
If you write software, chances are you’ve come across Continuous Integration, or CI. You might never have heard of it – but you wonder what all the ticks, badges and mysterious status icons are on open-source repositories you find online. You might hear friends waxing lyrical about the merits of CI, or grumbling about how their pipeline has broken again.
Want to know what all the fuss is about? This article will explain the basic concepts of CI, but will focus on an example, since that’s the best way to understand it. Let’s dive in.
What is CI anyway?
The precise definition of Continuous Integration refers to the practice of software developers frequently checking in their code, usually multiple times a day in a commercial setting, to a central repository. When the code is checked in, automated tests and builds are run, to verify the small changes which have been made. This is in preference to working on a ginormous slab of code for a week, checking it in, and finding out it fails a large number of tests, and breaks other people’s code.
Whilst this is a valid definition, colloquially CI has become synonymous with the automation part of this process; when people refer to CI, they are often referring to the tests, builds, and code coverage reports which run automatically on check-in.
Additionally, CI is often lumped together with its sister, Continuous Deployment (CD). CD is the practice of deploying your application automatically: as soon as your code has been pushed to the correct branch and tests have passed. We’ll talk more about this soon.
Case study – a simple API
I’m going to save any more explanation or discussion of the merits of CI until after we’ve seen an example, because this will make it easier to picture what’s going on.
The aim of this example is to make a very simple Python application, then use CI to automatically test it, and CD to automatically deploy it. We’re going to use GitLab CI, because it’s a neat, integrated solution that is easy to setup. You can view the finished repository containing all the files here.
Let’s start by creating a Python file containing our main application logic. In this case, it’s some string processing functions.
""" web/logic.py. Contains main application code. """
def capitalise(input_str):
"""Return upper case version of string."""
return input_str.upper()
def reverse(input_str):
"""Return reversed string."""
return input_str[::-1]
Let’s also add some extremely basic tests for this code:
""" test_logic.py. Tests for main application code. """
from web import logic
def test_capitalise():
"""Test the `capitalise` function logic."""
assert logic.capitalise("hackaday") == "HACKADAY"
def test_reverse():
"""Test the `reverse` function logic."""
assert logic.reverse("fresh hacks") == "skcah hserf"
assert logic.reverse("racecar") == "racecar"
Ok, now that we’ve made our main application code, let’s expose it over an API. We’ll use Flask for this. Don’t worry about meticulously reading this, it’s just here to serve as an example, and is shown here for context.
""" web/api.py. Expose logic functions as API using Flask. """
from flask import Flask, jsonify
import web.logic as logic
app = Flask(__name__)
@app.route('/api/capitalise/<string:input_str>', methods=['GET'])
def capitalise(input_str):
""" Return capitalised version of string. """
return jsonify({'result': logic.capitalise(input_str)})
@app.route('/api/reverse/<string:input_str>', methods=['GET'])
def reverse(input_str):
""" Return reversed string. """
return jsonify({'result': logic.reverse(input_str)})
if __name__ == '__main__':
app.run()
Note that we should test the API as well (and Flask has some nice ways to do this), but for conciseness, we won’t do this here.
Now that we have an example application setup, let’s do the part we’re all here for and add a CI/CD pipeline to GitLab. We do this by simply adding a .gitlab-ci.yml file to the repository.
In this explanation we’re going to walk through the file section by section, but you can view the full file here. Here’s the first few lines:
image: python:3
stages:
- analyse
- test
- deploy
This sets the default Docker image to run jobs in (Python 3 in this case), and defines the three stages of our pipeline. By default, each stage will only run once the previous stage has passed.
pylint:
stage: analyse
script:
- pip install -r requirements.txt
- pylint web/ test_logic.py
This is the job for our first stage. We run pylint as an initial static analyser on the code to ensure correct code formatting and style. This is a useful way to enforce a style guide and statically check for errors.
pytest:
stage: test
script:
- pip install -r requirements.txt
- pytest
This is our second stage, where we run the tests we wrote earlier, using pytest. If they pass, we continue to our final stage: deployment.
staging:
stage: deploy
script:
- apt-get update -qy && apt-get install -y ruby-dev
- gem install dpl
- dpl --provider=heroku --app=hackaday-ci-staging --api-key=$HEROKU_API_KEY
production:
stage: deploy
only:
- master
script:
- apt-get update -qy && apt-get install -y ruby-dev
- gem install dpl
- dpl --provider=heroku --app=hackaday-ci-prod --api-key=$HEROKU_API_KEY
Our aim here is to deploy the API onto some kind of server, so I’ve used Heroku as the platform, authorised with an API key.
