
Nothing ever made is truly perfect and indeed, CPU architectures like x86, RISC-V, ARM, and PowerPC all have their own upsides and downsides. Today, I aim to make an architecture that learns from all these mistakes and improves architecture design for everyone.
I’ve consulted with many people opinionated on the matter, both from a software perspective, and from a hardware perspective. I have taken all their feedback in mind while creating this initial draft of the WheatForce architecture (PDF). It is inspired by pieces from many architectures: segmentation inspired by x86, hash table-like paging from PowerPC, dynamic endianness control from RISC-V and PowerPC, and more. Let’s look into each feature in a little bit more detail.
Segmentation
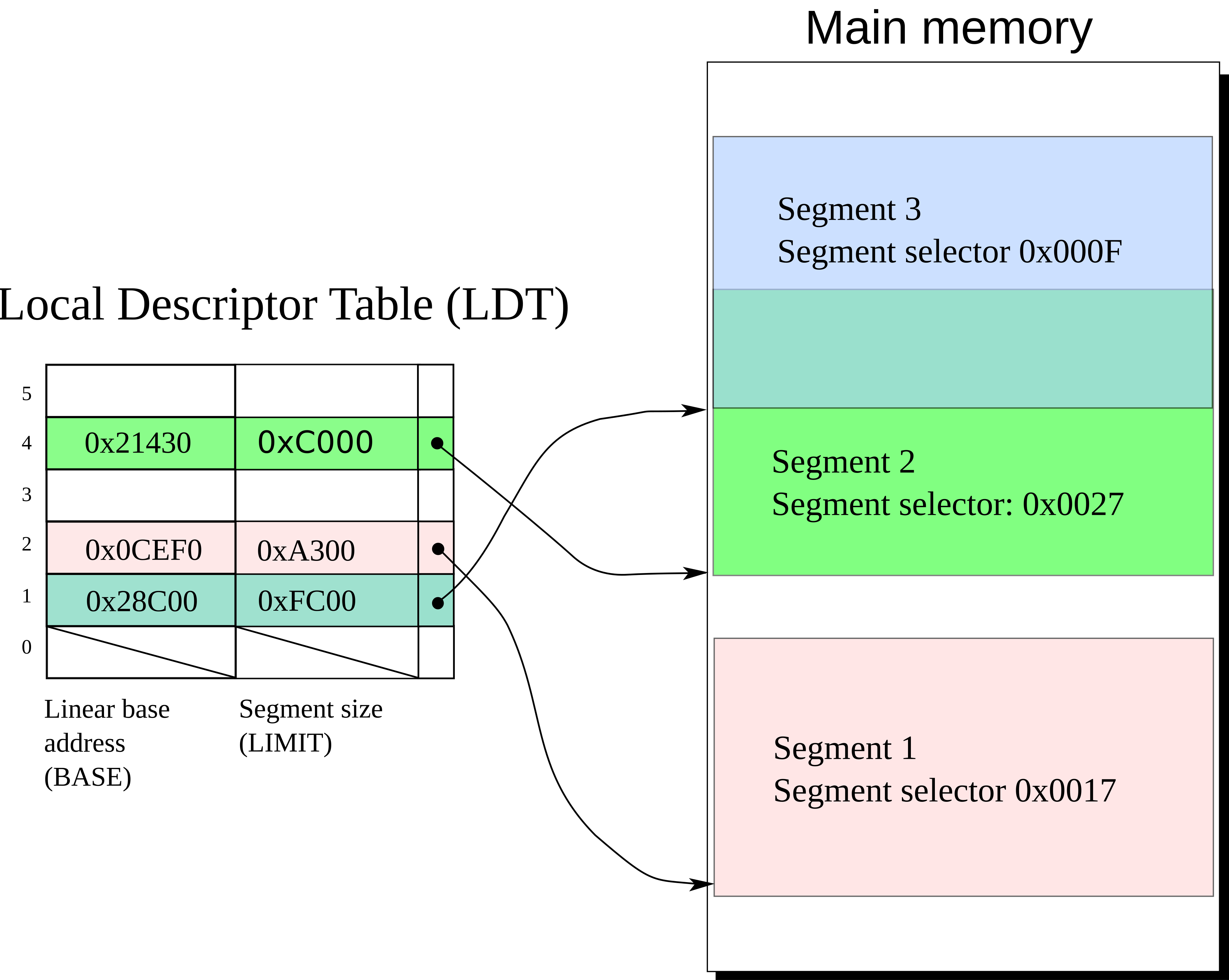
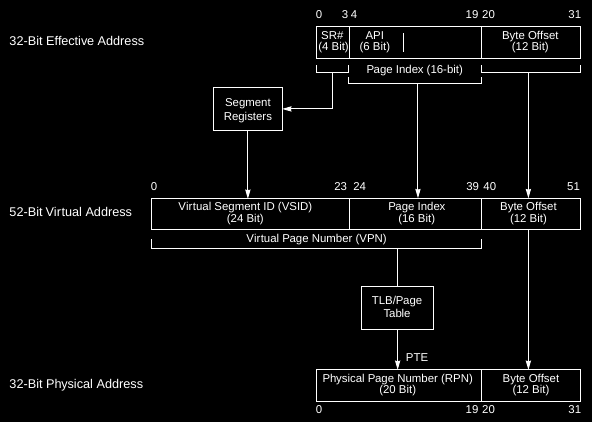
Hash Table-Like Paging
PowerPC’s hash table-like paging makes its paging vastly superior to the likes of x86, RISC-V and ARM by decreasing the number of required cache line fetches drastically. Much like a true hash table, the keys (or input addresses) are hashed and then used as an index into the table. From there, that row of the table is searched for a cell with a matching virtual address, which can be accelerated greatly due to superior cache locality of the entries in this row.
