Pointers — you either love them, or you haven’t fully understood them yet. But before you storm off to the comment section now, pointers are indeed a polarizing subject and are both C’s biggest strength, and its major source of problems. With great power comes great responsibility. The internet and libraries are full of tutorials and books telling about pointers, and you can randomly pick pretty much any one of them and you’ll be good to go. However, while the basic principles of pointers are rather simple in theory, it can be challenging to fully wrap your head around their purpose and exploit their true potential.
So if you’ve always been a little fuzzy on pointers, read on for some real-world scenarios of where and how pointers are used. The first part starts with regular pointers, their basics and common pitfalls, and some general and microcontroller specific examples.
The Basics
Computer RAM, where your variable data gets stored, is a bit like the cubbyholes in a kindergarten, only each box has an address instead of a nametag. When you use variables in C, the compiler associates a particular location in memory (by address) with the variable name you give it. Pointers let you get in the middle of this association — and give you access to the memory address itself, rather than what’s stored there.
To make sure we’re on the same page, we start with a recap of pointer syntax, how to assign and use them, and how not to use them.
// regular int variable with initial value
int value = 0x1000;
// int pointer variable, pointing to the location of value
int *pointer = &value;
printf("value: 0x%x at address %p\n", value, &value);
printf("pointer: %p at address %p\n", pointer, &pointer);
printf("*pointer: 0x%x at address %p\n", *pointer, pointer);
For simplicity, we’ll assume some made-up addresses, and our first example will give us the following output:
value: 0x1000 at address 0x2468 pointer: 0x2468 at address 0x246c *pointer: 0x1000 at address 0x2468
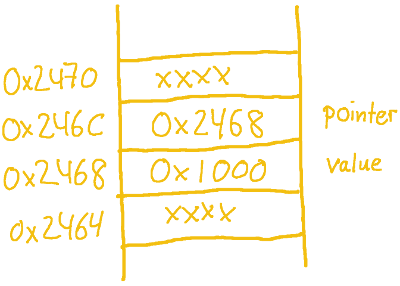
& gets the address of the variable that it’s prepended to, and * “dereferences” a pointer — you can think of it requesting the value at the address that the pointer points to. We can see that value resides at address 0x2468 and pointer at address 0x246c, with pointer‘s content being the address of value. That’s the whirlwind tour.
Storing numbers in memory isn’t very useful without knowing what type of number they are — how many bytes long the number is, whether it’s signed, and so on. Based on the values alone, we couldn’t tell which one would represent a memory address, an integer, or any other data, they are all just numbers and it depends how we use and reference them. This is why pointers themselves have their own types — the type of a pointer to the type data that is stored at the address. This is especially the case for pointer as a regular variable, and *pointer as a reference to another memory location. The difference becomes even more evident when we assign new values to either one of them.
// simple variable assignment value = 0x2000; // regular pointer dereference and assignment, same result as the statement before *pointer = 0x2000; // assigning to the pointer itself without dereferencing // technically okay, but compiler warns about assigning a regular integer to a pointer variable pointer = 0x2000; // explicit cast keeps the compiler happy, but.. pointer = (int *) 0x2000; // ..dereferencing is where things get tricky now *pointer = 0x2000;
On a system with a memory management unit, such as your average desktop computer, you will most certainly end up with a segmentation fault in the last line. What happened? In the third line, we wrote a new address (0x2000) into the pointer. The compiler complained because we wrote an integer into a variable that should be a pointer to an integer, and we should have listened.
Instead, we just got rid of the error warning by explicitly telling the compiler to store 0x2000 as a pointer to an integer in the fourth line. When we tried to write a value into the address associated with this pointer, it was out of bounds. Who knows what lives in memory location 0x2000? On a big computer, the MMU prevents you from writing to addresses outside your program’s territory, which could otherwise have fatal consequences. Naturally, this gets a lot more interesting on systems without such protection, like the vast majority of 8-bit microcontrollers. Assigning a hard-coded memory address to a pointer will be perfectly fine in that case, as long as you know what you are doing. On the other hand, if you have programmed for a microcontroller before, you have most likely used hard-coded pointer locations already without even noticing.
Microcontroller Registers
Let’s have a look at this simple piece of code that could be used to turn on a LED attached to an AVR ATmega328:
// file led.c #include <avr/io.h> DDRB = (1 << DDB1); // set up PB1 as output PORTB = (1 << PB1); // set output on PB1 high
DDRB and PORTB are two of the ATmega’s GPIO registers and defined as preprocessor macro by avr-gcc. If we take a look at the preprocessor output, we can see what’s behind those two macros:
$ avr-gcc -E -mmcu=atmega328 led.c ... (*(volatile uint8_t *)((0x04) + 0x20)) = (1 << 1); (*(volatile uint8_t *)((0x05) + 0x20)) = (1 << 1); $
Yes, your microcontroller registers are in fact pointers to a hard-coded memory address. If you take a look at the Register summary section in the ATmega’s data sheet, you will find those two registers are mapped indeed to addresses 0x24 and 0x25 respectively. And being pointers, we can pretty much treat them like any other pointer.
Passing Registers to Functions
To a pointer, it doesn’t matter what kind of memory it is pointing to. Whether it references a local variable on the stack, or a register mapped into RAM, in the end, it’s all just data behind an address. And by that logic, if we can do something like some_function(®ular_variable) in C, i.e. pass a pointer as parameter to a function, we should be able to do the same with registers.
We all love LEDs, and toggling LEDs is always a good example, but let’s assume that we cannot commit to one specific I/O pin that should control our LED, and we rather keep our options open to easily change that later on, maybe even during runtime.
