
Humans are very good at watching others and imitating what they do. Show someone a video of flipping a switch to turn on a CNC machine and after a single viewing they’ll be able to do it themselves. But can a robot do the same?
Bear in mind that we want the demonstration video to be of a human arm and hand flipping the switch. When the robot does it, the camera that is its eye will be seeing its robot arm and gripper. So somehow it’ll have to know that its robot parts are equivalent to the human parts in the demonstration video. Oh, and the switch in the demonstration video may be a different model and make, and the CNC machine may be a different one, though we’ll at least put the robot within reach of its switch.
Sound difficult?
Researchers from Google Brain and the University of Southern California have done it. In their paper describing how, they talk about a few different experiments but we’ll focus on just one, getting a robot to imitate pouring a liquid from a container into a cup.
Getting A Head Start
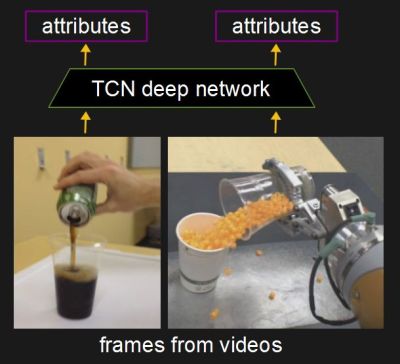
When you think about it, a human has a head start. They’ve used their arm and hand before, they’ve reached for objects and they’ve manipulated them.
The researchers give their robot a similar head start by first training a deep neural network called a Time-Contrastive Network (TCN). Once trained, the TCN can be given an image from a video frame either of a human or robot performing the action and it outputs a vector (a list of numbers) that embeds within it high-level attributes about the image such as:
- is the hand in contact with the container,
- are we within pouring distance,
- what is the container angle,
- is the liquid flowing, and
- how full is the cup?
Notice that nowhere do the attributes say whether the hand is human or robotic, nor any details about the liquid, the container or the cup. No mention is made of the background either. All of that has been abstracted out so that the differences don’t matter.
Training The TCN
Another advantage a human has is stereo vision. With two eyes looking at an object from different positions, the object in the center of vision is centered for both eyes but the rest of the scene is at different positions in each eye. The researchers do a similar thing by training the TCN using two phone cameras for two viewpoints and get much better results than when they try with a single viewpoint. This allows the robot pick out the arm, hand, liquid, container, and cup from the background.

Altogether they train the TCN using around 60 minutes of dual-viewpoint video:
- 20 minutes of humans pouring,
- 20 minutes of humans manipulating cups and bottles in ways which don’t involve pouring, and
- 20 minutes of the robot in a pouring setting but not necessarily pouring successfully.
The latter video of robots in a pouring setting is needed in order for the TCN to create the abstraction of a hand that’s independent of either a human or a robot hand.
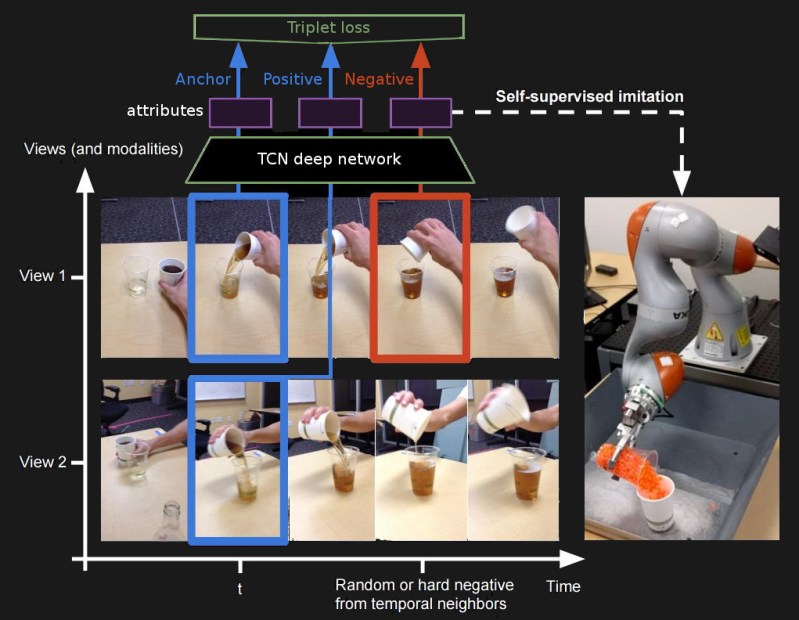
Frames from the videos are given to the TCN one at a time. But for every three frames, a loss is calculated. One of those frames, called the Anchor, is taken from View 1 where the camera is held steady. A second frame, called the Positive, is taken from View 2 where the camera moves around more but from the same instant in time. And the third frame, called the Negative, is taken from a time when things are functionally different. View 2 is moved around more to introduce more variety and motion blur.
A loss value is then calculated using the three frames and is used to adjust the values within the TCN. This results in the similarities between the Anchor and the Positive being learned. it also means that the TCN learns what’s different between the Anchor and the Negative.
The use of different viewpoints helps eliminate the background from the learned attributes. Other things that are different are the lighting conditions and the scale of the objects and so these are also not included in the learned attributes. Had each frame been used one-by-one to learn attributes then all these irrelevant things would have been learned too.
By including the Negative frames, the ones where functionality differs, attributes that change across time are learned, such as the fullness of the cup.
