There was a time when you pretty much had to be an assembly language programmer to work with embedded systems. Yes, there have always been high-level languages available, but it took improvements in tools and processors for that to make sense for anything but the simplest projects. Today, though, high-quality compilers are readily available for a lot of languages and even an inexpensive CPU is likely to outperform even desktop computers that many of us have used.
So assembly language is dead, right? Not exactly. There are several reasons people still want to use assembly. First, sometimes you need to get every clock cycle of performance out of a chip. It can be the case that a smart compiler will often produce better code than a person will write off the cuff. However, a smart person who is looking at performance can usually find a way to beat a compiler’s generated code. Besides, people can make value trades of speed versus space, for example, or pick entirely different algorithms. All a compiler can do is convert your code over as cleverly as possible.
Besides that, some people just like to program in assembly. Morse code, bows and arrows, and steam engines are all archaic, but there are still people who enjoy mastering them anyway. If you fall into that category, you might just want to write everything in assembly (and that’s fine). Most people, though, would prefer to work with something at a higher level and then slip into assembly just for that critical pieces. For example, a program might spend 5% of its time reading data, 5% of its time writing data, and 90% of the time crunching data. You probably don’t need to recreate the reading and writing parts. They won’t go to zero, after all, and so even if you could cut them in half (and you probably can’t) you get a 2.5% boost for each one. That 90% section is the big target.
The Profiler
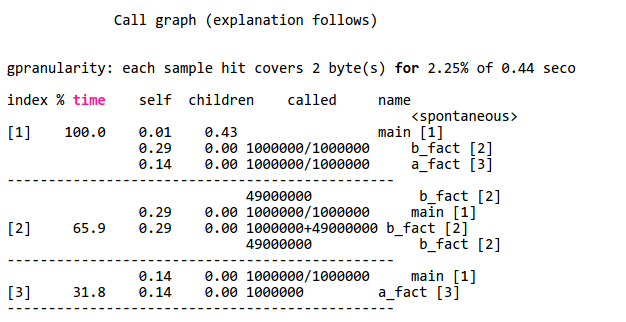
Sometimes it is obvious what’s taking time in your programs. When it isn’t, you can actually turn on profiling. If you are running GCC under Linux, for example, you can use the -pg option to have GCC add profiling instrumentation to your code automatically. When you compile the code with -pg, it doesn’t appear to do anything different. You run your program as usual. However, the program will now silently write a file named gmon.out during execution. This file contains execution statistics you can display using gprof (see partial output below). The function b_fact takes up 65.9% of CPU time.
If you don’t have a profiling option for your environment, you might have to resort to toggling I/O pins or writing to a serial port to get an idea of how long your code spends doing different functions. However you do it, though, it is important to figure it out so you don’t waste time optimizing code that doesn’t really affect overall performance (this is good advice, by the way, for any kind of optimization).
Assembly
If you start with a C or C++ program, one thing you can do is ask the compiler to output assembly language for you. With GCC, use a file name like test.s with the -o option and then use -S to force assembly language output. The output isn’t great, but it is readable. You can also use the -ahl option to get assembly code mixed with source code in comments, which is useful.
You can use this trick with most, if not all, versions of GCC. Of course, the output will be a lot different, depending. A 32-bit Linux compiler, a 64-bit Linux compiler, a Raspberry Pi compiler, and an Arduino compiler are all going to have very different output. Also, you can’t always figure out how the compiler mangles your code, so that is another problem.
If you find a function or section of code you want to rewrite, you can still use GCC and just stick the assembly language inline. Exactly how that works depends on what platform you use, but in general, GCC will send a string inside asm() or __asm__() to the system assembler. There are rules about how to interact with the rest of the C program, too. Here’s a simple example from the a GCC HOWTO document (from a PC program):
__asm__ ("movl %eax, %ebx\n\t"
"movl $56, %esi\n\t"
"movl %ecx, $label(%edx,%ebx,$4)\n\t"
"movb %ah, (%ebx)");
You can also use extended assembly that lets you use placeholders for parts of the C code. You can read more about that in the HOWTO document. If you prefer Arduino, there’s a document for that, too. If you are on ARM (like a Raspberry Pi) you might prefer to start with this document.
