
What if your microcontroller IDE was running on the microcontroller itself and not hosted on the computer you use to do the programming? The greatest legacy of Arduino in all its forms has arguably been a software one, in that it replaced annoying proprietary development environments with one that installed easily on a range of operating systems, was easy to use, and above all, worked. The next level of portability is to get rid of any specialize computer-side software. [Ronny Neufeld] wrote MicroIDE for ESP32 as an IDE accessible through a web browser, which interestingly is hosted on the target device itself.
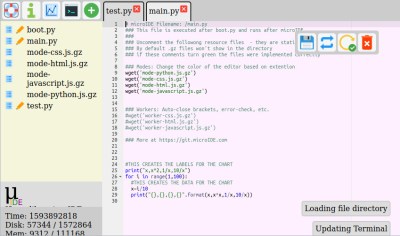 Using the IDE is easy enough, install a binary, connect to the ESP with a web browser, start writing MicroPython code. There is a choice of connecting directly to the chip as a hotspot, or connecting via another WiFi network. The interface is looking pretty slick but he’s at pains to remind us that it’s a work in progress. Sadly there is no source code yet as it’s a binary distribution that is free for non-commercial use, we’d hope that an open-source release might one day happen. It’s not for everyone, but the convenience of accessing the same interface from almost any modern device should help attract a healthy community.
Using the IDE is easy enough, install a binary, connect to the ESP with a web browser, start writing MicroPython code. There is a choice of connecting directly to the chip as a hotspot, or connecting via another WiFi network. The interface is looking pretty slick but he’s at pains to remind us that it’s a work in progress. Sadly there is no source code yet as it’s a binary distribution that is free for non-commercial use, we’d hope that an open-source release might one day happen. It’s not for everyone, but the convenience of accessing the same interface from almost any modern device should help attract a healthy community.
This appears to be the first web-based on-chip ESP IDE we’ve shown you. But it’s not the first on-chip coding example, as this BASIC interpreter shows.
[Main image source: Ubahnverleih / CC0]














Indeed, reminds me of the oldie XT days with DEBUG on MS-DOS 8088 and 8086 that was a lot of fun, very absorbing…
What’s the best update for MS-DOS DEBUG these days that runs native on dal core celerons and contemporary i5’s – I have a few laptops that “need work” ?
Thanks for post :-)
Surely not the first one. There’s Annex WiFi RDS, an integrated BASIC IDE for ESP8266 and ESP32. https://sites.google.com/site/annexwifi/home
Annex Wifi RDS runs well on ESP8266, i like it for testing new peripherals.
But on ESP32 it is only in beta stadium.
Oh nice! I might actually look into trying to add some integration with my own WebIDE product for the Pi.
This reminds me of the first time I used my BeagleBone Black.
Steps to get started were:
1). Read some parts of the manual.
2). Plugged it with a cable into an USB hub (no power cord, just USB).
3). Browse to: 192.168.7.1
4). Start exploring / Coding.
About an hour later I concluded I had no intention in “bonescript” (Based on Javascript) and the capabilities of the browser based “Cloud 9” IDE was just as bad as the “arduino” stuff.
I much prefer a decent IDE and C or C++ compiler, even if it takes some more effort to set it up and get started.
The fact that Tcp/Ip over USB “just worked” without any driver installation was pretty amazing to discover back then. Later I became used to such things “just working” on my Linux box.
This is a good example of something that makes me think, “that’s pretty cool,” but then I see the closed source and I think, “pass.” It’s interesting enough that I’m tempted to try it out, but not useful enough to get me to go closed source.
I suppose it’s also a good example of when you should ask, “what license should I choose when sharing my work?” I can’t think of any situations when you’d want easy access to reprogramming your device that aren’t opensource or hacky. Who’s going to use this in a closed source, for profit project?
Wait… My softball comment is awaiting moderation after my making lots of posts, but the one below me ripping this app a new one is auto accepted? And neither of us is using an account? Which word in my post caused the moderation jingle? I’ll never use it again.
The comment moderation system is seriously screwed up
There have been several web based IDE for Lua (NodeMCU and possibly other Lua ports to ESP8266/ESP32) since at least 2015.
https://github.com/moononournation/nodemcu-firmware probably is not what we call an IDE, but maybe seen as a Lua ancestor to this µPy thing.
This reminds me that there’s also an esp Basic
http://www.esp8266basic.com/
So far I haven’t found any bugs in the ESP32 version, although the MP3 playback is a little bit unstable. But that’s already known and will hopefully be fixed soon.
“Modern microcontrollers have cycles to spare; we don’t need cross-compilers” is exactly the same as “modern fighters will win with missiles; we don’t need guns”. It’s a popular, naiive, understandable misconception that apparently needs to be disproven every generation or so.
First off, there is a cross-compiler for MicroPython, mpy-cross. The ability of MicroPython to actually compile directly from text is just an additional feature. It doesn’t ever have to be actually used.
