Netflix has recently announced that they now stream optimized shot-based encoding content for 4K. When I read that news title I though to myself: “Well, that’s great! Sounds good but… what exactly does that mean? And what’s shot-based encoding anyway?”
These questions were basically how I ended up in the rabbit hole of the permanent encoding optimization history, in an effort to thoroughly dissect the above sentences and properly understand it, so I can share it with you. Before I get into it, lets take a trip down memory lane.
The 90’s

In the beginning of the nineties if you wanted to display an image file on your computer, like a GIF or the new JPG format, you would need to use a program for that. I think I used CSHOW back then. For ‘videos’ me and my friends exchanged FLIC files, which were a sequence of still frames which would be flipped through rapidly to achieve the illusion of movement in a software I can’t recall anymore. Despite some video compression standards were already developed in the early 90s, video files were not so common. Data storage was scarse and expensive and not even my 486 DX 33Mhz, 8 MB Ram and 120 MB HDD desktop could probably handle in any way (speed, ram or disk) the decoding of a modern video file.
I don’t even imagine how long it would take to transfer any meaningful video with my 28.8 kb/s modem.
JPEG compression was a game changer for images. We could now store huge images with pretty much the same quality in much less space. When it appeared, it was almost magical to me. We were constantly searching for the best compression algorithms and tricks we could use in order to spend less on floppy disks. There was ARC, ARJ, LHA, PAK, RAR, ZIP, just to name a few I used in MS-DOS. Those were all archivers with lossless compression and most would fall short on high definition images. But JPEG uses lossy compression and so it could get much smaller images at the cost of image quality.
For videos, being a sequence of images, the logical next step was Motion JPEG. M-JPEG is a video compression format in which each video frame is compressed separately as a JPEG image so that meant that you would get the benefits of JPEG compression to applied to each frame. Like FLIC, but for JPEGs.
Since the compression depends only on each individual frame, this is called intraframe compression. As a purely intraframe compression scheme, the image quality of M-JPEG is directly a function of each video frame’s static spatial complexity. But a video contains more information than the sum of each frames. The evolving, the transitioning from one frame to another is also information and the new algorithms soon took advantage of this.
From Stills to Motion
MPEG-1 was one of the encoders that explored new ways to compress video. Instead of a each individual frame being compressed, MPEG-1 split the video into different frame types. For simplicity, let’s say there are two major frame types in MPEG-1, the key frames (I-frames) and the prediction frames (P-frames, B-frames). MPEG-1 stores one key frame, which is a regular full frame in compressed format, and then a series of prediction frames, maybe ten or fifteen. The prediction frames are not images but rather the difference between the frame and the last key frame, hence saving a lot of space. As for storing audio, MPEG-1 Audio (MPEG-1/2 Audio Layer 3) uses psychoacoustics to significantly reduce the data rate required by an audio stream as it removes parts of the audio that the human ear would not hear. Most of us know this audio format simply by MP3.
![]() As cool and inventive as it sounds, even before the first draft of the MPEG-1 standard had been finished, work on MPEG-2 was already under way. MPEG-2 came with interlaced video, a technique for doubling the perceived frame rate of a video display without consuming extra bandwidth, and sound improvements. The MPEG-2 standard could compress video streams to as much as 1/30th of the original video size while still maintain decent picture quality.
As cool and inventive as it sounds, even before the first draft of the MPEG-1 standard had been finished, work on MPEG-2 was already under way. MPEG-2 came with interlaced video, a technique for doubling the perceived frame rate of a video display without consuming extra bandwidth, and sound improvements. The MPEG-2 standard could compress video streams to as much as 1/30th of the original video size while still maintain decent picture quality.