So?
You may never need to mix assembly language with C code. But if you do, it is good to know it is possible and maybe not even too difficult. You do need to find what parts of your program can benefit from the effort. Even if you aren’t using GCC, there is probably a way to mix assembly and your language, you just have to learn how. You also have to learn the particulars of your platform.
On the other hand, what if you want to write an entire program in assembly? That’s even more platform-specific, but we’ll look at that next time.














If you spend time experimenting with C++ constructs and looking at the resulting generated assembly from the compiler, you can learn to write your C/C++ code in a way that generates the most efficient assembler. This typically makes my code efficient enough to avoid excessive pure assembly, and I comment the C/C++ code to insure nobody changes it (and thus ruins the efficiency boost). For instance there are ways to finesse the compiler into using all registers for data manipulation and math, rather than stack/heap – to minimize load/stores. You can by writing the C/C++ code hint the compiler to use a shift/rotate instead of a more costly muliply/divide or run time library call. Loops can be unrolled in the C/C++ code if you know the data better than the compiler can guess at it. Be careful of compiler updates :). You can inline functions, etc.
While this sounds useful, it seems like a fragile way to optimize performance. The language abstracts away the details of the compiled units as a convenience. I would rather write readable code in C++ or write performant code in ASM than write code that becomes a trap for the next engineer that comes along.
Agreed it’s fragile, but the C/C++ code remains portable across compilers, which for my employer was an essential requirement. The code has been ported to four different microcontroller architectures. Surprisingly, the finessed C/C++ code remained optimal across three different supplier compilers, and no worse in the 4th.
If that’s ‘surprising’, then it was a poor design choice. Never rely on black boxes’ inner workings.
Compilers are 100% deterministic. A given source code input will always produce the same machine code – or else we’d all be in trouble. In fact – it’s simple to observe exactly how C/C++ constructs get translated into machine instructions by a given compiler. C/C++ written in a simple optimal fashion will produce roughly optimal machine code on different compilers and for CPU’s with similar ALU capabilities. The code just has to avoid expensive holes in the instruction sets of the target processors. There’s nearly zero magic in a compiler designed for an 8 or 16 bit micro. There is some serious cleverness in optimizers for pipelined and out of order CPU’s.
Maybe, but sometimes it does help. Instead of fighting with assembler and addresses for io pins I’ve managed to write some c which done in assembler exactly what I wanted. Looking at c source and what it generated, it seemed almost ike magic when several lines of “PORTB ^= var; var = var << 1;" were compiled into two assembler instructons each.
It’s not that fragile, and I do that all the time as well in my projects. It happens that C was designed to be a portable assembly language. Developers complain all the time that C requires some skills, is a pain to manipulate strings and that they have to take care of everything. But that’s normal : in C the developer takes care of resource usage and algorithms while the compiler turns them into instructions for the selected CPU. With a bit of practice it’s not hard to write C code which produces optimal code for various architectures. I generally focus on x86_64, i386 and armv7. When these ones are good, I’m happy. Also when you manage to make the compiler produce optimal code, it resists to very wide ranges of compiler versions, simply because you don’t force it to do something good, you help it guess the best options. Some optimizations I used to write for gcc 2.7.2 continue to work fine on 5.3. Sometimes you want to prevent the compiler from being smart and it becomes more fragile. After 2 or 3 attempts to fix this upon a compiler upgrade, you generally end up with assembly code just to secure your algorithm.
That’s not really true. I mean, you can do better, sure, but fundamentally, C doesn’t map to assembly perfectly, so it’s possible to need assembly.
