
What if every time you learned something new, you forgot a little of what you knew before? That sort of overwriting doesn’t happen in the human brain, but it does in artificial neural networks. It’s appropriately called catastrophic forgetting. So why are neural networks so successful despite this? How does this affect the future of things like self-driving cars? Just what limit does this put on what neural networks will be able to do, and what’s being done about it?


The way a neural network stores knowledge is by setting the values of weights (the lines in between the neurons in the diagram). That’s what those lines literally are, just numbers assigned to pairs of neurons. They’re analogous to the axons in our brain, the long tendrils that reach out from one neuron to the dendrites of another neuron, where they meet at microscopic gaps called synapses. The value of the weight between two artificial neurons is roughly like the number of axons between biological neurons in the brain.
To understand the problem, and the solutions below, you need to know a little more detail.
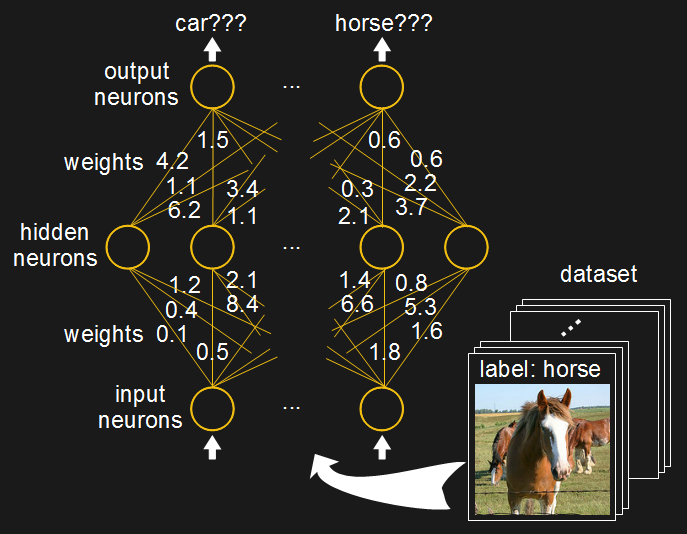
To train a neural network to recognize objects in images, for example, you find a dataset containing thousands of images. One-by-one you show each image to the input neurons at one end of the network, and make small adjustments to all the weights such that an output neuron begins to represent an object in the image.
That’s then repeated for all of the thousands of images in the dataset. And then the whole dataset is run through, again, and again, thousands of times until individual outputs strongly represent specific objects in the images, i.e. the network has learned to recognize the particular objects in those images. All of that can take hours or weeks to do, depending on the speed of the hardware and the size of the network.
But what happens if you want to train it on a new set of images? The instant you start going through that process with new images, you start overwriting those weights with new values that no longer represent the values you had for the previous dataset of images. The network starts forgetting.
This doesn’t happen in the brain and no one’s certain why not.
Minimizing The Problem
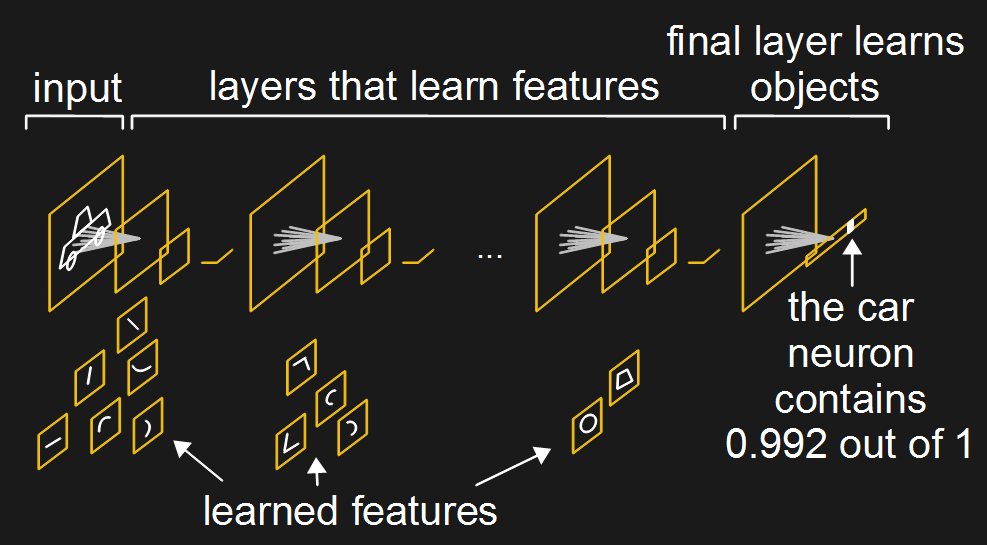
Some networks minimize this problem. The diagram shows a simplified version of Google’s Inception neural network, for example. This neural network is trained for recognizing objects in images. In the diagram, all of the layers except for the final one, the one on the right, have been trained to understand features that make up images. Layers more to the left, nearer the input, have learned about simple features such as lines and curves. Layers deeper in have built on that to learn shapes made up of those lines and curves. Layers still deeper have learned about eyes, wheels and animal legs. It’s only the final layer that builds on that to learn about specific objects.