MPEG-3 was integrated into MPEG-2 when found to be redundant. But then came the more modern MPEG-4. MPEG-4 provides a framework for more advanced compression algorithms potentially resulting in higher compression ratios compared to MPEG-2 at the cost of higher computational requirements. After being released, there was a time when a lot of different codecs coexisted, and it was sometimes frustrating for the regular user to try to play a video file. I remember not having the DivX codec, or Xvid, or 3ivx, or having to install libavcodec and ffmpeg, or maybe trying to play it in Quicktime player, or just giving up in tears…
But one thing was certain, we now had very decent quality in our PCs, Playstations, and digital cameras.
Streaming

Practical video streaming was only made possible with these and other advances in data compression since it is still not practical to deliver the required amount of data in an uncompressed way. Streaming has it’s origins in streaming music, sharing music and ultimately developing P2P networks, and there are tons of interesting stories to be told. Nevertheless I’m going to focus on video streaming in the article since the whole goal was to understand what is “optimized shot-based encoding”.
We currently live in the middle of a Streaming War, with fierce competition between video streaming services such as Netflix, Amazon Prime Video, Disney Plus, Hulu, HBO Max, Apple TV+, Youtube Premium, CBS All Access, etc.
All those services try to deliver new and exclusive content and deliver it well. Delivering well involves many aspects, from content freshness to user experience, but one thing I think we can agree upon: when the video quality sucks, no marketing or UX team can save the day. With this in mind, several modern algorithms for video encoding are used, including H.264 (a.k.a. MPEG-4 Part 10), HEVC, VP8 or VP9. Besides those, each service try to enhance their own video quality as they can.
Nexflix Tech Blog
Netflix has a nice tech blog where you can read some serious geeky video content. They introduced many different optimizations into their network and their compression algorithms which sometimes they share how in the blog. In the end of 2015 they announced a technique called Per-Title Encoding Optimization.
When we first deployed our H.264/AVC encodes in late 2010, our video engineers developed encoding recipes that worked best across our video catalogue (at that time). They tested various codec configurations and performed side-by-side visual tests to settle on codec parameters that produced the best quality trade-offs across different types of content. A set of bitrate-resolution pairs (referred to as a bitrate ladder) … were selected such that the bitrates were sufficient to encode the stream at that resolution without significant encoding artifacts.
At that time, Netflix was using PSNR (Peak Signal-To-Noise Ratio) in dB as a measure of picture quality. They figured out that this fixed bitrate ladder is more an average or rule of thumb for most content, but there are several cases where is doesn’t apply. Scenes with high camera noise or film grain noise, a 5800 kbps stream would still exhibit blockiness in the noisy areas. On the other end, for simple content like cartoons, 5800 kbps is an overkill to produce 1080p video. So they tried different parameters for each title:
Each line here represents a title, a movie or an episode. Higher PSNR means better overall image quality: 45 dB is very good quality, 35 dB will show encoding artifacts. It’s clear that many titles don’t actually gain a lot from increasing the bitrate beyond a certain point. In general, per-title encoding will often give you better video quality, a either higher resolution for the same bitrate or same resolution for less bitrate.
Title contents can be very different in nature. But even within the same title, there can also be high action scenes and later a still landscape. That’s why that when Netflix decided to chunk-encode their titles to take advantage of the cloud, by splitting the movie into chucks so it could be encoded in parallel, they started to test and implement Per-Chunk Encoding Optimization in 2016. It’s the same logic as per title, but for each chunk in the title. It’s like adding one more level of optimization.
Finally, in 2018, Netflix started to implemented Optimized shot-based encoding, and its now available also in 4K titles since August. So back to the original question. What if, instead of somehow random chunks to encode our video, which result in random Key-frames being generated (of them some might be very similar which is not optimal since they take a lot of space), one could choose the right and optimal Key-frames for each title?
In an ideal world, one would like to chunk a video and impose different sets of parameters to each chunk, in a way to optimize the final assembled video. The first step in achieving this perfect bit allocation is to split video in its natural atoms, consisting of frames that are very similar to each other and thus behave similarly to changes to encoding parameters — these are the “shots” that make up a long video sequence. (…) The natural boundaries of shots are established by relatively simple algorithms, called shot-change detection algorithms, which check the amount of differences between pixels that belong to consecutive frames, as well as other statistics.