// a simple struct that stores a GPIO port and pin number
struct gpio {
volatile uint8_t *port;
uint8_t pin;
};
// a variable for our LED GPIO pin
struct gpio led;
// assign the given port and pin to our led struct
void led_setup(volatile uint8_t *port, uint8_t pin) {
led.port = port;
led.pin = pin;
}
// turn the LED on by setting its GPIO pin to 1
void led_on(void) {
// PORTB |= (1 << PB1)
*led.port |= (1 << led.pin);
}
// turn the LED off by clearing its GPIO pin
void led_off(void) {
// PORTB &= ~(1 << PB1)
*led.port &= ~(1 << led.pin);
}
int main(void) {
DDRB = (1 << DDB1); // set PB1 as output
led_setup(&PORTB, PB1); // note the ampersand &
led_on();
}
Instead of accessing the GPIO register directly, we now store a reference to that register in a global variable, and later dereference that variable, which will let us access the actual register again. By the time led_on() is executed, the function doesn’t care anymore which I/O pin the LED is actually connected to. Admittedly, this particular example won’t quite justify the added complexity, we can achieve more or less the same with preprocessor macros. However, say we wanted to control multiple LEDs connected arbitrarily, or have a generic handler for polling multiple inputs, we could now store the references in an array and loop through it.
If we take another look at the preprocessor output, you may notice that there are now some redundant pointer operations going on, since &PORTB is translated to &(*(volatile uint8_t *)((0x05) + 0x20)), which is essentially the same as (volatile uint8_t *)((0x05) + 0x20). On the other hand, so is &*&*&*&(*(volatile uint8_t *)((0x05) + 0x20)), and they will all result in the exact same binary file. In other words, it makes no difference, but &PORTB seems a lot clearer than (volatile uint8_t *) 0x25.
You probably noticed the volatile keyword by now. If you want to read more about it, we dedicated a full article to it in the past.
Pointers Need a Home
The most important requirement to succeed with pointers and avoid segmentation faults is that they always have a large enough place inside memory that they can actually access. Again, on a system without MMU, any location in the memory is technically such a place, but it’s a lot stricter with memory protection, and we also need to avoid pointers that don’t point to anywhere specific.
// uninitialized pointer variable int *pointer; // dereferencing might access any arbitrary location in memory *pointer = 123;
Depending on some other factors, this may not necessarily cause a segmentation fault, but that doesn’t mean it’s without problems. To make your life easier, always ensure that a pointer has an actual location it is pointing to. However, once a pointer has a valid memory location associated to it, we can do pretty much anything we want with that space.
// have one type of struct
struct something foo = { ... };
// make a different type of struct believe the first one is one of them
struct something_else bar = *((struct something_else *) &foo);
This is a perfectly valid cast, and as long as accessing members of bar won’t go beyond the size of foo, we will be on the safe side. Whether such a type cast makes sense or not is of course a different story, and depends on the context, but pointers give us the freedom to cast as we please. Another way to use this freedom is assembling sequential data to one common buffer.
Assembling Data with Pointers
Say we need both of those structs concatenated into a single buffer. We could use a char[] buffer and memcpy() both structs into it, but then we use twice the memory. Instead, we can simply make that buffer believe that it’s actually two types of structs:
char buf[BIG_ENOUG_SIZE]; struct something *foo; struct something_else *bar; // point foo to the beginning of buf foo = (struct something *) buf; // point bar to the location after foo inside buf bar = (struct something_else *) (buf + sizeof(struct something));
 Once again, pointers are simply memory addresses. The compiler will guide us to avoid the most obvious mistakes, but in the end, it’s up to us how we interpret what’s located at those addresses. And in case we don’t want to interpret that data at all, we can make use of C’s generic pointer type
Once again, pointers are simply memory addresses. The compiler will guide us to avoid the most obvious mistakes, but in the end, it’s up to us how we interpret what’s located at those addresses. And in case we don’t want to interpret that data at all, we can make use of C’s generic pointer type void *.
The Void Pointer
In some cases, we are only interested in the memory address itself, and we might just want to pass that address around, for example to a function that doesn’t care how the data itself is arranged. If we use the void pointer, we can simply assign to and from it without any explicit type cast necessary, which can help us keep the code a bit cleaner.
// actual storage for the struct struct something s; // assign it to void pointer, no cast needed here void *foo = &s; // assign it back to a specific pointer, no cast needed here either struct something *bar = foo;
void pointers are commonly found in dynamic memory allocation functions, for example as return type for malloc() and as parameter type for free(), and any other generic memory accessing functions such as memcpy() or fwrite(). Keep in mind though, since it removes details of the data itself, dereferencing a void pointer will result in a compiler error, unless we first cast to an explicit pointer type.
// regular struct member assignment s.some_member = value; // dereferencing void pointer, will result in compiler error foo->some_member = value; // cast before dereferencing void pointer, this is okay ((struct something *) foo)->some_member = value; // dereferencing explicit pointer type, no problems here bar->some_member = value;
Note the arrow operator -> when dereferencing a struct (or union) to access its members. This is a shortcut C offers and is identical to (*variable).member. Beware though that (*variable).member is not the same as *variable.member. The first, enforced by the parentheses, dereferences the pointer before accessing member, while the second dereferences a pointer-type member inside the struct. This is naturally an easy source for errors, which the arrow operator helps us to prevent.
To Be Continued
This concludes our first part, and we merely scratched the surface of possibilities we have with pointers, which just shows how complex the seemingly simple concept of “it’s just a memory address” can really be. Next time, we continue with pointer arithmetic and some more complex pointer arrangements.














All those risks are reasons why you don’t use raw pointers in C++, except inside a class whose responsibility is to manage them.