Even different containers, cups and liquids are used so that these can be learned as more abstract or general attributes.
Learning To Imitate
As we said, the TCN is the equivalent of the human head start. It’s where a human already knows about arms, hands, switches and how to reach for objects before being shown how to flip a switch to turn on the CNC. The biggest difference here is that this TCN is trained about cups and liquids instead of switches.
Once the researchers have trained the TCN they’re able to use it to produce an input to a reinforcement learning algorithm to control the robot’s movements.
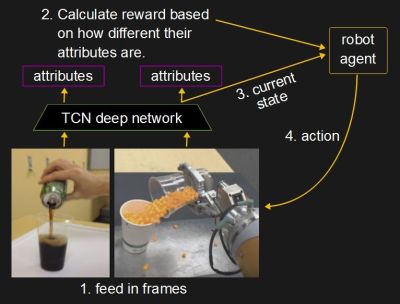
Only a single video of a human pouring a liquid is needed to do the reinforcement learning. Each frame of the video is fed into the TCN as are frames from the robot’s camera. Notice that the points of view and much else are different. But that doesn’t matter since for each of the frames, the TCN is outputting at the more abstract level of attributes such as those we listed above (e.g. are we within pouring distance?). The more similar those attributes are between the two frames the better the robot is doing.
A reward value is calculated and passed on to the robot agent code along with the current state so that it can produce an action. The robot agent is actually a machine learning construct which is being fine-tuned based on the reward. It outputs the next action and the process is repeated. This is called reinforcement learning, the reward reinforces the machine learning construct’s learning.
The end result can be viewed in the following video, along with more of the experiments talked about in the paper.
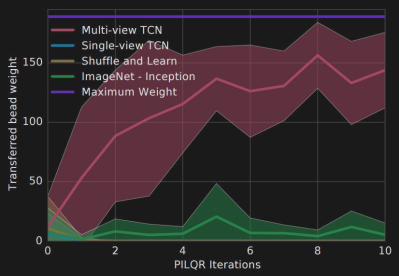
For the chart shown here, there are 10 attempts per iteration. The Multi-view TCN is the algorithm we’ve described here. After around 100 attempts, the 7-DoF KUKA robot consistently pours the orange beads into the cup, but you can see that it was already doing quite well by the 50th iteration.
Limitations Or Advantages?
Only a single pouring video was needed for the robot to learn to imitate. However, as we saw, before that could be done, the TCN needed to be trained and that required a dataset of 60 minutes of video from multiple viewpoints both of a human and the robot. Viewing this as a limitation is a mistake, though. Human children spend dozens of hours pouring water into and out of cups in the bathtub before they fully master their eye-hand coordination and arm kinematics.
Certainly, one limitation with the current research is that separate TCNs are needed for each task. Go back and look at the list of attributes the TCN produced to see what we mean — they embody a lot of human knowledge about how hands pour liquids into cups. The attribute “is the liquid flowing” isn’t going to help much with the switch-flipping problem, for instance. The researchers do say that, in principle, a single TCN should be able to learn multiple tasks by using larger datasets, but they have yet to explore that avenue.
Interestingly, the researchers also tried training the TCN using a single viewpoint. Three frames were again used, two adjacent ones and one further away, but the results weren’t as good as with the use of multiple viewpoints. When we watch someone pour water into a cup, we have a complete 3D mental model of the event. Can you imagine what it would look like from above, behind, or to the side of the cup all at the same time? You can, and that helps you reason about where the water’s going.
Adding these extra inputs into the TCN gives it a chance to do the same. Perhaps researchers should be doing object recognition with multiple views taken at the same instant using multiple cameras.
In the end, pouring water into a cup isn’t a hard task for a robot with a complete machine vision setup. What’s interesting about this research is that the TCN, when fed the right input variables for the task, can learn abstractly enough to be useful for training based on a video of a human doing the same task. The ability to make mental models of the world and the way it works, abstracting away from ourselves and taking the viewpoints of others, is thought to be unique to primates. Leaving the cherry-picking of TCN’s output variables and the limited task aside, this is very impressive research. In any case, we’re one step closer to having workshop robot assistants that can work our CNC machines for us.













And Skynet will learn to kill humans by watching action films!
Skynet should watch terminator first
It was nice to meet all of you, goodbye..pew…pew
I wonder if the creators of Terminator knew that they would be cursing every single discussion about AI for the rest of eternity with the same joke
Leaving out the details about the liquid could be a huge problem as soon as you bring glass bottles of ketchup into the mix.
Another good picture by Joe Kim!
Young Frankenstein anyone?
+1!
Puttin’ on the Ritz!
No, not a good picture. It’s a great picture!
Does he do all the unattributed pictures?
He does artwork for almost all the original content articles, the long form ones like this one.
Psssst…
https://hackaday.com/category/curated/original-art/
I’m still waiting for a general-purpose robot that can learn to tie shoelaces. That’s my bar.
Well the Amish developed the mechanism that ties the square knot on hay bales!
There’s something tide-pod-esque about this. We all know how Terminator and Maximum Overdrive went down but for some reason decided that as a society we should recreate those fantasy worlds rather than work to avoid them.
Mankind has always been wary of new technologies. Doomsday works of fiction are merely a manifiestation of our fears of the unknown.