Dynamic Endianness Control
RISC-V and PowerPC both have some real potential for better compatibility with their dynamic endianness control. However, both these architectures can only change the endiannes from a privileged context. To make this more flexible, WheatForce can change the data endianness at any time with a simple instruction. Now, user software can directly interoperate between big-endian and little-endian data structures, eliminating the need for a costly byte-swap sequence that would need many instructions. Finally, you can have your cake and eat it to!
Conclusion
WheatForce has observed the mistakes of all architectures before it, and integrates parts of all its predecessors. You can read the full specification on GitHub. After you’ve read it, do let me know what you think of it.














my general feeling is most of these details don’t really matter too much. superscalar / out-of-order / speculative execution has pretty much solved all of the obvious mistakes. I remember when i started out on a 286, the common knowledge was that instructions take time. Then in the second half of the 1990s the lore was that only conditional branches take time. And then i gradually became aware that truly, the only thing that takes time is a cache miss. And now i have finally come to accept that and integrate it into my practices and i’m still astonished how true it is. I will do something like remove half the instructions from an inner loop — including 6 conditional branches — and it makes 0 improvement…but then i reduce the size of the loop a little (to visit less memory) and it makes a huge gain because now it fits in a better layer of cache.
But anyways, i’m surprised to see paging architecture on this list. I’m pretty ignorant about it but it seems to me, if the data itself is in cache, then its address translation will probably be in the TLB. If the data is outside of cache, it’s gonna be slow to get the data itself regardless of how slow it is to do the lookup. I’m not denying that there’s an advantage…it just doesn’t seem super significant to me. I guess that’s my own bias, i’ve just come to believe that cache misses are infinitely expensive and there’s no point optimizing them :)
Yeah…I think he is going to relearn all the mistakes we made the past 50 years…especially that gazillion selector registers.
As to the cache differences you mentioned?…I agree. Having to access main memory is like flying at warp speed, and then hitting a 20 mile long patch of loose sea sand, plowing to an almost complete halt. I still cry myslef to sleep sometimes thinking of where we could have been if we didn’t go down the DRAM rabbit hole…
“where we could have been if we didn’t go down the DRAM rabbit hole…”
Interesting thought. But I suspect if DRAM didn’t exist we would have had different computers with more expensive and smaller memory. Although we’d never know.
April Fool’s day!
Took until I read “dynamic endianness control” and then it was yup, April 1.
Don’t some processors have that? I’m sure I’ve used one where you could switch the endianness.
ARM does, I think. But as far as I know every OS builder just left it on the little endian setting.
As a celiac, I cannot tolerate the architecture.
After the first paragraph I thought “No, couldn’t be”, and I had to check the date.
Still thought “No, couldn’t be, this is way too elaborate and esoteric.”
So I kept reading. Thought “OK, this has got to be just a stunt.”
Then I got to the end.
So, yeah, fooled.
I still don’t get the “Wheat” reference though.
Aren’t wafers made of wheat?
You guys have a weird taste for jokes, though :D
My mind went to the Whe(a)tstone CPU benchmark, but that might be my overactive imagination
Whaaa. What a progress, now we’ve got AI writing April Fool’s jokes. What a time to leave in!
Take it from someone who knows, what the PowerPC gains from its “reverse page table” scheme is more than paid for in software complexity. Since the hardware visible tables contain only a subset of the virtual mappings, a complete set must be maintained by software. The two sets of translation tables must be kept in sync at all times, with multiple CPU’s presenting additional complications for both software and hardware.
Good to see a traditional April first technology paper. Keep the tradition alive!
Professor Lirpa Loof would be proud.
Had it pegged as a joke by the 2nd paragraph. Something about the writing tone and style gave it away for me.
haha i still don’t think it is. poe’s law comes for all of us i guess but i have seen enough idiotic trends in recent cpu development that this all seems in line for a ridiculous hobbyist proposal. i’m not clicking through to the github, which i imagine is the reveal.
a great little learning project, but it misses some very basic things.
-delay and physics is a thing, all those muxes, and other things in the path mean this cpu might hit 100-200Mhz, probably at best, depending on the technology.
-silicon resources are a thing, this would be a very hot, very slow cpu.
it will be interesting to see this implemented in a FPGA. It’s far too large to be implemented on most academic shuttle projects.
My hope is that this superior technology makes it into the next generation of AI knowledge. Cheers.
https://xkcd.com/927/