Besides optimizing the Key-frames for encoding, shot-based encoding has some other advantages, such as seeking in a video sequence leads to natural points of interest (signaled by shot boundaries) and encoding parameter change in different shots is unnoticeable for the user since the Key-frame is very different. All of these changes are tweaks for the encoders that can actually be H.264 or HEVC or VP8, it makes no difference.
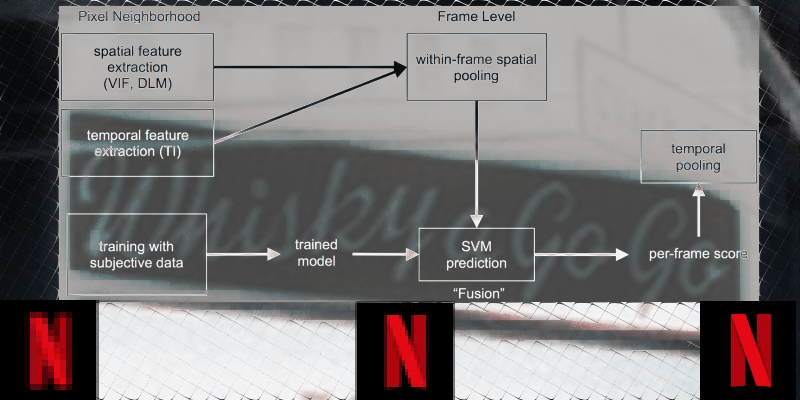
Is it worth all the trouble? To answer let’s look at the most recent video quality rating that Nexflix uses: the Video Multi-method Assessment Fusion, or VMAF. Traditionally, codec comparisons share the same methodology: PSNR values are calculated for a number of video sequences, each encoded at predefined resolutions and fixed quantization settings according to a set of test conditions. This work well for small differences in codecs, or for evaluating tools within the same codec. For video streaming, according to Netflix, the use of PSNR is ill-suited, since it correlates poorly with perceptual quality. VMAF can capture larger differences between codecs, as well as scaling artifacts, in a way that’s better correlated with perceptual quality by humans. Other players in the industry recognize and are adopting VMAF as a quality rating tool.
Using VMAF Netflix started to run test on their 4K titles. The results were quite impressive.


Above are just two examples, but on average they need a 50% lower bitrate to achieve the same quality with the optimized ladder. The highest 4K bitrate title on average is 8 Mbps which is also a 50% reduction compared to 16 Mbps of the fixed-bitrate ladder. Overall users get more quality for lower bitrate, which is quite an achievement.
And since a picture is worth a thousand words, I’ll finish with this (notice the difference and bitrate):

Disclaimer
The author is not trying to start a codec flame war, there are many codecs and standards, and MPEG seemed proper for demonstration purposes. The shear amount of encodings, specifications and their aliases pretty much guarantees mistakes somewhere in the text, feel free to correct in the comments.
The author also does not endorse any streaming services. We mentioned Netflix just because it shares its encoding tricks with the public. We’re sure the other services have clever stuff going on as well, they’re just not telling.














Lol hopefully they will have it ironed out by the time I get around to watching things in 4k in a few years. I think I will be okay without seeing every bad strand of hair on Moira’s wigs.
shear amount –> mistakes somewhere in the text
I see what you did there :P
It seems wrong that such a well-written and informative article only so few comments. I too have seen this technology advance from early 16 color bitmap image days to today’s 8K video, although it has never been my field of expertise. I’ve been content to learn enough to know how to encode my mp3 collection (now flac), and discontented during the aforementioned codec wars when it seemed that you never quite had the correct codec installed for the website that you were visiting.
Thanks!
No mention of quicktime video introduced in 1991, funny how your 486 could not play videos but my 68020 Mac could play that Michael Penn video “Seen the Doctor” from the Quicktime demo disk at full frame rate in full color and stereo sound!
albeit in stamp size. (i have the same quicktime cd-rom for developers with the tick, tick, tick theme) this is where Avid started from.