Each risk C++ removes, it replaces with an army of more confusing ones.
it is so true :) not to mention if you can not code then don’t do it, problem solved…
+1
1++
but then how would i unleash awesome embedded stuff and emulate and or make retro style computers?
C++ does not remove risks, it just adds more ways to screw up. It’s not like you can disable raw pointers. Hell, it’s not even possible to ensure object construction is done only by std::make_shared, as it requires a public constructor and thus cannot be hidden behind a factory.
(Note: I do love C++, but it’s not something for everyone, most people are better of with easier languages)
Most people are better of with easier, more rational languages, such as APL.
APL — you cracked me up :) It’s always great to find that language mentioned. It was my first programming experience, in 1974, and it hooked me.
lol, you said that correctly
C++ gives good programmers tools to protect them from their own screwups. It’s very helpful if you don’t constantly repeat yourself, and if you use higher-level language subsets for higher-level constructs.
C++ doesn’t take away any of the tools that bad programmers use in C to shoot themselves in the foot, and gives them new ones that can do a lot of damage.
Since in ASM the programmer can manipulate pointer assignments, so can we in C and C++.
We can even apply complex arithmetic methods on the pointers.
Yet can someone explain why when I try to divide a NULL pointer by ZERO (0) I get kicked by Chuck Norris?
Because you cant divide ANYTHING with ZERO.
Pointer or whatever.
If your divide by argument is zero it is impossible.
Or did I just fall into a trap? ;)
2008 called, they want their joke back.
Because only chuck norris can divide by zero
Great Caesar’s ghost! Dividing pointers? I thought Chuck Norris would be dispatched even if you divided a pointer by other-than-zero
I do quite like pointers, but then again, that may simply be because I’ve used them for decades. I quickly get frustrated with other languages if they don’t support using pointers and then switch to one that does.
Hear hear! Nothing risky about pointers as long as you know what you are doing. I can still remember my excitement when I first really “got” them.
Funny, as most other languages follow “everything is a pointer” except for primitives. And generally, if you are using pointers to primitives, you are doing something wrong anyhow.
Embodied in the KDE vs Gnome debate. Your control vs someone elses control.
I doubt that, as KDE and Gnome both give control only to the user.
It’s an old debate. The freedom KDE gave to “having it your way” vs Gnome “we know what’s best for you” by the developers.
There is an interesting macro used in teh Linux kernel “container_of” where one can get the pointer to a struct by pointing to one of its members – handy when you need to change something else in a struct when its passed to a function.
“By passing pointer to the member of the structure in ptr and the structure type as argument type and the name of the member of which ptr is the pointer to we can retrieve the pointer to the parent structure”
Sounds like a great way to make a mess of things? Should be useful though.
well it is Linux kernel code… :P
The macro contains a compile time check that the pointer you are passing in is for the type of the member.
You usually use it if you register an instance of something that has callbacks in your code, but the instance is only part of the data structure that makes up your device.
In the EDK2, there is a concept of something called a containment record. It’s the same idea. I’m still new to Linux kernel coding, but the EDK2 requires a structure to be obtained via the containment record macro to have a unique signature as its first field. If the signature doesn’t match, it throws an error and asserts in debug mode. Drivers would often have private data to do along with an interface, and in some cases, a driver could produce multiple interfaces of the same type. So the macro was used to take what is essentially a This pointer for the interface and get to the private data for that particular instance.
If you learn programming on a 6502, in assembler, pointers are the most natural thing to use.
For me it was the other way around. Working with pointers in C made it easier for me to make some sense of assembly. memory adresses, offsets, registers, segments… suddenly it all fell into place
Pointers in 6502 assembly are easy.
In C you never know what the compiler makes off your code.
I respectfully disagree. The only 6502 instruction that supports a straightforward indirection (like you get with a C pointer) is JMP (ptr). For data manipulation, you must choose between base,x base,y (zp,x) and (zp),y addressing modes. The latter is the only one that remotely resembles a C pointer and you must keep the pointer in zero page and have to use the Y register whether you need it or not. Practically, this means you can only have 128 pointers and must bump the Y register off to somewhere else while you use it for this mode. To add insult to injury, the processor can’t add and subtract its own pointers in a single instruction, so any “pointer math” you try to do results in 6+ instructions.
Because of this madness, most programmers use the base,x and base,y forms whenever your array has less than 256 entries in it. Works great for single bytes, but for multi-byte types you wind up using parallel arrays, which are a whole new level of nastiness.
The C * and & constructs are quite simple to understand, though are easily misused as reading pretty much *any* CVE report will tell you :-)
You only need cat to see what the compiler made of your code, or any sort of editor or file display utility that can display ASCII text.
…started programming in assembly on the I4040, then the 8080…8085, F8, Z80, 6800, 68000, and finally, the I8088 and 80×86. Never encountered a construct known as a “pointer” in the documentation of any of the assembly languages of these machines. Perhaps this accounts for the popularity of the 6502, which assembly language I did not learn?
Would appreciate hard examples of the language construct, “pointer”, in some oft-used assembly language.
Many thanks.
Stack pointer, Zero page pointer.
Various indirect addressing modes LD A,(IX) LD A,(HL) LD A, (IX + nnnn), PUSH, POP
I asked for a language construct, not assembly-language instructions, or registers which must be initialized by assembly-language instructions.
what were you using these processors in?
Everything.
I have only used a little Z80 assembly.
I can’t think of a reason you would need a pointer when using assembly there are no variables, functions, or classes so nothing you could use a pointer to point to. You could build them yourself in that case it would be a program construct and still not a language one.
A pointer is a variable that stores an address. Dunno if that’s an italic language construct or not.