The one thing I run into a lot is the lack of a carry bit concept. So you can actually make lots of compares branchless in assembly (by doing math on the carry bit) but not in C.
Apart for trying to make faster code parts using assembly in a c code, one sometimes has to write all code in it. Check out how big program program you can squeeze in a 1k flash mcu using c or assembly. Assembly also comes handy when one needs to write a really small.bootloader.
Har har. Profiling on a properly embedded system. No luxuries like a file system! There might be a spare pio … if you’re lucky. Otherwise you’re down to measuring second order effects. It’s fun in a masochistic way.
It’s not always about getting the fastest code: One reason to use assembly is to have predictable timing, especially when bit-banging, for instance for WS281x LEDs.
Yupp, was about to write the same thing. V-USB is another example of assembly used to predictably fit timing requirements.
On Atari ST some people created higher resolution video modes by switching between official video modes at specific moments within each scan line. IIRC correctly one way of getting the timing right was to use a shift instruction as a variable delay.
Knowing assembly you can view the compiled parts and compare source changes to optimize your c code.
Example, when I have a counter that needs to be resets to 0 , (base 2 boundaries) I use:
cnt = cnt & 0x04;
That one line replaces replaces 2 lines:
cnt++;
If (cnt == 4) { cnt = 0; }
No it does not
My guess is that some of the pasted code was interpreted by the forum software as tags.
How on earth would that piece of code replace those other two lines ?
Maybe you wanted “cnt cnt & 0x03;” ?
You prolly meant 3
But the first line needs a load, and, store.
Other one is a compare, jump, then a store.
Though a jump is worse than an And
what’s wrong with
if (++cnt == MAX_CNT)
cnt = 0;
That block of code is just hardwired in my fingers, and the compiler should be smart enough to optimize it.
White Mike meant was that for wrapping counters, the “increment, and bitwise AND” method (when top is a power of 2) is faster than increment, compare, reset.
x = (x + 1) & (n – 1);
for a comparison see : https://dougrichardson.org/2016/04/18/wrapping_counters.html
so his example would be, assuming top is 4;
cnt = (cnt + 1) & 3;
@bthy, You are correct in what I meant, I apologize everyone, half asleep and I didnt think my thoughts through.
I am including some assembly of the compiled C code:
Advantage is 1 less instruction, as well as knowing the exact timing will always be 4 cycles (I know depends on chip) regardless if it is reset or not.
Code 1:
——————————————–
cnt++;
00DA: INCF 0C,F
If (cnt == 4) { cnt = 0; }
00DC: MOVF 0C,W
00DE: SUBLW 04
00E0: BNZ 00E4
00E2: CLRF 0C
Code 2:
——————————————–
cnt = (cnt++) & 0x03;
00E4: MOVF 0C,W
00E6: INCF 0C,F
00E8: ANDLW 03
00EA: MOVWF 0C
Code 3:
——————————————–
cnt = (cnt + 1) & 0x03;
00EC: MOVLW 01
00EE: ADDWF 0C,W
00F0: ANDLW 03
00F2: MOVWF 0C
Code 4:
——————————————–
if (++cnt == 4)
00F4: INCF 0C,F
00F6: MOVF 0C,W
00F8: SUBLW 04
00FA: BNZ 00FE
cnt = 0;
00FC: CLRF 0C
the compiler is not smart enough
it should be:
INCF 0C, W
ANDLW 3
MOVWF 0C
I don’t get it… Assembly language isn’t difficult or hard. In constrained environments – small PICs for example – it’s the right tool for the job. As 32-bit (and 64-bit) processors become more prevalent, its use will shrink – but it’s not black magic; nor is it unmaintainable. And my guess is the programmer that knows assembler probably does a better job than the one that doesn’t, even today.
I learned assembler for the PIC 8-bit family, and proud of it… but it’s hard to stay efficient if you’re only using it a few times a year. I find I can get back into it faster and write better code in a small C environment like SourceBoost.