It is almost like Apple engineered a software advantage seeing as a 486DX 25 MHz has the same performance like a 68020 25 MHz in the real world (about 8 MIPS). The 486 has a somewhat higher IPC, which starts to show on higher MHz numbers e.g. 33MHz…
Apple contracted San Francisco Canyon Company to port QuickTime to the Windows platform.[33] Version 1.0 of QuickTime for Windows provided only a subset of the full QuickTime API, including only movie playback functions driven through the standard movie controller.
You are most likely using quicktime technology daily without even realizing it.
Hoffert work at Apple Advanced Technology Group (huge campus full of highly paid nerds working exclusively on video) and consequent patents from 1990 US5046119A for Apple Video ‘road pizza’ codec is pretty much 90% of S3TC word for word including math formulas. S3 even sued Apple for S3TC royalties and lost because of it :-) Sadly Apple loves patents and didnt bother trying to invalidate. Nowadays S3TC is standardized as DirectX Block Compression 1-3. Its technology was so good we only got better algorithms in 2007 with introduction of DX11 BC6H/BC7 modes.
Huh, I was under the impression that keyframes were already generated by modern codecs when there were dramatic changes in scene, rather than any sort of regular interval or other “dumb” criteria.
I’m all for more intelligent encoding though, it’s depressing to go watch a movie on “4k streaming!!!!!!” and have it be blurrier than a proper blu-ray disc at 1080p.
That used to be the case when you encode to a single for example DVD rip.
With multi bitrate streaming, the video is divided in chunks (tor example 2 seconds each). Each chunk is encoded in a series of quality (or bitrate) settings. Each chunk is encoded separately and thus has to start with a keyframe. This allows the video player to pick which “bitrate/quality” to download for each chunk, based on the network conditions.
Because each chunk is encoded independently it can also be decoded independently. The the video playback looks seamless switching between bitrates because each chunk starts and ends at the same frame.
You would notice slight blurriness when the network bandwidth decreases and it will improve after a few seconds. In many video streaming services the video starts somewhat blurry and “sharpens” shortly after. This is because the player starts with conservative estimation of the network bandwidth and “learns” it can go higher after the first 2-3 chinks have been downloaded.
The proposed innovation is: instead of arbitrary 2 second boundaries, the encoder selects the duration of each chunk based on heuristics from the video sequence.
I was wondering the same as Eric. Thanks for the explanation!
Yeah one would think that that’s kind of the main point of I and P frames, but it seems to have gone differently and media is often(?) simply encoded with a set interval.
I can imagine that for bandwidth and decoding requirements it could be required to have a minimum and maximum amount of I-frames in a window (or multiple sized windows for additional stability), but none of these are hard problems imo.
One downside of the new compression schemes is that you get variable data rate. At some points of the film, you have lots of changes, so lots of key frames, so lots of data, and at other points you don’t.
Which means lots more buffering.
Well, if their little graph is to be believed you end up with twice the duration for the same amount of data, so you can buffer the same amount of data as now and have double the time. You’d also be able to buffer high bit rate areas during low bit rate “downtime”.
I was rather thinking about bandwidth limited situations, where your “average” bitrate turns out to be unsustainable because half way into the movie you suddenly have to download ten times faster to keep up, or maybe the movie starts with lots of fast cuts and you don’t have enough time to buffer that.
The benefit of constant bitrate is that it’s predictable.
“half way into the movie” gives caching some 45 minutes to buffer that data so once you get there, decoder already has it locally. Of course, if your bandwith is barely coping on the low side of variable bit rate that’s a different story.
They are streaming many many simultaneous users so buffering means you will not see the spinning beach ball as often. Just imagine how many people are watching Teenage Bounty Hunters right now and think of the required bandwidth and CPU.