This last stage is slightly different from the others because it contains two jobs that deploy to two places: staging and production. Note that we deploy to staging on any commit, but we only deploy to production when we push to or merge into master. This means that we can check, test and use our live app in staging after any code change, but the production app isn’t affected until our code is merged into master. (In a larger project, it often makes more sense to deploy to staging on master and only deploy to production when a commit is tagged.)
And that’s it! In less than 40 lines we’ve defined a completely automated system to check and deploy our code. We are rewarded by our pipeline showing up in GitLab as below:
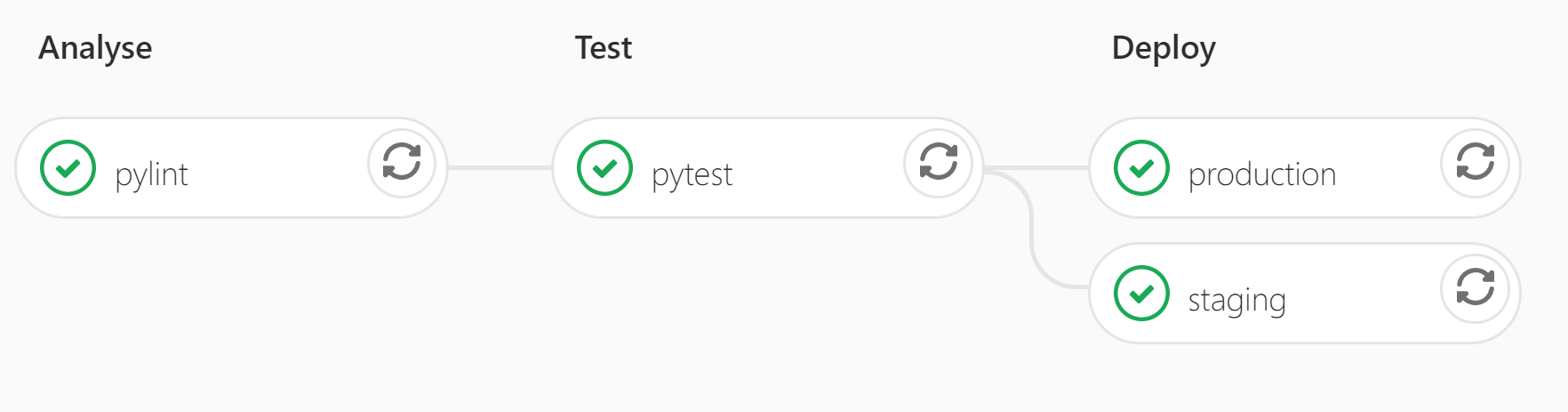
Additionally, the .gitlab-ci.yml configuration file which specifies what to automate is usually also version-controlled, so that if the CI pipeline evolves, it evolves alongside the relevant version of your code.
Why it’s useful
All manner of tasks can be automated using CI, and can allow you to catch errors early and fix them before they propagate technical debt in the codebase.
Common tasks for larger Python projects might be to test our code for compatibility with different Python versions, build a Python module as a wheel, and/or push it to PyPi. For projects using compiled languages, you could automatically build your binaries for all your target platforms. For web development, it’s easy to see the benefit of automatically deploying new code on a server once certain conditions have been met.
Furthermore, part of the reason that CI is so powerful is its close relation to version control. Every time that code is pushed to any branch in a repository, tests and analysis can run, which means that people who control master or protected branches can easily see if code is safe to merge in.
