
In the early 1990s I was privileged enough to be immersed in the world of technology during the exciting period that gave birth to the World Wide Web, and I can honestly say I managed to completely miss those first stirrings of the information revolution in favour of CD-ROMs, a piece of technology which definitely didn’t have a future. I’ve written in the past about that experience and what it taught me about confusing the medium with the message, but today I’m returning to that period in search of something else. How can we regain some of the things that made that early Web good?
We All Know What’s Wrong With The Web…
It’s likely most Hackaday readers could recite a list of problems with the web as it exists here in 2024. Cory Doctrow coined a word for it, enshitification, referring to the shift of web users from being the consumers of online services to the product of those services, squeezed by a few Internet monopolies. A few massive corporations control so much of our online experience from the server to the browser, to the extent that for so many people there is very little the touch outside those confines.
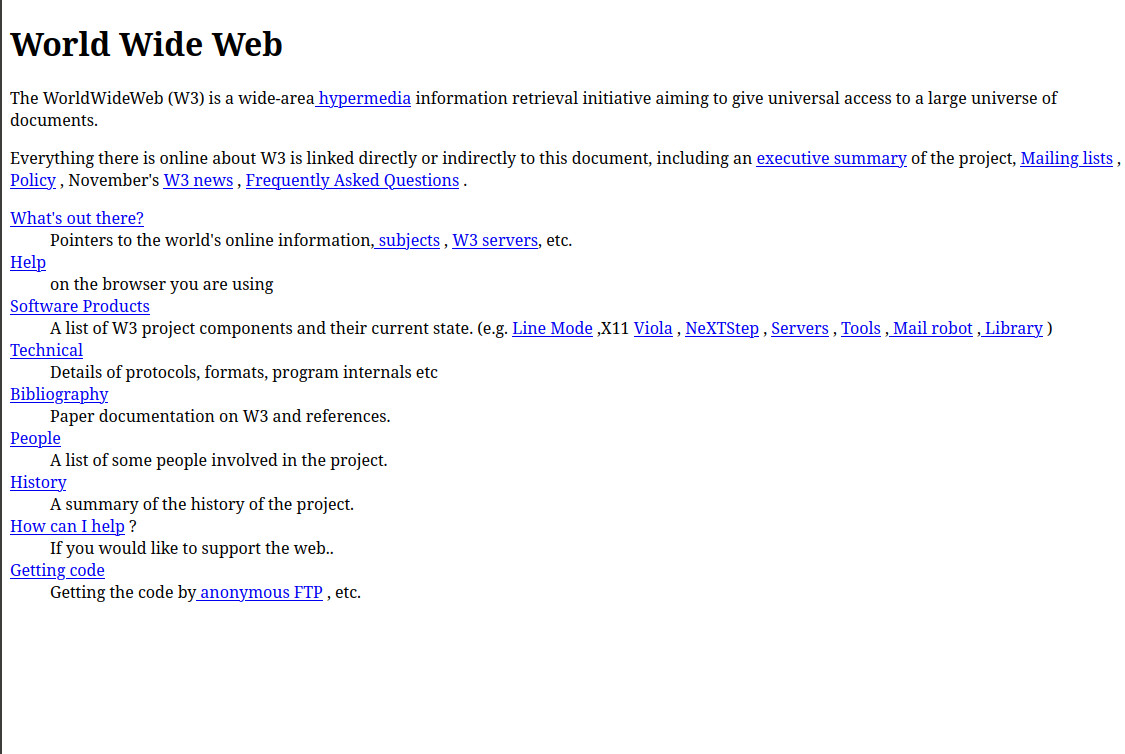
Contrasting the enshitified web of 2024 with the early web, it’s not difficult to see how some of the promise was lost. Perhaps not the web of Tim Berners-Lee and his NeXT cube, but the one of a few years later, when Netscape was the new kid on the block to pair with your Trumpet Winsock. CD-ROMs were about to crash and burn, and I was learning how to create simple HTML pages.
The promise then was of a decentralised information network in which we would all have our own websites, or homepages as the language of the time put it, on our own servers. Microsoft even gave their users the tools to do this with Windows, in that the least technical of users could put a Frontpage Express web site on their Personal Web Server instance. This promise seems fanciful to modern ears, as fanciful perhaps as keeping the overall size of each individual page under 50k, but at the time it seemed possible.
With such promise then, just how did we end up here? I’m sure many of you will chip in in the comments with your own takes, but of course, setting up and maintaining a web server is either hard, or costly. Anyone foolish enough to point their Windows Personal Web Server directly at the Internet would find their machine compromised by script kiddies, and having your own “proper” hosting took money and expertise. Free stuff always wins online, so in those early days it was the likes of Geocities or Angelfire which drew the non-technical crowds. It’s hardly surprising that this trend continued into the early days of social media, starting the inevitable slide into today’s scene described above.
…So Here’s How To Fix It
If there’s a ray of hope in this wilderness then, it comes in the shape of the Small Web. This is a movement in reaction to a Facebook or Google internet, an attempt to return to that mid-1990s dream of a web of lightweight self-hosted sites. It’s a term which encompases both lightweight use of traditional web tehnologies and some new ones designed more specifically to deliver lightweight services, and it’s fair to say that while it’s not going to displace those corporations any time soon it does hold the interesting prospect of providing an alternative. From a Hackaday perspective we see Small Web technologies as ideal for serving and consuming through microcontroller-based devices, for instance, such as event badges. Why shouldn’t a hacker camp badge have a Gemini client which picks up the camp schedule, for example? Because the Small Web is something of a broad term, this is the first part of a short series providing an introduction to the topic. We’ve set out here what it is and where it comes from, so it’s now time to take a look at some of those 1990s beginnings in the form of Gopher, before looking at what some might call its spiritual successors today.
