
The concept of Continuous Integration (CI) is a powerful tool in software development, and it’s not every day we get a look at how someone integrated automated hardware testing into their system. [Michael Orenstein] brought to our attention the Hardware CI Arena, a framework for doing exactly that across a variety of host OSes and microcontroller architectures.

Here’s the reason it exists: while in theory every OS and piece of hardware implements things like USB communications and device discovery in the same way, in practice that is not always the case. For individual projects, the edge cases (or even occasional bugs) are not much of a problem. But when one is developing a software product that aims to work seamlessly across different hardware options, such things get in the way. To provide a reliable experience, one must find and address edge cases.
The Hardware CI Arena (GitHub repository) was created to allow automated testing to be done across a variety of common OS and hardware configurations. It does this by allowing software-controlled interactions to a bank of actual, physical hardware options. It’s purpose-built for a specific need, but the level of detail and frank discussion of the issues involved is an interesting look at what it took to get this kind of thing up and running.
The value of automatic hardware testing with custom rigs is familiar ground to anyone who develops hardware, but tying that idea into a testing and CI framework for a software product expands the idea in a useful way. When it comes to identifying problems, earlier is always better.



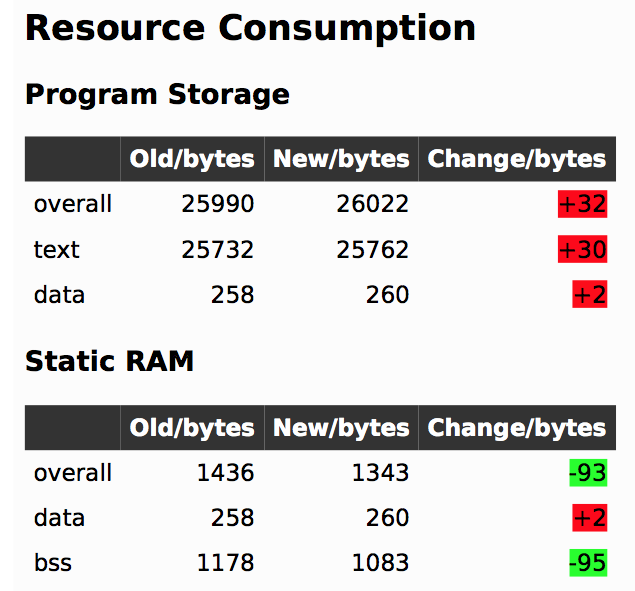 In firmware-land, where flash space can be limited, it’s nice to keep a handle on code size. This can be done a number of ways. Manual inspection of .map files (colloquially “mapfiles”) is the easiest place to start but not conducive to automatic tracking over time. Mapfiles are generated by the linker and track the compiled sizes of object files generated during build, as well as the flash and RAM layouts of the final output files.
In firmware-land, where flash space can be limited, it’s nice to keep a handle on code size. This can be done a number of ways. Manual inspection of .map files (colloquially “mapfiles”) is the easiest place to start but not conducive to automatic tracking over time. Mapfiles are generated by the linker and track the compiled sizes of object files generated during build, as well as the flash and RAM layouts of the final output files. 