Indeed, whilst CI is most satisfying when the pipeline is full of ticks, it is most useful when it looks like this:
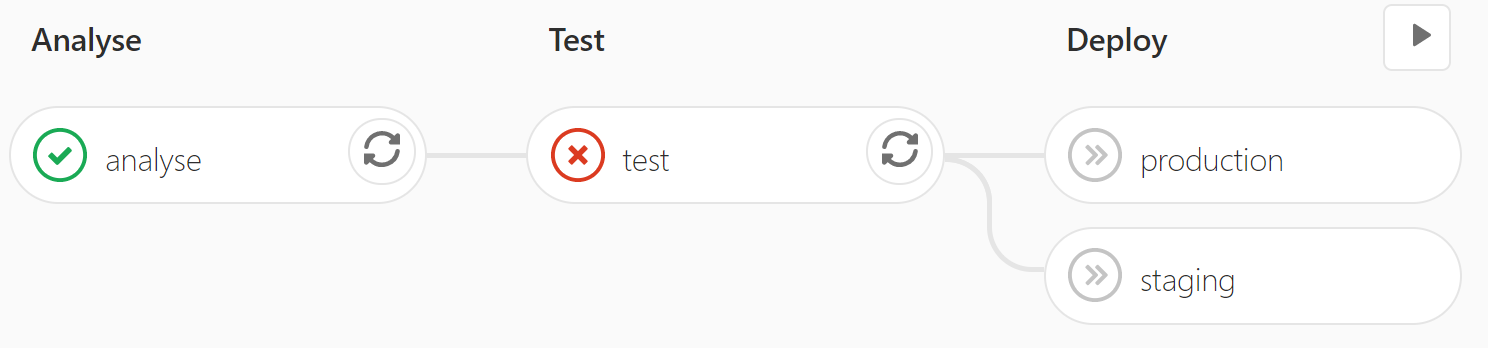
This means that the tests failed, and as a result, the broken code was not deployed. People can clearly see not to merge this code into important branches.
Conclusions: do you need CI?
CI/CD is definitely more useful in some cases than others. But if you’re writing any code at all, you can save yourself time by writing tests for it. And if you have tests, why not run them automatically on every commit?
I can personally say that every time I’ve set up a CI pipeline, not only has it saved me time, but at some point or another it got me out of a scrape by catching broken code. I’d wager it will do the same for you.














Like any software development methodology, CI/CD works well when applied thoughtfully to suitable problems (high-level APIs and mature code bases where changes are likely to be incremental and other teams will legitimately be consuming intermediate versions).
I did, however, work somewhere where management decided one day to enforce a CI/CD workflow on all teams regardless of how well it fit the problem space. I was working on a team building drivers and low-level data plane code which embodied the software half of a task that was split between a gang of FPGAs and a gang of threads on the x86 CPUs where the functionality implemented was effectively an 5-or-so stage pipeline that wove back and forth between the FPGA and the CPU where the last stsge is a handoff to an external process, and then another similar process in reverse on the other side.
Applying CI/CD techniques to ensure continuity and stability of the API between the end stages and the external consumer process makes sense because A) it’s a public API and B) it’s operations are somewhat high level (i.e. here are some buffers: fill them with packets or here are some packets, let me know when they’re all sent so I can reclaim the buffers).
The earlier stages, however, interlocked with the FPGA bitstream and needed to be developed in lock-step with the FPGA bitstream (and can’t be meaningfully tested without the actual target system (chassis, backplane, custom motherboard, and live connectivity via the 100G interfaces on the front panel) and a reasonably convincing and representative environment for it to operate in). Yes, with some extra effort we could make module-level tests with a simulated stand-in for the FPGA (wrap all MMIO access in ab opaque call that replaces it with socket messaging, and replaces all DMA with memcpy(), and in fact we did that for a while but since it needed reworking with every successive build of the bitstream it took as much work to maintain as the code it was meant to test, and worse it turns out that the majority of bugs arose from the “language barrier” between the software folks and the FPGA/ASIC folks so more than once the emulator/test jig ended up emulating what the software folks thought the FPGA folks meant not what the FPGA actually did.
Between that and the frequent incremental updates as the FPGA went from bare-bones functionality with a lot of stubs/placeholders to more and more functional features (and, over time, the design of the later features was revised to address lessons learned and improve integration with software and work around the occasional erratum in supporting chips such that some placeholders got replaced by real functionality as envisioned and some got ripped out and replaced with entirely dissimilar interfaces to the same functionality) it became clear that software emulation was not cutting it and our efforts were better applied to detailed instrumentation while running subsystem tests and full integration tests on the real hardware.
It was not easy to convince upper management (from whence the decree came that all teams must apply their chosen CI/CD workflow and Agile/Scrum development cycle down to the length of “sprints” regardless of whether it lined up with the FPGA development cycle or not) that the methodology and implementation they imposed organization-wide (which was working well for the UI amd control plane as you’d expect) was doubling or tripling our workload while adding little or no value.