I’ve been maintaining AttoBASIC for the AVR since 2011, when I took it over from Dick Cappels. It is still hosted on his web site at cappels.org and on AVRFREAKS.
AttoBASIC is pure assembly at the core. In the time since 2011, I added native support for ATmega88/168/328, ATmega32U4, AT90usb1286, ATmega2560 and now ATtiny85 for 4, 8, 16 and 20 MHz clock speeds and various “modules” to support hardware for the DHT-22, nRF24L01, SPI, TWI, 1-WIRE, etc. Recently I added the original AttoBASIC code for the AT902313, ATmega163 and extended it to the ATmega16/32.
All that flexibility using conditional assembly statements. I even added in various bootloaders like LUFA DFU/CDC, Optiboot, Optiboot85 and STK200v2 (from their perspective sources), which are all written in “C”, compiled, converted to binary image then to specific “.DB” statements to be merged in to the core code during assembly. I also added USB serial I/O support, also written in “C” and the resulting assembly image merged by mapping to particular program address locations and extracting the procedure entry points for AttoBASIC to call.
Its been a daunting task but my point is that it is maintainable in assembly language. Its just a matter of knowing your tools, both MCU specific and the development environment, which in my case is Linux running a WINDOWS XP virtual machine for AVR STUDIO. Although I have had to be VERY creative over the years, it is rewarding to see the Linux build script spit out 98 different variations for 12 different AVR’s at 4 different clock speeds, with UART or USB serial I/O (where supported) and bootloader or not.
At this point, I cannot imagine porting all of this over to “C” in the name of “better maintainability”. Only core code would fit into the smaller 8KB and 16KB FLASH parts if I did. Although I can see a potential advantage in doing so if there ever comes a time when AttoBASIC moves to say the STM32 MCU but that opens up a whole other series of obstacles to stubble on and resolve.
Peace and blessings,
Johnny Quest (and Bandit)
Great insights from the coal face. And congrats on doing a great job. I reckon there’s a really interesting hackaday post that could be gleaned from your experiences…
Wow, wow, and super wow! +1!
Obligatory XKCD coment : http://imgs.xkcd.com/comics/optimization.png
I wish there were more electronic engineer types on these websites. Article point of views are typically that of someone well versed in Linux, but only enough hardware knowledge to calculate a LED resistor. The opposite would be refreshing.
I’m one of those types. Sure, I can install Linux. I can write simple code that reads things from a serial port and stores it in a file or does statistics to it.
It’s fun and I don’t dismiss the utility or beauty of high level programming languages in any way, but I learned ASM first, and keep it closest to my heart.
To read a datasheet. To know with precision how the mind of a machine works. To think a thought with such precision that it can be held there without abstraction. These are things I enjoy, although if it’s practical to replace it all with an op-amp and a filter that makes for a fun day too.
I never enjoyed working with Arduino but I’m really happy other people are having fun with it. I find it too complicated, reading datasheets may be long, but it’s unambiguous and the examples always give me new, exciting ideas or teach me new things.
I threw in the towel on beating the compiler many years ago. I noticed a c compiler for 68HC11 was beating my best tricks, and looking at the code, I found the reason was the compiler has no need to produce readable code structures or avoid dirty tricks that are confusing to human programmers or considered very bad or error prone form (when used by humans). Unless gcc is known to be terrible, I would not bother.
That said, I would still do it on an Arduino project or ARM to get exact timing in access to hardware I/O or in writing a driver so that it is plain to others who read or need to modify the code or verify what it does.
+1, Well put.
Meanwhile on 8 bit micros, where 1 cycle means exactly 1 instruction, it’s really easy to work around default calling convention (context save/restore mess on every call) or interrupt handlers, the superscalar architectures like x86 are a real traps for premature optimizations. Branch/jump predictions, pipelining, out of order execution, dealing with cache misses etc. That’s enough to make expected “slower” code to run twice as fast as the optimized one.