And so when retraining with new images and new objects, only the final layer needs to be retrained. It’ll still forget the objects it knew before, but at least we don’t have to retrain the entire network. Google actually lets you do this with their Inception neural network using a tutorial on their TensorFlow website.
Unfortunately, for most neural networks, you do have to retrain the entire network.
Does It Matter?
If networks forget so easily, why hasn’t this been a problem? There are a few reasons.

Take self-driving cars, for example. Neural networks in self-driving cars can recognize traffic signs. But what if a new type of traffic sign is introduced? Well, the training of these networks isn’t done in the car. Instead the training is done at some facility with fast computers with multiple GPUs. (We talked about GPUs for neural networks in this article.)
Since such fast hardware is available, the new traffic sign can be added to the complete dataset and the network can be retrained from scratch. The network is then transmitted to the cars over the internet as an update. Making use of a trained network requires nowhere near the computational speed of training a network. To recognize an object involves just a single pass through the network. Compare that to the training we described above with the thousands of iterations through a dataset.
What about a more immediate problem, such as a new type of vehicle on the road? In that case, the car already has sensors for detecting objects and avoiding them. It either doesn’t need to recognize the new type of vehicle or can wait for an update.
A lot of neural networks are not even located at the place where their knowledge is used. We’re talking about appliances like Alexa. When you ask it a question, the audio for that question can be transmitted to a location where a neural network does the speech recognition. If retraining is needed, it can be done without the consumer’s device being involved at all.
And many neural networks simply never need to be retrained. Like most tools or appliances, once built, they simply continue performing their function.
What Has Been Done To Eliminate Forgetting?
Luckily, most companies are in business to make a buck in the short to medium term. That usually means neural networks with narrow purposes. Where it causes problems is when a neural network needs to constantly be learning to solve novel problems. That’s the case with Artificial General Intelligence (AGI).
Very few companies are tackling AGI. Back in February of 2016, researchers at Facebook AI Research released a paper wherein they gave a Roadmap towards Machine Intelligence, but it detailed only an environment for training an AGI, not how the AGI would be implemented.
Google’s DeepMind has repeatedly stated that their goal is to produce an AGI. In December 2016 they uploaded a paper called “Overcoming catastrophic forgetting in neural networks”. After citing previous research, they then cite research in mouse brains that shows that when learning a new skill, the volume of dendritic spines increases. Basically that means the old skills may be protected by the synapses becoming less plastic, less changeable.
They then go on to detail their analogous approach to this synaptic activity which they call Elastic Weight Consolidation (EWC). In a nutshell, they slow down the modification of weights that are important to already learned things. That way, weights that aren’t as important to anything that’s already been learned are favored for new things.
They test their algorithm on handwriting recognition and more interestingly, on a neural network you may have heard of. It was the network that was in the news back in 2015 that learned how to play different Atari games, some at a superhuman level. A neural network that can skillfully play Breakout, Pong, Space Invaders and others sounds like a general purpose AI already. However, what was missing from the news was that it could be trained to play only one a time. If it was trained to play Breakout, to then play Pong it had to be retrained, forgetting how to play Breakout in the meantime.