For me, it was x86 assembly. Specifically were the the uses of the [] and the instruction LEA.
Working with debuggers helped too.
You didn’t use a pointer language construct in x86 assembly language. There is no such thing.
Try again.
And the use, however it is used, of an assembly language instruction as a pointer does not imbue that assembly language with a pointer construct. It only means that the assembly language programmer truly understands programming.
I have several complete sets of MASM manuals for sale, if you would like to learn ‘x86 assembly language.
Note the code:
char buf[BIG_ENOUG_SIZE];
struct something *foo;
struct something_else *bar;
// point foo to the beginning of buf
foo = (struct something *) buf;
// point bar to the location after foo inside buf
bar = (struct something_else *) (buf + sizeof(struct something));
Might not work on all platforms. For example:
struct something { short number; }
struct something_else { long number; }
This causes the first 2 bytes to be number. And the sizeof(struct something) to be 2 bytes.This causes the something_else structure to be 2 bytes into the buffer. However, because it’s a long (4 bytes) you are accessing it unaligned, the address is not aligned to the size of the long. Which is valid in some platforms, invalid on others, or a huge performance problem on some.
These pointer tricks are a curse for portability, so in general, don’t.
That’s a problem if you use “ints” and “longs”, which are known to have different sizes depending on the underlying target architecture. You can also used fixed size types: https://en.wikipedia.org/wiki/C_data_types#stdint.h
That way you’ll only be more sure the 32b variable really gets misaligned. How does fixed size types help (i.e. avoid) the problem with unaligned access?
Interestingly enough, on architectures which don’t support misaligned access, you would most likely run into a different issue in the above code which would run, but not work. On architectures like this, compilers end up padding structs so that each byte is on a % 1 byte boundary, each 2 byte variable is on a % 2 boundary, etc…. Say we had a struct which looked like this:
struct something
{
uint8_t foo;
uint16_t bar;
uint8_t nothing;
};
The sizeof of struct something would most likely end up being 6 instead of the expected 4. This is because the compiler will insert padding into your struct and it would actually look something like: (The location of padding (before/after) is undefined)
struct something
{
uint8_t foo;
uint8_t padding_0;
uint16_t bar;
uint8_t nothing;
uint8_t padding_1;
};
The compilers insert padding like this into structs all the time in an effort to make accesses to memory as efficient as possible on the architecture you are compiling to. If you ever want to take a byte stream and overlay it on incoming data you can either pay attention and make structs in a way that respects padding. If we wrote the above struct like this, the size would be the expected 4. You then have to make sure all subsequent structs are aligned depending on architectures ad above comment said.
struct something
{
uint32_t foo : 8;
uint32_t bar: 16;
uint32_t nothing: 8;
};
This would also be a size of 4, but it would not work for our reason:
struct something
{
uint8_t foo;
uint8_t nothing;
uint16_t bar;
};
On most compilers you can specify if you want structs packed, which tells it to not insert any padding. This might lower performance on architectures which don’t support misaligned memory access since the compiler might fetch the whole word, mask out the bits you are not interested in. For writes, it would have to read, mask, or, and then write.
Actually, almost all C compilers for architectures that don’t support misaligned access will pad structures so that each field is aligned on its natural boundary so that it can be accessed. You have to use an __attribute__ or #pragma to cause it to pack the data on byte boundaries, so your first structure will add a pad byte between “foo” and “bar” so that “bar” is aligned on a 16 bit (2 byte) boundary; sizeof something would evaluate to either 5 or 6; most often 6, so that you can have an array of “something” structs:
struct something somehow[5];
printf(“somehow the size is %u when the size of its elements is %u\n”, sizeof somehow, sizeof somehow[0]);
Note that “sizeof” is an operator that is evaluated at compile time, not a function; you don’t need the extra parameters if the operand it is applied to is not a type specifier of some sort. You can’t say “sizeof int” or “sizeof struct something”, those are not valid expressions without wrapping the type specifier in parens (like a typecast) but “sizeof somehow” is a valid expression without the extra parens.
Time for some wild jokes without reference?
Might be hard on the uninitiated..
Lets jump over to pointerfun with binky:
https://youtu.be/i49_SNt4yfk
C has pointers for the simple reason that the underlying hardware it was designed to map to had “pointers” in the form of index registers. Then Harvard architecture came along, where data and instructions are on separate buses and accessed via different instructions, and C basically “broke” and needed hacky, non-standard extensions to get around it. As as others have pointed out, C++ is a poor attempt to circumvent many of the inherent problems of C, but it just introduces a whole bunch of others by trying to remain backward compatible with what is basically a flawed, obsolete language to begin with.
Baremetallist can learn Forth, without blowing off their feet. ;-)
Can you define “C basically ‘broke'”?
Whut? C works fine on Harvard architectures, unless you’re trying to do self-modifying code.
You are correct that C was originally designed to use operations that mapped closely to the original target, but the PDP-11 doesn’t have “index registers”; it has general purpose registers and a bunch of addressing modes, one of which is an indexed mode. It is true that the indexed addressing modes lead to the array/pointer equivalence (not covered by the post). In addition, auto increment and auto decrement indirect addressing is why “*ptr++” and “*–ptr” are in the language. With a few exceptions, every operand of a PDP-11 instruction is some combination of a register and an addressing mode — “mov #6, r0” (move absolute (constant) 6 to register 0) is actually “mov (r7)+, r0; .word 6″ (move the word pointed to by the pc into register 0 then increment the pc by 2; 16 bit data word with value 6).