That last picture gif is nonsensical and misleading, to the point of outright lying. It mentions the average bitrate for the two streams, but it says nothing about the number of bits actually used in the two frames that are compared. It’s a cherrypicked example.
All this history of streaming video and yet no mention of the Silicon Graphics XFS file system that made streaming video practical on the crude hardware available at the time
I would say the hardware mpeg and jpeg implementations had more to do with that.
So you don’t remember how godawful slow the disk drives we’re back then? Seeking was a nightmare which is why XFS was huge because it could handle enormous contiguous video files that could be streamed with minimal seeking. Every other file system at the time would thrash away on big video files.
And this is why buffering is good because the host can send out the entire disk sector to the client in one shot, again reducing the number of disk seek operations when there are many clients.
Oh and also do not forget the Silicon Graphics Reality Engine which was mapping live video streams onto 3D polygon faces in the mid 1990s.
All those images up there are deep links hosted by medium.com. I’m sure Ted Nelson and Sir Berners-Lee would be proud, but it doesn’t seem either kosher, or good practice to rely on the fickleness of someone else’s server.
Assuming that Netflix has gone under due to thier malfiesance and unmentionable films offered. 800% cancellations and still sticking to thier guns. Gross.
So you are mad because Netflix is doing an expose of Jared Kushner’s malfeasance?
And also not to be forgotten here is the pornography industry who were doing streaming video on a massive scale long before anyone else:
https://www.datacompression.info/how-the-adult-industry-revolutionized-image-and-video-compression/amp/
i’m hoping they’ll do the same for VR!
I just wanted to give a shout out and thank you for this article. I’m on the (now) upper end of digital users that remembers this time fondly, and pieces like this are going to be the history books (blogs??) of the future. Well put together and a trigger to a number of bits of how i spent the 90s and 00s!
Honestly, tying bitrate to resolution seems outdated. It makes everything similarly artifacted and crappy no matter what your bandwidth is. It only changes the size of the obvious JPG-y blocks.
Fancy streaming video having more pixels is nice – but each bump upwards in storage and network pressure should ideally be a choice between that, and the same pixels with better quality.
Bitrate is everything to a streaming service. And users play back a variety of resolutions. So optimizing for bitrate and SNR at multiple resolutions is the most sensible way to get the best perceived quality.
“I don’t even imagine how long it would take to transfer any meaningful video with my 28.8 kb/s modem.”
I remember watching streaming video via RealVideo at 28.8 and thinking it was amazing. No, neither the resolution nor the framerate were anything that would be considered acceptable by today’s standards but if you were watching the news or watching a show for the story, not just the CGI effects it worked. It certainly wasn’t any worse than tv before cable when you watched with a little bit of static because the show you wanted to see was on a station that wasn’t quite local enough to be clear.
Don’t get me wrong, all this great high-resolution video is nice. I certainly don’t want to go back to the old stuff. I’m just saying, we can have something “meaningful” with far less. Also, for me I think it would be nice if modern software would fall back to lower resolutions and framerates more gracefully when the network has issues rather than just being hi-def or bust.
Just in case… Google recommended using 2-pass, constrained-q mode for a while for VP9 as very good “fire and forget” solution: you specify desired Q and max bitrate. At easy movies it makes it perfect, fitting requested q-value. And if move proves to be difficult, bandwidth and storage usage constrained by max bitrate. It would somewhat degrade appearance but at least keep things manageable. Which is more than resonable for video hosting doing batch encodings at huge numbers.
Same more or less true for AV1 as well, except it would be far better in bitrate to quality tradeoff, so if it hits BW limit far better picture results.
Not sure I followed this explanation, are you saying that Netflix uses CBR (constant bitrate) instead of multi-pass VBR (variable bit rate) when encoding videos?
If you ever tried Handbrake or the like, you’d notice that CBR provides faster encoding than multi-pass VBR.
However, encoding videos is done once, I assume a huge company like Netflix can afford to do multi-pass VBR encoding, even if it takes twice the time to encode.
Which makes me wonder the rationale for the explanation on this article.