The bottom line is this: No methodology is a magic bullet across all layers and applications; there are good ideas to be borrowed from many such approaches but in my 20+ years in the business I’ve found that the best results are to be had from stopping and thinking carefully about the tricky bits in your specific application, where errors creep in, and how best to catch them early, limit the blast radius, of disruption they cause, and go from there to synthesize a workflow and development method suited to the problem at hand from the bottom up.
The appeal of rigid top-down methodology is often the data and metrics it puts at the fingertips of project managers, etc. because they feel that the more data they have the fewer unseen risks can creep in. This is, of course, true but only to the extent that the data they have are meaningful… When the workflow is not well suited to the task at hand it is less likely that the metrics generated by the automation will be meaningful and indicative of stability/completeness/correctness/performance/whatever they’re trying to measure. It is far better to generate the right mstrics from the right workflow from the bottom up and teach management to interpret them than generate uniform metrics across all modules at all levels whether they’re meaning or not
I’m sorry but youbare wrong. CI/CD is just as useful for your project. I just think you guys may have handled it wrong.
So for one, I think your biggest beef is automated testing, as that is usually the most import stage in your CI. But at the very least, you can do static code analysis and style checking. That works for any project.
Now unit testing/application testing as part of the CI is indeed very complex and depending on how much hardware you have to emulate, very complex. But the solution here usually is to do inline testing as part if the pipeline, which a looks more like CD. I do assume you guys do actually perform testing on the real hardware, now if you can automate this, bobs your uncle.
Now this last step of course can be tricky, but a raspberry pi that you have a CI runner on probing and toggling your pins should get youbquite far. For example, 1 gpio to power up the FPGA, spi bus to programming it, gpio to power up your board/Linux, 1 gpio that triggers your fail/success. And then, it is just a matter of writing proper inline tests, which IMHO you need anyway. Some (time) investment there can’t be seen as bad.
Now if you don’t need or have automated testing, I do wonder how the production line would work without some tests.
Of course this post is all based on assumptions and experience from my end, so do pardon me if I am wrong, but in the case that I am, your product would be so exclusive, that the generalisation still holds.
I did some work with FPGA at university (couple of years) and have some friends doing FPGA work on daily basis (i am more software guy these days sadly). Yes, in software world there is this continuing debate how to do automated testing, to what extent. Some even debate if to them at all. In FPGA world, there is no such debate. You do tests. Always. 80% (or even more) debugging is done in simulation. And if the system is little more complex than just some glue logic, you need automation in tests – not just looking at the waveform. Personally i don’t know what is popular today, but i liked SystemC a lot – combined with Modelsim.
But testing is just one half of this – the second half of the CI/CD system is reproducible automated builds. And that is very big thing – if you can rely on some automated system, that the build is always going to be consistent – always from clean state. Also if some server based build systems are used (Gitlab / Jenkins …), than it is super easy to do small changes, you don’t need to try to make build working on your computer, you change what is needed and let the server do it for you.
Ignoring propriatery software for a moment, with the likes of docker, you can even have 99% CI equal builds locally. No need to set up build environments.
Run it once, run it everywhere the same way.
[snark}Ah, the java approach ;-){/snark]
Agree.. That’s right! “… but in my 20+ years in the business I’ve found that the best results are to be had from stopping and thinking carefully about the tricky bits in your specific application”
Management go from an observation like “All liquids may be potentially contained in a coffee mug.” to “A coffee mug is the perfect utensil for the transfer of any and all liquids” in 2 seconds flat.
Nicely put. Kind of like the flip side of ‘if you only have a hammer…’, instead ‘I added this new torque wrench to my collection – I think it’s amazing and I bet I can find a way to use it for anything (including nails)!
It’s like they’re dead weight trying to justify their jobs. Gotta find something to “improve”. A manager will get more rewarded for trying an idiotic idea than just doing nothing, because “at least they’re trying new things”
Your issue is a lack of preparation of your pipeline, as you should be able to decouple your system in a manner that enables segregation testing
If properly done you are able to generate a mocked endpoint or backend response for each and every external step, be it from the point of view of your x86 system or your FPGA system
The most common issue in CI/CD is people treat them as unit tests while they are integration tests… this is the sum of separate scenario which makes the CI, and it is specifically useful and powerful in large heterogeneous distributed systems
CI does testing, integration being the main one sure, but it ideally should do all possible forms of testing applicable. Unit tests for tricky important parts, interface testing, application testing, etc ec. Right test for the right code path. No point in unit testing 75% of the code if a singe application test already does that.