Note: this is DEC assembler syntax, so the first operand is source, second is destination; and ‘r7’ is the program counter. The PDP-11 increments the PC after reading the instruction word but before resolving the operands. The source operand is evaluated first, along with all its side effects, then the destination operand is evaluated along with its side effects, so the PC points to the 6 and is then moved past it so that once the instruction is done, the PC points to the instruction following the data word containing 6. My favorite infinite loop for the PDP-11 was “tst -(pc)”.
C was not my first language with pointers, but the PDP-11 was the first assembly language I learned. Over 40 years later, it’s still my favorite.
C++ Programming is as easy as storing a square pointer into a round float:
float f;
f (int) = sqr( *pointer);
C programming on the other hand…
by
RE-AL Programmerz comix
Pointers are quite possibly the most useful feature of C, especially when they point to opaque structs, or functions.
C++ hides pointers to functions a little by calling them virtual, and tightens type-checking. It has useful features that can save a lot of time but also tempt programmers to make their code write-only.
C# pretends that pointers don’t exist, and then invents numerous other confusing language constructs to work around their absence.
===Jac
“His [Edsger W. Dijkstra’s] great strength is that he is uncompromising. It would make him physically ill to think of programming in C++.”–Donald Knuth
To Hackaday:
In the follow up, spend some time on the many way’s you can screw up pointers use such as:
int * asdf( void) {
int aaa, *p = &aaa;
return p;
}
super pre-rookie mistake. I haven’t even seen a 12 year old rookie make this mistake.
I agree. But even pros have bad days. I have been the cause of this once:
void bigfunc()
{
EnterCritical()
…..
If( x == y)
return;
…..
ExitCritical()
}
Lesson learned. Always exit your critical sections before returning..
Some of the other comments have bashed C++, but the “resource acquisition is initialization” (RAII) idiom that C++ supports works well to prevent mistakes like returning before exiting a critical section.
“Always exit your critical sections before returning…”
Except when you have a reason not to. Doesn’t happen often, and when you do it, make sure the comments in the code explain why it’s being done, and where the critical section is exited (if at all).
In general, critical sections should be as small as possible. If you have to implement asynchronous “signal” delivery in a bare-metal multi-threading executive, not only do you not always exit the critical section before the return, you mess with the stack so that when you return, the application defined signal handler gets control, and when it returns, code that exits the critical section gets control. This really happens, and there is no way around it on some architectures. It’s ugly, almost impossible to debug if it’s not done right, and you want to burn your keyboard after writing the code, but requirements are what they are, and you (or at least I) get paid to satisfy the requirements.
I have seen (not written!) production code that returned a pointer to a stack allocated variable.
Almost always when I find such things they were written by someone who is no longer with the company.
It happened to work, because the calling code finished using the value before it got smashed.
I fixed it anyway.
I have also seen this (in one form or another) in a ***LOT*** of production code throughout the years. It is surprising how long this form of bug exists in production code ***WITHOUT*** ill effect.
What is a nice “working” method of pointing to a returned value from a called assembly function routine within C ? (Z80 platform – the returning value is sitting in HL in the asm function)
Seriously I have googled for the past few days and can not find a suitable working answer. From my google searching results, it seriously appears as though either no one has ever done this before or the internet has been reformatted.
Haven’t done this on a Z80, but on some other MCU platforms. Are you falling into the pointer to a local variable trap? You have to malloc it, modify a passed pointer, or return the actual value.
You need to lookup the calling convention for the Z80/compiler you are using. For example on the MSP430 you store a returned int value in R12. One thing that helped me is to create several simple function calls in c then step through the generated assembly.
It’s an implementation detail of the compiler, so you will need to consult the documentation. For BDS C the callee is expected to write the return value into HL, so if that’s what you happen to be using, just access it like you would the return value of a C function. (http://altairclone.com/downloads/manuals/BDS%20C%20Compiler.pdf page 34)
If you don’t have documentation on your compiler, try writing a dummy function in C that returns 42, compile it, and then disassemble the result. You might also need to write a wrapper function in assembly to convert the output of what you’re calling to what your compiler expects.
I’m not entirely sure what you’re asking.
If the function returns a pointer, you can simply dereference the return value. You just have to know what the ABI uses as the returned value register.
For example:
struct foo { int first; int last; };
struct foo* foomatic(struct foo *victim, int first, int last)
{
if (victim != NULL)
{
victim->first = first;
victim->last = last;
}
return victim;
}
main(int argc, char** argv)
{
struct foo myFoo = {0, 0};
…
printf(“first was %d\n”, (foomatic(&myFoo, argc, 10))->first);
…
}
On some architectures with general purpose registers, the return value is in r0, others it’s other registers — in most cases, it’s just a convention not enforced by the hardware, but the C compiler will use the ABI it was built for. One way to see is to use the “-S” or “-s” option on a simple C function and see what the generated assembly looks like. You may want to disable optimization when doing this, or the result may be a bit confusing. x86 has a bunch of special purpose registers, and I don’t recall the calling conventions off the top of my head; been programming PPC and ARM almost exclusively for the past few years.
“What is a nice “working” method of pointing to a returned value from a called assembly function routine within C ? (Z80 platform – the returning value is sitting in HL in the asm function)”…
if I understand you correctly HL contains the result and you want to point to HL?
something like:
short int tmp, *ptr;
tmp = asm_func_foo();
ptr = &tmp;
ospr3y: Sweet! thats it. Apologies for not being clearer, but cheers heaps for working out what I attempted to explain and what it is I’m trying to do.
This is gonna work.
Note that there is no portable way to point to a value in a CPU register. C pointers are memory addresses, so unless the register is memory mapped, you cannot point to it.