“Meanwhile on 8 bit micros, where 1 cycle means exactly 1 instruction”
wut ?
On an AVR for example, an 8 bit mcu, loads and stores from data space take 2 cycles, lpm takes 3 cycles, and branches take 1 or 2 depending on which path is taken.
pre-fetching helps, but by no means does every instruction execute in one cycle.
i was basing this information on a very old post on avrfreaks.
from wiki :
RAM and I/O space can be accessed only by copying to or from registers. Indirect access (including optional postincrement, predecrement or constant displacement) is possible through registers X, Y, and Z. All accesses to RAM takes two clock cycles. Moving between registers and I/O is one cycle. Moving eight or sixteen bit data between registers or constant to register is also one cycle. Reading program memory (LPM) takes three cycles.
https://en.wikipedia.org/wiki/Atmel_AVR_instruction_set
It was just generalization, (on PIC all intructions takes 1 “machine cycle”). There aro na instructions that can take diffrent amount of cycles to execute depending on many conditions.
that’s the exception to the rule anyway… Most 8 bit processors have instruction sets that vary in terms of the number of cycles. I’m struggling to thing of one that doesn’t off the top of my head. Any takers?
As an ex Disti-FAE with ATMEL being one of my top support lines, on the AVR8 series of MCU’s most instructions DO execute in one (1) clock cycle. Yes, branch instructions are 1 or 2, jumps and calls can be up to 5 depending on the size of program memory and target address. Data transfer instructions to RAM and I/O are 2, or 3 if accessing the program FLASH.
Peace and blessings,
Johnny Quest (and Bandit)
Oh, and I forgot to mention that when ATMEL set out to design the AVR series, they specifically consulted with IAR (“C” compilers) so as to design an architecture that was VERY “C” friendly.
Peace and blessings,
Johnny Quest (and Bandit)
What I don’t like about GCC’s inline assembler is the lack of documentation.
There is no document listing all possible constraints of an architecture apart from the GCC source code.
Want to know how to make GCC emit the upper x86 byte register name of your “r” parameter? It’s documented in the comment preceding the GCC functions print_reg and ix86_print_operand in i386.c.
Also, the binutils are your friends.
Another route to seeing what assembly your source turns into when run through the compiler is to run GCC with -g and then take the resulting binary and pick it apart with
objdump -wS
objdump -wS
Additionally, addr2line is an invaluable demangling tool as you can give it a virtual address and it gives you the source file:line where the instruction at that address came from.
This means you can build a map of all instructions generated by a given line fairly easily which then gives you a fair bit of visibility. Additionally, if you have -pg you probably can also do code coverage analysis with gcov.
If you’re very confident that your test data set is representative of real world workloads (not too hard for many embedded system applications) you could even employ gcc’s profile guided optimization (switches the drop through vs jump aside case for conditional branches to match the unpredicted branch behavior of your CPU architecture and lumps frequently run code together, moderately frequent code next, and rarely run code last for better icache and TLB locality, as well as optimizing rarely run code for size and often fun code for speed).
Then there are things like hardware profiling (oprofile and company) which recent ARM generations support, and even some high end non-ARM microcontroller families like PIC32MZ* (although there you have to write your own profile collection hook unless Microchip has updated their tools).
Nobody can call themselves a hacker without an ability to work with assembly language. You don’t really understand how a computer works without understanding assembly. And it is cool, but I avoid using it like the plague and only use it when there is no other option. Never for optimization. There was a time when that was more common, but I seriously doubt that is the case except in extremely rare situations these days. Your time is almost always better spent in some other way.
Sometimes on an MCU, hand crafted assembly can be the difference between getting something to work, or just not having enough resources to get it to work (at maximum data rate).