I guess in the end, what you’d aim for is a combined 100% coverage from different kind of tests.
If anything, it should find regressions. Just “xxx dollar bug caught’ would make it all worth it. Each new, not caught bug gets a test before anything in the codebase.
Your beef is with automated tests, and the fact that you lay the blame at the feet of CI/CD kind of proves you folks were in over your head, and possibly having a teamwork or software skills problem.
All an automated test does is confirm expected behavior. You start small.
IF the problem is defining useful test or correct behavior, you have a Requirements problem – meaning you’re still figuring out WHAT you’re building as you build it. I’d say that is EQUALLY as problematic as no test automation.
There’s plenty of talented developers and engineers who LOOK DOWN UPON test automation, or “developers in Test” (“scripters”).
^^ that broken perspective means it really, REALLY stings when tasked with writing tests, and they become painful, so the developer’s pride requires them to blame the testing mandate instead of themselves.
I’ve written automated test cases that easily exceed the code length of the object of my testing. Modeling behavior can be tricky… especially if a project DOESN’T include tests at the start. (IOW, if a developer asks to implement a pet feature, they’re more likely to do it if they’re not required to write a companion test…. start requiring a test and all of a sudden they don’t care about the pet feature anymore).
“start requiring a test and all of a sudden they don’t care about the pet feature anymore” In other words, testing is EXPENSIVE. That’s what I thought.
No, testing is something different from developing code for a feature then writing code for testing. Writing tests are not usually considered as cool an fun though.
Code without testing are more likely to contain errors. And THAT is expensive, if not found in time.
Each error in the code found by testing is a win. But people usually doesn’t think about that.
Now that I am a bald, old, and cranky independent, I never take a job where the boss says bad things about CI. Back when Grady Booch was first attempting to push programmers into software engineering, I used to adore all of the cute programming teams that were supposedly implementing CI along with XP. They thought they were cool. And they never released any production code.
But CI is essential – and should be used for *all* sizes of projects, whether hobby or professional. And my one-man shop eats its own dogfood. My CI ‘system’ is based on SCons. You can have my SCons-based check-in scripts when you pry my cold dead hands from my keyboard.
I’ve been reading “The Phoenix Project: A novel about IT, DevOps, and helping your business win” and thinking CI would have helped with the “developers are always breaking things, leaving everyone else to clean up” problem.
Definitely has tremendous advantages and revolutionary effects on software and the world in general. But like everything, there’s a trade happening. It’s mostly good I think, but a lot of software philosophies nowadays are contributing to a slow drift toward extremely complex and bloated systems that nobody intimately understands. And vague accountabilities. But it’s not just this specifically. It may be totally unavoidable based on the complexity of our world and the capacity of our hardware. As we know quite well, software is a gas and hardware is its container—so it always fills to match the size and shape of that container.
The advantages are huge, as I said. But it’s strange to think we’ll never really see anything like that early software again. I’m probably seeing parts of the past with rose-colored glasses as well, and change is inevitable. But I like to think we should still reflect on it and know that progress isn’t a straight line from past to future; it’s a multi-dimensional space with infinite choices, though some paths are far more apparent and seem to be something like destiny from our small vantage point in the present.
I think it’s pretty important to stress this should be implemented with something that also incentivizes optimization of old features instead of continuous adding and testing of new ones. Most people know that, but surprisingly often it isn’t practiced. Hey there, Microsoft. Of course they aren’t practicing a perfect implementation of this by any stretch of the imagination.
Completely agree. Like everything else there are tradeoffs – and personally some of the drifts don’t seem to be in a great direction. As you said – extremely complex and bloated, not usually of necessity, other than to trends of development. Abstract / interface / API the wazoo out of everything, to the point it ‘looks simple’ from a very high level, but good luck gaining an intimate understanding of what the code is up to. What used to be a 20-line block of code that actually did something you could follow and understand the intent and workings of to a low level at a relatively quick skim, and was easy to modify, is now blown apart into so many methods, test stubs, etc, to the point you’re jumping through so many different files and methods to follow the overall execution flow, that good luck building a mental picture of the process. It comes with some good, but I’m not sold it is for the better yet.
I use a Jenkins server to provide a CI system for a hobby project that I am the lead on and its great. Anytime someone commits something, it kicks off a build, compiles all the code, spits out some binaries and stores all the debug symbols and artifacts for later debugging of crashdumps. We dont do automated testing (its a game engine and automated testing is not really fesable) but its so great to have the games being built on this engine be able to just run a command and have it pull the latest build (whatever that might be) from the CI system.