Any pointer to an automatic variable (that is, a non-static variable with block scope) is invalid when the block is not active. You can call a function with a pointer to a local scope automatic variable as an argument, but a function can’t safely return a pointer to an automatic variable that is declared within the function body. On the other hand, a function can return a pointer to a static or global variable. Whether it’s advisable to do so depends on the circumstances, since it creates aliases that can lead to race conditions and/or other undesired and hard to debug problems.
When I need to return a pointer to the location a result is stored in from a function and there is not a reason that the result should be common (and changing) for all of the aliases created by calling the function (there are valid reasons for doing this sometimes), I pass the address of the storage for the result value into the function as an argument and return that pointer on successful; this avoids unwanted side-effects.
If the result is a structure, a function might allocate an instance of the structure using “malloc()”, “calloc()”, or in some cases “realloc()”, and return the address of the allocated memory, but that requires that the program call “free()” at some point when the instance is no longer needed.
So, in general, the following is not safe or portable:
int* unsafe1(int a, int b)
{
int result;
if (b != 0)
{
result = (a + (b / 2)) / b;
}
else
{
result = -1;
}
return &result;
}
Same with:
int* unsafe2(int a, int b)
{
if (a > b)
{
return &a;
}
return &b;
}
The scary thing is that in some circumstances you’ll get the result you want because the stack location that the function returned a pointer to has not yet been overwritten, but you cannot rely on that, or at least should never rely on that.
“Pointers — you either love them, or you haven’t fully understood them yet.” OR you use a language that avoids the pitfalls of user-managed memory but still includes references :-P
Why people aren’t programming uControllers in D? Just hasn’t caught on, or something else? :D D: :D” ¯\_(D)_/¯
There will always be a language like C. For efficiency there is no substitute for working directly with the actual hardware available with minimal abstraction. Some can do this properly, most can’t. C will never die.
Processor power you say.. But processor power uses actual power. The future will weigh more heavily efficient processing for the sake of the children.
Writing an article encouraging the use of pointers is like putting an article in a health magazine entitled “Air and why you should breathe it”. Any meaningful project will have to use pointers, probably a lot. Most languages support them, though some might call it a “reference” and restrict what you can do with it.
And yes, Java is included in that list. Why do you think they call it a NullPointerException?
For an interesting take on pointers, look at the PL/I idea of “based” variables. Basically, you define a second variable that’s the address of the first. To modify the address, set the second variable. To access the contents, use the first. No reference/dereference operators necessary.
When you need performance, C is the way to go. Linux kernel is still written in C. C is still a lot more readable then Assembly Language but I admit that even well written C code that deals with hardware is painful to read. For everything else, High Level languages like Python can get the job done. Frankly, with the way people write code these days, performance does not matter anymore. You would rather have the language optimize the performance (like Dictionary/Hash) than having unqualified programmers coming up with O(N^3) algorithm to solve O(N) problems.
“than having unqualified programmers coming up with O(N^3) algorithm to solve O(N) problems.”
Me with C:
Lets make this efficient and fast!
Me with python:
Wololo, lets just get it done ASAP! Om(nom^nom)
Leave the optimization to the compiler; if you don’t understand how compilers work leave the coding to real programmers, yeah! And you who overusing pointers read a book about databases so you don’t fuck up the the structure with your bad design.
Define “overusing pointers”.
Also, databases and data structures are two very different things. You can use data structures in data bases, but they’re somewhat different structures than in-memory structures you might create in C.
so…. pointers in MISRA C anyone?
I’ve paged through what MISRA thinks is not advisable and it looks like they don’t like pointers.
I think you’re wrong; I have been using a compiler that enforces MISRA C rules for about 8 years now, and I use pointers quite a lot. I don’t get complaints from the compiler, Understand, splint, pc-lint, or Coverity (if I do, I change the code, since I’m writing safety and security critical code that has to have nearly 100% coverage — check out DO-178 some time). Most of what I write is “platform” or “foundation” code, including device drivers, and in some cases, runtime executives; I could not do my job without using pointers.
People who don’t understand pointers should not use them if they can help it, but I don’t recommend embedded programming as a career for such people. C must be a very scary language for them.
I’ve been using pointers since the 1970s. I understand them. I like them. Data pointers, function pointers, pointers to pointers, void pointers, volatile pointers to const objects, const pointers to volatile objects, volatile pointers to volatile objects, pointer / array equivalence, pointers to unions for polymorphism in C. I’m like Bubba in the movie Forest Gump if you replace the shrimp with pointers. And the funny thing is that I have had very few software bugs that are related to stray or NULL pointers. I use pointers all the time, but I am careful, and I write extensive comments any time I do something that less experienced programmers might not be familiar with because the code must be maintainable by people other than me, and even I might forget what I had done 6 years down the line.
thanks, any literature worth reading about MISRA?
The MISRA standards are copyright and you have to buy a copy of the PDF, which isn’t really useful for the student or simply curious. My employer has purchased the docs, so I have access to them at work.
You can start at Wilipedia: https://en.wikipedia.org/wiki/MISRA_C
There’s a MISRA FAQ: https://www.misra.org.uk/MISRACFAQ/tabid/168/Default.aspx
BTW: What MISRA really doesn’t like is deep indirection and dynamic memory allocation.
thanks
I find the C Gibberish translator very helpful….
https://cdecl.org/
I wish people stopped attaching the * to the variable name instead of the type.
That alone caused so much confusion when I learned C back in the day because it looks just like the dereference operator that way.
so in your view:
int* x, y;
is the same as:
int *x, *y;
sorry can’t agree.
I agree with Martin in that I wish that more people cuddled the “*” with the type, not the variable name, because it the variable is not “*x”, the variable has type “int*”.
That said, I also wish that people wouldn’t have multiple pointer declarations in one statement, because it is easy to mess up and then miss the error.