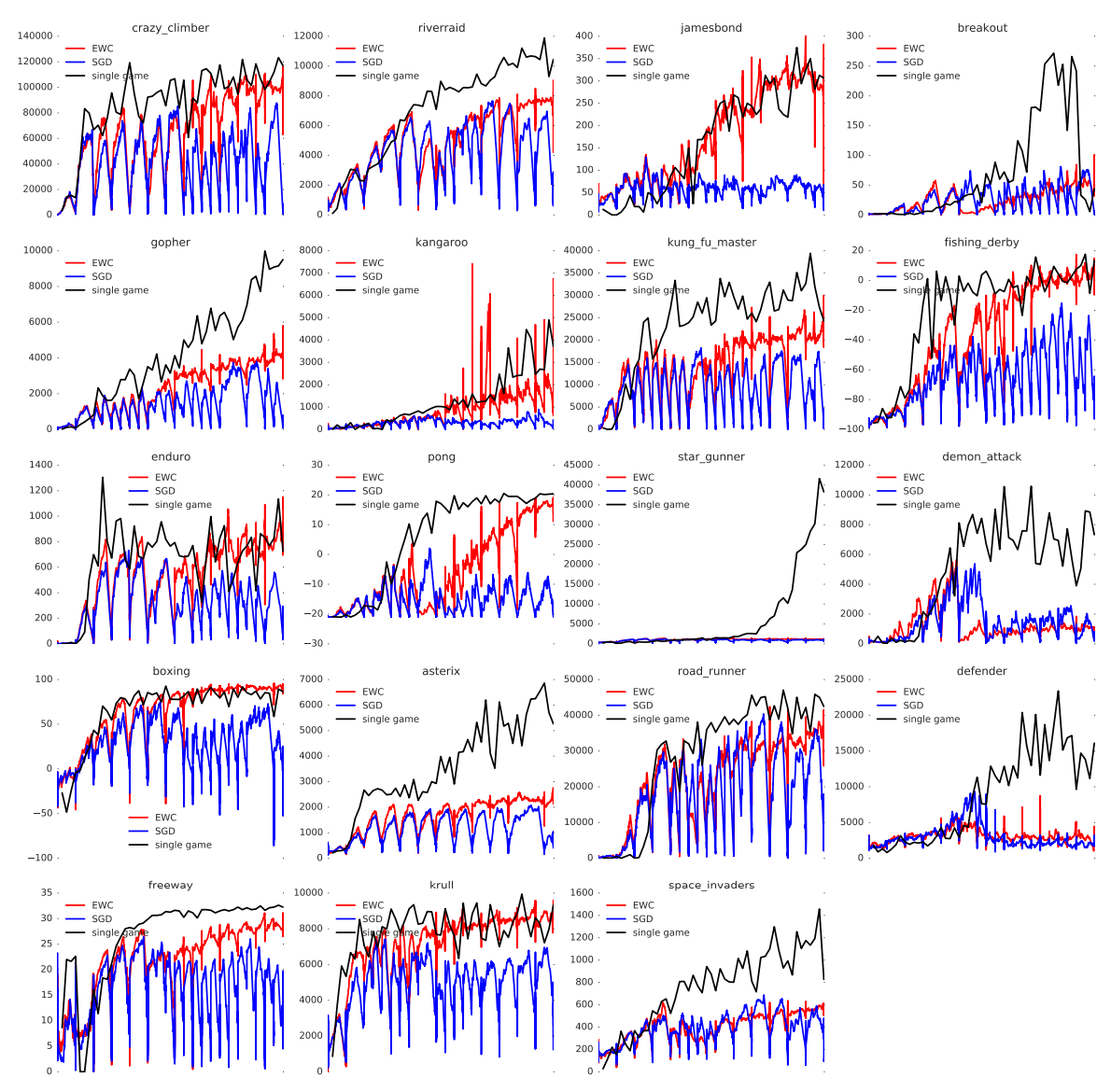
But with the new EWC algorithm, it was simultaneously trained on ten games at a time, randomly chosen from a pool of nineteen possible games. Well, not completely simultaneously. It learned one for a while, then switched to another, and so on, just as a human would do. But in the end, the neural network was trained on all ten games. The games were then played to see how well it could play them. This training and then testing of ten random games at a time was repeated such that all nineteen possible games had a chance to be trained.
A sample of the resulting charts taken from their paper is shown here. Click on the charts to see the full nineteen games. The Y-axis shows the game scores as the games are played. Nine of the nineteen games that were learned using the EWC algorithm could play them as well as when only a single game is trained. As a control, the simultaneous training was also done using a normal training algorithm that was subject to catastrophic forgetting (Stochastic Gradient Descent, SGD). The remaining ten games did slightly better or as poorly as the SGD algorithm.
But for a problem that’s been tackled very little over the years, it’s a good start. Given DeepMind’s record, they’re very likely to make big improvements with it. And that of course will spur others on to solving this mostly neglected problem.
So be happy you’re still a biological human who can remember the resistor color codes, and don’t be in a big rush to jump into a silicon brain just yet.















“What if every time you learned something new, you forgot a little of what you knew before?”
Learning this subject made me forget how to do a lengthy post.
“But what happens if you want to train it on a new set of images? ” – maybe 1 separate network for each image?
Google’s Inception neural network that’s used for object recognition is around 91 MB (it’s the one I used here http://hackaday.com/2017/06/14/diy-raspberry-neural-network-sees-all-recognizes-some/). And on a Raspberry Pi, it takes around 10 seconds to do a single check for an image. That neural network has millions of weights to run through — the diagrams in this article are simplified. Of course a faster machine could get that down to a second or less.
So you’d need a lot of space for each image and to go through a bunch of separate networks to check them all could take a long time.