Second, it’s also a popular misunderstanding that scripting languages for microcontrollers only exist because people figure they can waste cycles to make development easier. It’s also an easy way for microcontrollers to essentially extend their code storage capability in an unlimited, safe, and platform-independent way: Gcode’s obviously a scripting language (with some implementations being Turing-complete!) – are you going to suggest that those programmers are naive and, in fact, every CNC build or 3D print should be cross-compiled into firmware?
Haha, this takes “Integrated” Development Environment to another level.
I prefer to keep all my sources on my PC for source control and backup.
“replaced annoying proprietary development environments”: Seriously? Arduino is the crappiest IDE I’ve used since 1987. With it’s primitive editor and lack of debugging tools, it’s a sin that we inflict it on beginners. Give me an “annoying proprietary development environment” any day.
I agree. Arduino is definitely not production-ready software. “All in one – best in none” comes to my mind. Any serious ESP32 dev is going to use ESP-IDF. Period.
Dare I mention forth created by Chuck Moore in the late 60’s? OS, language and IDE in almost no space.
Or swapforth created by James Bowman about 5+ years ago?
Nowadays you can have a 16-bit ans-forth compliant system, usable stand-alone, compiled right into a 1k gate FPGA using entirely open source toolchain that you can run on a raspi! (just attach a couple wires for rs232 console into it).
Or, put it on any larger FPGA, and you have just about the ideal ‘FPGA switch-flipping management engine’ to go with whatever custom dataprocessing pipeline you also put in the same FPGA.
I have a variant I call the j4a – it’s software compatible with the j1a, but has four hardware contexts that get round-robin access to the shared SRAM / ALU / IO space. This allows me to do three stupid-simple ‘bare-metal style waitloop’ ‘drivers’ to talk to other chips etc, all with completely independent timing, and STILL have that in-hardware forth cli waiting on my every keystroke, just the other side of a rs232 port.
This is exactly enough to be able to easily do three jobs that just exchange data via a couple named variables, and from the forth CLI they act just like they’re memory-controller shadowing DMA processes that consume zero cpu time.
This still executes about 12 M forth words / sec as well – trivially simple, cycle-accurate, and remarkably reliable operation. No thread interlocks, no ‘OS’ management of anything, almost no effort to co-exist.
I have it set up so one can share ports within the IO space to do things like independently flash LED’s on the same port with different ‘cores’ without clobbering each other’s bits. (you can pre-set a register with a special io address, that lets you define which bits you want to write / read on a port without clobbering/noticing the others).
Blinking one LED is fine, but try blinking three with different periods just as trivially! On this thing, it’s as easy as defining a word to blink the requisite led according to whatever pattern you like, just waiting in spinloops for timing, and then assigning that word to be run by one of the other three ‘cores’ in the background.
And they do, with cycle-accurate timing, since this architecture eliminates jitter due to resource sharing, that otherwise makes common tasks like correctly talking to several different 1-wire busses at once such a pain.
I have one fork set up with three separate SPI master interfaces, and another one with two serial interfaces and an SPI slave — with a quad-buffered separate space to get received data from another SPI interface, but a slave which some other chip pushes data into — at my leisure, without that other chip being able to vary or affect my core’s timing at all.
The whole forth image you end up with can be saved right back into the FPGA image, so the FPGA’s own autoboot configure sequence preloads the SRAM with a program ready to run right out of reset. I usually work in a non-forth-traditional ‘recompile from a whole file kept in a git repo’ way, which makes it much easier to resume work after a long time away, since there’s a forth source file which can be just squirted at the ‘default’ swapforth image to rebuild that app.
Worth noting that the fairly complete (and very usable) ans-forth lives entirely in the FPGA’s SRAM — takes about half the SRAM blocks of a 4k/8k ice40 (or all of a 1k). This typically leaves you with about 3.5k 16-bit words to work in, which goes a very long way with highly factored forth code, especially when you completely avoid having to deal with useless things like an RT OS or task managers etc.
The ‘j4a’ usually takes about half the logic of a 4k/8k part (which are the same — the 4k was a feature-crippled 8k chip, and you get to use all 8k actual gates in it with the OSS toolchain). Rebuilding the whole ‘SoC’ image takes about 2 minutes — maybe closer to 15 on a raspi2.
The interesting thing is, I don’t think I’m close to getting the full performance out of it.
The limiting factor is the SRAM access speed, and it seems it may be able to keep up with several hundred MHz there — this gets shared equally amongst all the separate hardware ‘contexts’ (the data/return stacks, which are not in SRAM blocks). The fact that the j1 was designed to be a 1-cycle state machine with good timing means that run this way, it can be trivially pipelined without introducing any pipeline hazards. This should mean that the ALU can be spread over four cycles without affecting each ‘cores’ execution speed at all.
So at the moment, I’ve been using 48MHz -> 12M forth cycles/sec and placing with arachne-pnr, but nextpnr does timing-driven placement…. Ergo it should be possible to drastically improve on that 48 MHz clock – perhaps enough to achieve 48 MHz/core (like the j1a, ie, machine loop execution limited) speed.
Sounds insanely cool! Did you publish j4a?
Hi , I think it is a tremendous work , but it is useless in production environments, only for educational purposes. Thanks