Ever needed to get data from a web page? Parsing the content for data is called web scraping, and [Doug Guthrie] has a few tips for making the process of digging data out of a web page simpler and more efficient, complete with code examples in Python. He uses getting data from Yahoo Finance as an example, because it’s apparently a pretty common use case judging by how often questions about it pop up on Stack Overflow. The general concepts are pretty widely applicable, however.
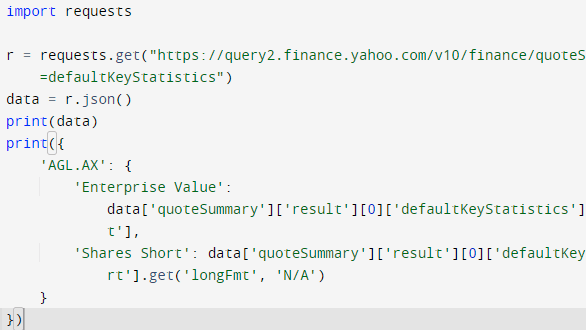
 [Doug] shows that while parsing a web page for a specific piece of data (for example, a stock price) is not difficult, there are sometimes easier and faster ways to go about it. In the case of Yahoo Finance, the web page most of us look at isn’t really the actual source of the data being displayed, it’s just a front end.
[Doug] shows that while parsing a web page for a specific piece of data (for example, a stock price) is not difficult, there are sometimes easier and faster ways to go about it. In the case of Yahoo Finance, the web page most of us look at isn’t really the actual source of the data being displayed, it’s just a front end.
One way to more efficiently scrape data is to get to the data’s source. In the case of Yahoo Finance, the data displayed on a web page comes from a JavaScript variable that is perfectly accessible to the end user, and much easier to parse and work with. Another way is to go one level lower, and retrieve JSON-formatted data from the same place that the front-end web page does; ignoring the front end altogether and essentially treating it as an unofficial API. Either way is not only easier than parsing the end result, but faster and more reliable, to boot.
How does one find these resources? [Doug] gives some great tips on how exactly to do so, including how to use a web browser’s developer tools to ferret out XHR requests. These methods won’t work for everything, but they are definitely worth looking into to see if they are an option. Another resource to keep in mind is woob (web outside of browsers), which has an impressive list of back ends available for reading and interacting with web content. So if you need data for your program, but it’s on a web page? Don’t let that stop you!














Nice! I am also a fan of finding these apis where available. I figure it’s even polite, since it’s less load on their server… Now if only I could figure out how to extract the data from my local health department Microsoft PowerBI Covid dashboard, but as the spinners on every page load suggests, it’s all overly complicated and computed on demand despite being updated once a day. So many xhr requests on that page..
(I do wish folks would stop putting blog posts on Medium, the whole “two members posts left” or “out of posts for the month” is a real drag. Do people get paid by Medium or something?)
Yes, Medium pays some authors, and quite well too I’m told.
So it’s just a magazine now? Readers pay to subscribe and they pay authors to write articles.
“I figure it’s even polite, since it’s less load on their server…”
I’m sure a lot of them disagree because they want you to see their ads and/or get exposed to the other services they offer.
I agree about Medium. It was slick when it was new and free, but if you’ve got something important you want people to read, find a better place than Medium. I won’t waste a moment or have a second thought about closing the page if I hit the paywall, same as NYT.
For the New York Times the f9/reading mode works for bypass.
Just switch to private browsing, that will get rid op the Medium cookies which do the counting.
APIs are nice but far too often larger site APIs are obfuscated using JavaScript to prevent scraping. You can deobfuscate the code of just straight up evaluate the JavaScript, depending on how much time you want to spend on it.
Selenium / webdriver / chromedriver and python are pretty awesome as a last resort. Basically, you’re puppeting a full browser instance, so it can do anything a browser would do, including executing all the javascript and passing over whatever tokens/cookies.
For simple stuff, it’s overkill and ungainly. But when they really make you bring out the big guns…
You can do the same with your favorite .net language (Scraper = new Internetexplorer.application(myURL) IIRC).
One method that handles most every application is KISS, even when it’s a huge mess under the hood!
I disagree about ‘overkill’.
Robots.txt shmobots.txt
I miss Scrapbook for Firefox. It was a powerful and useful too killed by Mozilla’s change machine. Still, IMO , no suitable replacement exits.
CPanel zone editor is a good case in point. My workplace wanted to move from one DNS provider (who used CPanel), to Amazon Route53 managed with Terraform.
Opened the zone editor, opened developer tools, reloaded the page, saw a big JSON ball with the entire DNS zone in it. R8ght-click, copy response, save in file; then a colleague bashed up a Python script to generate the initial Terraform code.
I miss the so called “web 1.0”.
What we got in the last two decades was such an utter metter, imho.
All these scripting languages and modern design languages caused nothing, but waste, imho.
A simplistic, lifeless website with a white background used to be 1KB in size (plain HTML “code”), now it’s 10MB or more. Thank you, PHP, CSS and JavaScript.
PS: I often hear how CSS and JavaScript make things so much better and help to separate content from design..
But what happened to respect for people with disabilities? All the talk about diversity, but no one seems to care for the people that really could need help.
Plain HTML pages could be read to someone by a voice synthesizer. Or could be read with a Braille bar. That even worked with frame sites.