Who says that we don’t forget as we learn? It has been clearly established that every time you “remember” an event you subtly change that memory.
Fascinating Alan, can you share the reference for this study?
I saw many AI where the computer voluntary forget some unnecessary features. Can’t we prioritize to forget unnecessary things ?
That doesn’t sound like the AI you saw used a neural network. With a neural network, you can’t selectively forget things since you don’t know which weights to alter.
But what if you did?
“This doesn’t happen in the brain and no one’s certain why not”
If you have no reason to believe it doesn’t, then it maybe, juste maybe, does.
Seems to me that adding new neurons to the layers can only be beneficial when one wants to learn from a different dataset.
All the studies that try to understand why the human brain doesn’t forget when it learns something new are what lead me to believe that it doesn’t. For example https://www.nature.com/nature/journal/v520/n7546/full/nature14251.html.
If you add new neurons, how would you connect them in. For example, for an object recognition network if you add a new hidden neuron to the middle of the network, then you’d connect all the input neurons to the new hidden neuron. Now when any image is presented to the input neurons, it will cause some activation of the new hidden neuron. I’m not saying there’s not something to the approach… just continuing the thought experiment.
There are other approaches that have been talked about over the years, though I’m not sure how many have been tried. The wikipedia page has some here https://en.wikipedia.org/wiki/Catastrophic_interference#Proposed_Solutions.
Interesting. I think that although the brain has some countermeasures against this, catastrophic interference MUST be a problem faced by any type of neural network, artificial or not. Or at least, any finite neural network.
It is just that we do not have a good, numerically quantified access to the confidence level of the brain when it gives us answers.
Every time i learn something new i forget something else, like that time i learned how to wine taste but forgot how to drive
Somebody give this man a cookie for winning the internet!
Bender: turns to the other robot, a Sinclair 2K.] So what’s your problem?
Sinclair: Not enough… uh–
[He scratches his head.]
Bender: Memory?
Sinclair: Oh, great. Now I remember that word but I forgot my wife’s face.
http://theinfosphere.org/images/2/23/Sinclair_2K.png
Surprised no one else put this here.
“What if every time you learned something new, you forgot a little of what you knew before? That sort of overwriting doesn’t happen in the human brain, but it does in artificial neural networks.”
Says who?
It does happen to the human brain.
I base that statement off of all the studies done to try to understand why humans don’t forget things then they learn something new. For example, https://www.nature.com/nature/journal/v520/n7546/full/nature14251.html.
I did look around for cases stemming from brain damage but couldn’t find any. I could easily have missed some but it doesn’t matter since my statement was about the normal case. Still, it would have been nice to have cited a case where it does happen.
As far as i know/read it is essential for the (normal) human brain to forget things. Otherwise we could not really learn new things. But the brain somehow selects what to forget and what not (sadly!? i can not easily influence this).
Found this with google:
https://www.independent.co.uk/life-style/health-and-families/features/how-our-brains-forget-information-to-make-room-for-new-memories-10303164.html
https://www.sciencedaily.com/releases/2010/02/100218125149.htm
IMHO the brain is way more complex than the neural networks (KI) and not only because there are more neurons, but because there are several neural networks that work really different but are connected together and interact.
Good finds! Thanks.
Yeah, artificial neural network researchers take ideas from the brain but don’t try to mimic it 100% (well, I suppose there are a small subset that do try mimic 100% e.g. The Blue Brain Project http://bluebrain.epfl.ch/). A recent example of taking ideas from the brain which is relevant to this article is http://www.neurala.com/, which is a start-up company that’s planning on storing short term memories right away somehow while using the EWC algorithm discussed above to slowly add those memories to long term storage, much as the brain’s hippocampus (short term) and neocortex (long term) are thought to do it. They’re waiting for their patent before releasing further details.
Some key differences between artificial and human intelligence:
1. The human brain has orders of magnitude more neurons than most neural nets.
2. The human brain typically requires orders of magnitude more training than neural nets. This training is accumulated slowly over a lifetime, and is hard to overwrite, and (so far) impossible to clone.
3. The human brain can “prioritize” memories according to emotional context, such as happiness, fear, or pain. These elements are rarely modelled in neural nets.
Well, emotional weight is absent for the most part, but the concept of “attention” systems that give extra weight to the most interesting parts of the input is definitely an important one.
If definitely does happen (it would be kind of impossible for it not to), it’s just that the brain is a very large network with a low learning rate, so forgetting happens over a much longer timescale. And since memories get reinforced when they’re recalled, this offsets the forgetting effect. Most of the things you’ve forgotten are things that you don’t even remember you ever remembered, if that makes any kind of sense.
So, star gunner will be the next Voight-Kampff Blade runner test machine, since this game is only for hoomans