‘Hearing voices’ doesn’t have to be worrisome, for instance when software-defined radio (SDR) happens to be your hobby. It can take quite some of your time and attention to pull voices from the ether and decode them. Therefore, [theckid] came up with a nifty solution: RadioTranscriptor. It’s a homebrew Python script that captures SDR audio and transcribes it using OpenAI’s Whisper model, running on your GPU if available. It’s lean and geeky, and helps you hear ‘the voice in the noise’ without actively listening to it yourself.
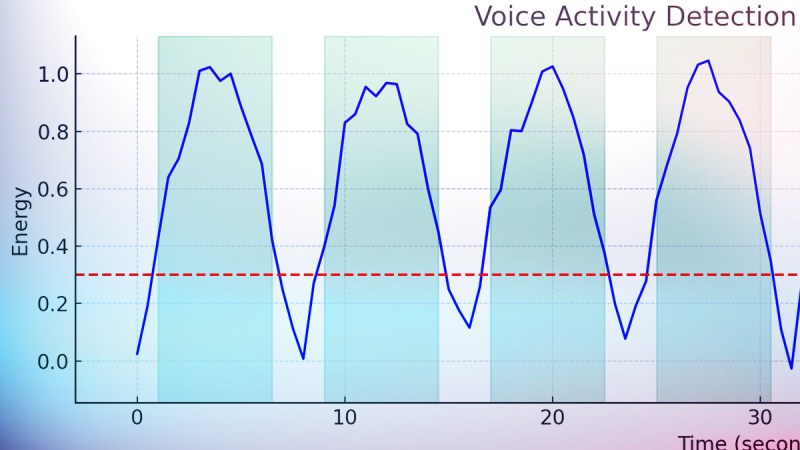
This tool goes beyond the basic listening and recording. RadioTranscriptor combines SDR, voice activity detection (VAD), and deep learning. It resamples 48kHz audio to 16kHz in real time. It keeps a rolling buffer, and only transcribes actual voice detected from the air. It continuously writes to a daily log, so you can comb through yesterday’s signal hauntings while new findings are being logged. It offers GPU support with CUDA, with fallback to CPU.
It sure has its quirks, too: ghost logs, duplicate words – but it’s dead useful and hackable to your liking. Want to change the model, tweak the threshold, add speaker detection: the code is here to fork and extend. And why not go the extra mile, and turn it into art?













As far as I can tell, this is getting its input from your computer’s microphone / audio in, not an SDR. I guess you could use a virtual audio interface to get the audio from some other program that’s actually driving the SDR.
it’s a whole new world for ghost hunters, automating the ability for humans to find patterns where there are none! It could also look for messages from Beezlebub in the clouds or investment opportunities in stock market churn
This automates something that has been done since the Victorian era, trying to find ghost voices where there are none.
Point it at the center of the galaxy and dial up the gain until it hallucinates Azathoth’s gibbering voice. Might be good for a laugh?
Or it hears a lone voice of a starship captain echoing though the cosmos….”Kaaaaahnnn”
😁
AI can translate audio to text with meny noises too?
Many people cant hear your ham sign ,
Are you having a stroke?
It might be ok for semi-automated ham logging, assuming it can filter noise enough to grab a call sign, the signal report, and location. The ears are pretty good discriminators and will likely do better on edge case signals, but still for the meat of logging, it will be worth a look.
For noisy situations, like you mention, it might work as it’s reduced bandwidth which we do all the time, it’s worth experimenting, and I think there are other signal processing tricks that could be put in place to get enough of the original signal, to get a better transcription.
Contest reliable is not going to be it, it might be an adjunt to add one more hint to understanding that weak dx qso.
One of the problems (or sources of great fun depending on your point of view) with AI is that it creates AP – artificial pareidolia – the “the tendency for perception to impose a meaningful interpretation on a nebulous stimulus, usually visual, so that one detects an object, pattern, or meaning where there is none.”
We’ve seen this in a lot of the online image creators from “deep dream” weirdness to various AI imagery, sound creation, and video. I can’t imagine what spurious correlations will be created out of “voices from the æther”, but I’d bet the video will be even better.
Funny, so that’s not unlike us people. There is a lot of meaning being constructed by our minds just because we want to see meaning where it’s just entropy of some kind. Guess AI is the correct term then.
Man I miss the psychedelic Deep Dream fractal dog faces all over everything. That was when genAI seemed interesting and fun, and not merely an artstation/danbooru knockoff slophose
Would be interesting to plug in the audio from some numbers stations, or whatever various HF frequencies militaries or other authorities are known to use.
Would possibly be a handy AR accessibility feature for people who have mid-range hearing loss and have a hard time picking voices out of a crowd
It’s about time to make a voice version of the RBN so Morse-illiterate hams can also tell if their signal is getting out.