I do not think “int* x, y;” declares two pointers. I know that it’s correct syntax (according to the language definition), but I personally never declare things that way.
Of course, I also don’t use parenthesis around the operand of the “sizeof” operator unless the operand is a type specifier, not an object name, and some people get mad at me for that.
That’s why you shouldn’t declare multiple pointer variables like that.
It’s a messed up syntax easily leading to bugs. They tried to improve it a bit in D by disallowing different types in one statement. There variant 1 works as expected.
That’s very interesting – thanks for sharing.
so does D allow:
int x, xarr[20];
If you THINK that any assembly language supports “pointers”, you don’t understand assembly language.
(Just a hint to get you started: assembly language is nothing more than a one-for one mnemonic replacement for machine-level binary-coded instructions ; one may create any imagined–or desired–construct in assembly language).
No assembly language supports the ‘pointer’ construct; you CREATE ‘pointers’ by using assembly language instructions.
“Just a hint to get you started: assembly language is nothing more than a one-for one mnemonic replacement for machine-level binary-coded instructions ; one may create any imagined–or desired–construct in assembly language”…
NO!!!!!!!!!!!!!
Some (many?) assembly language statements actually generate ***MULTIPLE*** machine-level binary-coded instructions. Look at a really bad case like the transputer. Loading a single 32 bit integer constant onto the stack could take 8 machine-level binary-coded instructions.
“No assembly language supports the ‘pointer’ construct; you CREATE ‘pointers’ by using assembly language instructions.”…
This is just plain rubbish. The 8080 used / uses HL, BC, DE as pointers.
I’m not going to dignify the nonsense of someone whose only objective is to attempt to prove how much they know, when it’s obvious that’s the only purpose of the post; and that any knowledge of the subject is non-existent; I’ll simply point out a small part of the respondent’s ownrubbish, to wit:
To the statement that “No assembly language supports the ‘pointer’ construct”, our assembly language expert responds with,
“This is just plain rubbish. The 8080 used / uses HL, BC, DE as pointers.”
Sounds pretty impressive, huh? Now he’s got your attention, huh?
…Unless and until you know that the HL, BC, and DE registers (oh, they’re always referred to as BC, DE, and HL by anyone knowledgeable about the 80x8x series, corresponding to Intel’s own documentation) are general-purpose registers, to be used by the programmer any way he or she wishes. As further evidence of their general-purpose nature, the 16-bit BC, DE, and HL general-purpose registers are formed from six 8-bit general-purpose registers: B, C, D, E, H, and L, which can be used for any purpose whatsoever.
The expert’s mistake is in scanning literature on the 8080, and picking up on the statements that BC, DE, and HL can be used as data pointers (but only after being appropriately initialized)…and then using that new-found knowledge to state that the 8080’s assembly language supports a pointer construct. His biggest mistake is in verbalizing his errors of logic. But to someone who knows no different, it sounds impressive.
[Oh, ospr3y: I’ve got something you really should consider obtaining: a complete set of MASM documentation, six books, and including CD. For your information, MASM is the ‘Microsoft Assembler’ for Intel’s 80x- series of microprocessors. And, uh, no…no ‘pointer’ construct anywhere in sight. You’re welcome. And we’re all waiting…]
jawnhenry you are a dim wit that tries to elevate his standing by playing with words. A pointer is what a pointer does. Just because there is no word for synchrotron in Inuit does not mean that there is no such thing as a synchrotron.
in 8080
MOV A, M
moves what “HL points to” to register A
it is equivalent to Z80
LD A,(HL)
I love your statement: “BC, DE, and HL can be used as data pointers (but only after being appropriately initialized)”…
So please enlighten us as to how this is any different to C or C++ pointers? I guess you have some magical way of using C / C++ pointers that are not initialised.
And for you information I haven’t just “scanned some 8080 literature” I am a paid professional of some standing that wrote firmware (in assembly) for both the 8080 and the Z80 in the past.
We’re all impressed; it only took you twenty-four hours to gather the information you think was needed for a rapier-wit response.
“…A pointer is what a pointer does…”
As in the line from the movie, ‘Forrest Gump”: “…stupid is as stupid does…”?
“…Just because there is no word for synchrotron in Inuit does not mean that there is no such thing as a synchrotron…”
And your point is…?
“…I love your statement: “BC, DE, and HL can be used as data pointers (but only after being appropriately initialized)”…
And your point is…?
“…MOV A, M
moves what “HL points to” to register A
it is equivalent to Z80
LD A,(HL)…”
And your point is…?
“…And for you information I haven’t just “scanned some 8080 literature” I am a paid professional of some standing that wrote firmware (in assembly) for both the 8080 and the Z80 in the past.” (You wrote firmware?…”That” wrote firmware…?” Never mind. It’s not worth it.)
1) Even more damning; someone who is conversant in 8080 and Z80 assembly language would know, and recite automatically, just like a tape recorder, the register order, BC, DE, HL. Why not you, with all the experience?
2) Someone is due a refund.
I would like you to know that you have seriously offended me; firstly, because the proper spelling of the appellation is “dimwit”; NOT “dim wit”.; and secondly, because you have characterized me thusly: “…you are a dim wit [sic] that tries to elevate his standing…”. What a scurrilous, and completely erroneous charge. I will have you know, sir, that I am “..a dim wit [sic] WHO tries to elevate his standing…”
Though considering the source, anything close is high compliment. Thank you.
If this were a court of law, your lawyer would advise against talking.
Try to scan faster next time.
You really ought to consider that MASM documentation, strictly to complement what you already know , mind you.
jawnhenry… still playing with words and still nothing to support your assertion.
