
Want to sound great on a Piano using only your coding skills? Enter Piano Genie, the result of a research project from Google AI and DeepMind. You press any of eight buttons while a neural network makes sure the piano plays something cool — compensating in real time for what’s already been played.
Almost anyone new to playing music who sits down at a piano will produce a sound similar to that of a cat chasing a mouse through a tangle of kitchen pots. Who can blame them, given the sea of 88 inexplicable keys sitting before them? But they’ll quickly realize that playing keys in succession in one direction will produce sounds with consistently increasing or decreasing pitch. They’ll also learn that pressing keys for different lengths of times can improve the melody. But there’s still 88 of them and plenty more to learn, such as which keys will sound harmonious when played together.
 With Pinao Genie, gone are the daunting 88 keys, replaced with a 3D-printed box of eight arcade-style buttons which they made by following this Adafruit tutorial. A neural network maps those eight buttons to something meaningful on the 88-key piano keyboard. Being a neural network, the mapping isn’t a fixed one-to-one or even one-to-many. Instead, it’s trained to play something which should sound good taking into account what was play previously and won`t necessarily be the same each time.
With Pinao Genie, gone are the daunting 88 keys, replaced with a 3D-printed box of eight arcade-style buttons which they made by following this Adafruit tutorial. A neural network maps those eight buttons to something meaningful on the 88-key piano keyboard. Being a neural network, the mapping isn’t a fixed one-to-one or even one-to-many. Instead, it’s trained to play something which should sound good taking into account what was play previously and won`t necessarily be the same each time.
To train it they use data from the approximately 1400 performances of the International Piano e-Competition. The result can be quite good as you can see and hear in the video below. The buttons feed into a computer but the computer plays the result on an actual piano.
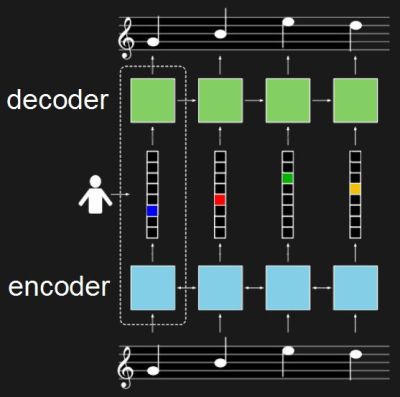
For training, the neural network really consists of two networks. One is an encoder, in this case a recurrent neural network (RNN) which takes piano sequences and learns to output a vector. In the diagram, the vector is in the middle and has one element for each of the eight buttons. The second network is the decoder, also an RNN. It’s trained to turn that eight-element vector back into the same music which was fed into the encoder.
Once trained, only the decoder is used. The eight-button keyboard feeds into the vector, and the decoder outputs suitable notes. The fact that they’re RNNs means that rather than learning a fixed one-to-many mapping, the network takes into account what was previously played in order to come up with something which hopefully sounds pleasing. To give the user a little more creative control, they also trained it to realize when the user is playing a rising or falling melody and to output the same. See their paper for how the turned polyphonic sound into monophonic and back again.
If you prefer a different style of music you can train it on a MIDI collection of your own choosing using their open-sourced model. Or you can try it out as is right now through their web interface. I’ll admit, I started out just banging on it, producing the same noise I would get if I just hammered away randomly on a piano. Then I switched to thinking of making melodies and the result started sounding better. So some music background and practice still helps. For the video below, the researcher admits to having already played for a few hours.
This isn’t the first project we’ve covered by these Google researchers. Another was this music synthesizer again using neural networks but this time with a Raspberry Pi. And if our discussion of recurrent neural networks went a bit over your head, check out our overview of neural networks.
Continue reading “Piano Genie Trained A Neural Net To Play 88-Key Piano With 8 Arcade Buttons”






![You're still better at Ms. Pacman [Source: DeepMind paper in Nature]](https://hackaday.com/wp-content/uploads/2016/03/deepmind-atari2600-machine-learning.jpg)