No worries that people will ship builds not built by the CI system (and cause problems when we get crashdumps we can’t debug) and its easy to see if someone commits something that breaks the build.
What about Javascript which runs in the browser? I believe CI CD can do unit testing for Javascript functions, but can it be used to test and deploy javascript code which is run in the browser, alongside HTML and AJAX requests which populate data after page load or on user interactions?
Selenium, puppeteer, cypress and WebdriverIO. There are lots of tools that let you do automated tests on html+js.
I use Selenium and Behat/Mink for integration-testing my html-projects in a real browser. When a test fails, i have it set up to take a screenshot of the page, so i get an idea of what went wrong and quickly can see if it’s the test that’s wrong, or the product
You can run the application in a X11-server, and there are tools, like mentioned previosly that then can be run to test the result.
So except from running tools that statically check the JS-code, you can also run tests.
You almost got me with the “racecar” test.
I wand that for mechanical CAD. Interference tests and Parametrics go only so far…
Nice article. As a mostly hardware engineer, in a tiny team, I spend half my time coding, but not enough time to gain exposure to software methodologies, do articles like this are useful. I did spot an error though:
assert logic.reverse(“racecar”) == “racecar”
The answer was not reversed like the preceding fresh hacks test.
Look again. It almost fooled me.
Automated testing is extremely useful of course… but this is only as good as the person writing the tests… so many times I have been testing our product/s, as per the test case, but noticed on the side that something else about the product wasn’t working as expected…
Of course, but testing code is always in constant change. As usual, who control the controller? Who check the checker?
It is a common misconception that saving time is only useful when you’re doing something complicated.
CI is like source control, it is never “overkill” because it always makes operations easier.
There is no sacrifice. There is only less work.
There sure are circumstances where CI is not helpful. For one, you test suite must be bulletproof. If your tests are flakey then you will waste a lot of time tracking down the failures. If the failed tests do not result in a better product then you are wasting your time with testing. For two it is very difficult to reliably automate everything in the build process. Again if you end up with intermittent failures that must be tracked down then your attempts to save time will end up wasting time. And again if all of this effort does not result in a better product then it is all just a waste.
1) If you can’t write non-flakey tests, then you can’t write non-flakey code.
2) If you can’t reliably automate your build, your build process is not capable of producing production code.
3) What you’re saying seems to be, if your software development practices are poor enough, CI won’t help. Got it.
1. it is not a matter of writing non-flakey tests. If the task to be performed has built-in flakiness. For example your test may involve interoperation with third-party software over which you have no control.
2. real products are built for multiple platforms, build scripts must fire off builds on other systems that may rr may not be up and running. NFS mounts go stale. Do you actually work at a. company that builds real multi-platform products? I have workead at several and there are ALWAYS problems with multi-platform build scripts, they are in continuous need of tweaking.
3. no, it’s clear you don’t get it.
1. If you use flakey third-party software, then you have more problems then CI, that CI is not your problem.
If your tests can discover test cases when your third party software doesn’t work, then you can document and code around that. And give the third party software providers.
2. Real products have bugs, there are nothing strange about that. Yes, build scripts can fail, that is why we have testing and CI. So those can be taken care of, and improved. NFS mounts can go stale, but really, how common are that if you have a proper setup? Developing software IS about tweaking code, in the main source and in support code, like in testing.
3. What is it that we don’t understand? Yes, one can choose to not use CI, but that should not be because of the reasons you have given. But whatever, it is up to any company and project to select how they choose to develop code.
“If your tests are flakey then you will waste a lot of time tracking down the failures.”
My approach in that case is simply to isolate the flakey tests, which presumably have external requirements that aren’t always met, and not to include them in the automated part of the process.
Even if you didn’t have CI and only ran tests by hand, you’d still be grouping them to isolate the ones that have to make assumptions, and those wouldn’t be part of the default set.
If you’re making a product, the product will benefit from CI and automated testing because at a minimum you have to do regression testing for your fixed bugs. Your product’s reputation is on the line. If you do no other testing or automation, at least do that.
High level tests that take a long time and require an environment to be set up can be triggered by release tags, instead of just by a checkin.
(I was actually assuming that the people who consider it “overkill” are doing hobby projects, and they’ll definitely benefit from chasing down whichever bugs they decide to chase down!)