“If you THINK that any assembly language supports “pointers”, you don’t understand assembly language…”
While it’s true that most assembly languages, at their most elementary, do not support pointer syntax, the statement that “No assembly language supports the ‘pointer’ construct” isn’t quite true. Depending on the architecture, it may support indirect addressing modes that act as pointers. Some macro-assemblers provide a pointer abstraction that selects the right addressing mode.
The PDP-10 architecture has a dereference bit in each address word, allowing multiple levels of indirection, so if you use an indirect addressing mode on a memory location that has the address of a word with the dereference (or “indirect”) bit set, the CPU will treat the value of the referenced location as an indirect pointer (the address of the actual data) unless its indirect bit is set, in which case it’s the address of the address, and so on. They had to add special checks in the hardware to prevent infinite indirect loops. The PDP-10 (and PDP-20) assembler quite definitely supports the pointer construct directly.
Assembly language is not always a 1:1 mnemonic replacement for the machine code, though it often is and this is even more true with a lot of older tools. Extended op-codes in some assemblers will expand to be multiple machine instructions on some models and single instructions on others. Sometimes multiple assembler opcodes produce the same machine instruction opcode with different addressing modes and or operands. ARM and PPC both have such extended op-codes. The current official ARM assembly language has a common set of opcodes that will produce Thumb, Thumb2, or ARM 32 bit machine code depending on the target processor family.
A pointer register (or register pair) is not quite the same as a C language pointer, though it can be used in implementing them. Try to take the address of a register or register pair; some CPUs do map their registers in the data address space of the CPU, but many architectures don’t.
Just because the architectures and assembly languages you know have the properties you claim, you cannot generalize those properties to all assemblers.
“A pointer register (or register pair) is not quite the same as a C language pointer, though it can be used in implementing them. Try to take the address of a register or register pair”…
I understand what you are saying here but consider also that you cannot take the address of any variable held in a register (except for some architectures as you have already mentioned – the Ti 9900 comes to my mind). In general, because most programs use a great many variables and pointers they are constantly being copied between the abundant RAM and scarce registers. Taking the address of a pointer (or any other variable) while it is in RAM makes it possible to “take the address”. Why should this be any different in assembly source?
You cannot take the address of a register in general; the 9900’s register file and frame pointer is an architectural feature that I doubt many C compilers take advantage of. Modern (and most older) C compilers will move where the value of a local scope non-static variable is stored when its address is taken, and put back in a register when the the address of the variable is no longer needed. Most compilers will allocate a location on the stack for the variable. The value of the variable may be in a register (or move around from register to register) up to the point the flow where its address is taken. From that point on, the value of the local variable is updated in the memory location at every control point where the address may be passed to another function or used locally. After a function call or local manipulation, the compiler may copy the value from memory back into a register (usually when it is next used).
I worked on a commercial C language compiler in the late 1980s (pre-ANSI/ISO standard ratification), and was responsible for developing the part that optimized the generated code for a particular target processor family (M68000) from the (almost) architecture agnostic internal RTL (register transfer logic) representation of a function generated by the earlier stages of compilation (lexical analysis, syntax analysis, flow analysis, etc.). Back when I was doing that, we were very resource constrained, so our code generation and optimization was very local. These days, compilers are much more advanced and generate machine code where values for local variables moves around constantly between registers and memory. Some variables may not have any value at times (you can see this in the debugger when single-stepping).
This has gotten far away from the OP subject, however. I should stop now.
Us old guys that started with the Data General Nova series and PDP8 “mini” computers used pointers in “machine language” toggled in from the front panel to write paper tape boot loaders to start our machines. This allow us to point to a specific memory location read it’s value and start the peripheral tape or other device to load and run a program. Often at the end of the program you would change the pointer to preserve data to be carried over to the next program. These machines had a fixed memory location 0 that would point to the jump instruction for program execution. In the beginning of “C” creation on the PDP11 K&R carried over the use of pointers to us machine language/ assembler programmers who were familiar with the concept of pointers. “C” originally had way fewer compiler syntax checks so programs were really wild and crazy!!! Progression was front panel toggle switches/machine language -> assembler –> “C” each more progressive and quicker to write programs compared to the FORTRAN and COBOL mainframe machines, which required a compiler change to add a new piece of hardware.
Other of us “old guys”, who started on PDP-11s (also used PDP-8s, but it’s not the machine I first learned to program on) had it easy, compared to the PDP-8 or DG. We had general purpose registers and deferred (indirect) addressing modes that directly implemented pointers. The switches on the front panel were for address, data, deposit, halt/run, etc. I no longer remember the octal sequences (the PDP-11 was a 16 bit machine, but still used octal notation for a lot of things, and the address and data switches on the front panel were in groups of 3 (1 octal digit)) for booting off the 9-track tape, the DECtape, or one of the hard drives, but at one time I knew those all by heart.
On the other hand, the system my college ran on (RSTS-E on a PDP-11/40 w/112KW of core memory) had FORTRAN-IV and assembly as the only compiled languages. COBOL and BASIC-Plus were interpreted, as was the ALGOL and LISP implementations we had gotten from the DECUS library.
FORTRAN-IV has no pointers. I wrote a library in PDP-11 Macro Assembler that provided pointers and allowed creation of data structures with embedded pointers — linked lists, hash tables, dynamic allocation, etc. — for the data structures course I was taking. FORTRAN-IV still had no pointers or recursion, and the access function calls looked weird, but it all worked well enough to bootstrap a recursive descent PASCAL compiler for my Compiler Construction project.
Your code at the top displays several HTML tags (&) which seriously confuses the example.
Yikes, yes indeed. Thanks for pointing it out (months ago already..)
Should be fixed now.