz.
Admittedly, [DaveBben] is mostly doing this just to see if it can be done since even the most powerful of ESP32 processors won’t be able to do much useful work with a large language model. It does turn out to be possible, though, and somewhat impressive, considering the ESP32 has about as much processing capability as a 486 or maybe an early Pentium chip, to put things in perspective. If you’re willing to devote a few more resources to an LLM, though, you can self-host it and use it in much the same way as an online model such as ChatGPT.














Forget extortionate Raspberry Pi AI add-ons, many SBC processors now have inbuilt neural processing units (NPUs)…and they absolutely book:
https://www.rock-chips.com/uploads/pdf/2022.8.26/192/RK3566%20Brief%20Datasheet.pdf
For my next trick…
👽
NPUs dont help with LLM inferencing.
Sorry, I must be mistaken:
https://github.com/rockchip-linux/rknn-toolkit2
https://github.com/rockchip-linux/rknpu2
Well you could add another esp32
How many esp32 can fit on a board the size of an original Atari or nes?
How well can you glue logic the gpio to do useful work? Cpld and a FPGA fancy custom chip?
LLMs tend to be memory bound is my understanding so perhaps fast peripheral memory is more important than more cores.
The “Large” in “LLM” does not really apply here. If my decision space consists of only two choices, say “heads” and/or “tails”, how difficult can it be to “train” the “LLM”?