I’m thinking of code like this (not mine):
https://github.com/airspy/firmware/blob/master/airspy_m4/airspy_m4.c#L135
Particularly, in an application that generates DDS where your sampling rate is higher when you “hand-craft” an assembly language interrupt service routine (ISR). I’ve seen code for this in both “C”, inline assembly (in “C” code) and pure assembly. The ASM code runs a bit higher sampling frequency.
Also, in “C”, ISR’s generally PUSH most all registers onto the stack upon entry, which is usually about 14 of the 16 registers available, and POP all those registers back off the stack before exiting. In AVR, with 4 or 5 cycles per PUSH/POP operation, a lot of time is spent performing those operations. When hand-crafting an ISR in a “C” program, only the registers used can be PUSH’ed/POP’ed.
Peace and blessings.
Johnny Quest (and Bandit)
If you’re interested in toying around with assembly, https://godbolt.org/ is a very interesting site. It shows you the original C and the generated assembly (for a range of compiler versions, mostly gcc and some clang) side by side. It can colourise the matching lines (which isn’t much help at -O3, but still), you can pass compiler flags, etc.
This compiler explorer is seriously cool
Looking at the assembler has saved my code on more than one occasion, it’s important to be able to look “behind the curtain” as code that looks minimal and elegant can drop out to some hideous assembly.
A friend of mine at college objected to having to write his project in the tutor’s chosen language (Pascal) so the 1st line was the __asm{ delimiter and the entire rest of it was written in x86 assembler which he knew backwards. Got away with it too!
Wish I did more C and higher level language programming.
Although …IMHO, there’s a massive gap between projects which require such processing power and the >90% of projects where a micro-controller module and assembly would have been better suited.
To the modern ‘hacker’, software appears to be the proverbial hammer.
With GCC, an alternative to inlining ASM in C/C++ files is to embed it in a pure assembly (.S) file.
It is for ones that are not affraid to write the whole function in assembly… Because it mean writing yourself function parameters / return value handling (“prolog” and “epilog”).
On the other hand a short ASM block inlined in a classic C function hides this aspect.
That’s the way I do when coding on AVR8, where I used lot of ASM to optimize short routines like frequently called ISR. I make them “”naked” by coding them directly in a .S file.
GCC then does not generate any pro/epilog for this.
There are way to make NAKED ISR in C too, by the way, but it wazs not my topic :)
I’ll play the devil’s advocate here:
You would rarely need to write in assembly these days. It is nice to understand how well/badly the compiler maps your C code to assembly language. There are cases like writing a RTOS that requires assembly to save/restore states and may be startup code. Not many programmers are writing those. Not many are writing their code entirely in bare metal code either. Can’t even get someone to work on a project without mentioning Arduino or other frameworks/libraries.
If you spec out a new project from scratch, you get to choose the microcontroller/processor. It is silly to not pick one with enough resources/hardware peripherals that can do things you need to do without having to squeeze to the last percentage of what’s possible using hand crafted assembly code. If you are the type that spend time to read the documentations and write assembly code, then moving up to a more modern 32-bit chip isn’t that hard. Better chips have better peripherals: e.g. DMA, CRC, USB, more memory, more clock speeds to do thing you’ll need to do.
First, I agree 99% with what you say…. I personally won’t hire anyone who doesn’t have bare metal experience with a micro, this is needed for experience and optimizations.
I do prototype on bigger chips so I can get the project working, but then I optimize my code and shrink it where I can. Everyone says use a bigger chip, it’s just $1 or $2 more and has so much more to offer….. Well guess what, when the company I design for is selling 10,000,000 units/ year and I can reduce the cost $2 a unit, that’s a $20 million dollar savings….. And I get a nice bonus, and that arduino guy is still not getting the point. Sure design on one, but don’t make it the final product.
I know people are going to say it’s good for one offs, but then I can do the same on a $1 chip and be done.
Sorry for the rant
+1 … you’d fit right into a consumer products company where saving a few pennies per few hundred units is considered a big financial success!