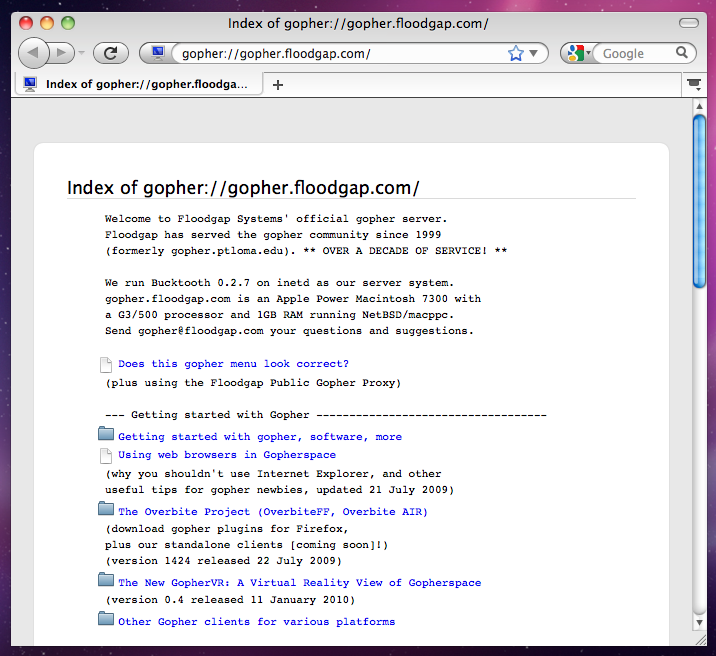
It’s odd to return to Gopher after three decades, as it’s one of those protocols which was for most of us immediately lost as the Web gained traction. Particulrly as at the time I associated Gopher with CLI base clients and the Web with the then-new NCSA Mosaic, I’d retained that view somehow. It’s interesting then to come back and look at how the first generation of web browsers rendered Gopher sites, and see that they did a reasonable job of making them look a lot like the more texty web sites of the day. In another universe perhaps Gopher would have evolved further to something more like the web, but instead it remains an ossifed glimpse of 1992 even if there are still a surprising number of active Gopher servers still to be found. There’s a re-imagined version of the Veronica search engine, and some fun can be had browsing this backwater.
With the benefit of a few decades of the Web it’s immediately clear that while Gopher is very fast indeed in the days of 64-bit desktops and gigabit fibre, the limitations of what it can do are rather obvious. We’re used to consuming information as pages instead of as files, and it just doesn’t meet those expectations. Happily though Gopher never made those modifications, there’s something like what it might have become in Gemini. This is a lightweight protocol like Gopher, but with a page format that allows hyperlinking. Intentionally it’s not simply trying to re-implement the web and HTML, instead it’s trying to preserve the simplicity while giving users the hyperlinking that makes the web so useful.
The great thing about Gemini is that it’s easy to try. The Gemini protocol website has a list of known clients, but if even that’s too much, find a Gemini to HTTP proxy (I’m not linking to one, to avoid swamping someone’s low traffic web server). I was soon up and running, and exploring the world of Gemini sites. Hackaday don’t have a presence there… yet.
We’ve become so used to web pages taking a visible time to load, that the lightning-fast response of Gemini is a bit of a shock at first. It’s normal for a web page to contain many megabytes of images, Javascript, CSS, and other resources, so what is in effect the Web stripped down to only the information is unexpected. The pages are only a few K in size and load in effect, instantaneously. This may not be how the Web should be, but it’s certainly how fast and efficient hypertext information should be.
This has been part 1 of a series on the Small Web, in looking at the history and the Gemini protocol from a user perspective we know we’ve only scratched the surface of the topic. Next time we’ll be looking at how to create a Gemini site of your own, through learning it ourselves.














Maybe it’s because I’m from Europe, but I did enjoy the days of Windows 3.1, System 7 and Amigas.
I’ve bought shareware CD-ROMs, was fascinated by Kodak Photo CDs, Video CDs and “early” online services and BBSes.
My friends and me had carried either pagers, early cellphones or wireless phones (did work in neighborhood).
We had consoles like Meg Drive, SNES or the venerable old NES.
At the time, we were happy the way things were. We didn’t need internet.
Universities had access to internet and e-mail, but also access to X.25 networks.
That’s what ATMs and other online devices had used, not the internet.
There was ISDN which natively carried X.25 connections, too.
Ordinary citizen could send e-mail via online services of the day or use messages within national services (Minitel, BTX etc).
CompuServe was an internationally known e-mail provider, for example.
In readme files of programs of the 80s and early 90s you would often find e-mail contact information for CompuServe or Fidonet.
Stop using javascript and internet gets better.
The problem with the internet is that it’s a paradox.
It wants to be free and independant, but in practice it took away all diversity.
Back in the 90s, we had a dozen of independant online services scattered around the globe.
The internet was just one network among other networks.
It’s great strenght was to interconnect different parts of networks, it did build a bridge.
Nowadays, the internet as consumed all the old networks and became a monolitic monstrosity.
There’s little experimentation going on anymore in comparison to the early internet/www of the late 20th century.
And the biggest downside is that we made ourself fully dependant to the internet. We didn’t think of alternatives. Even the landlines are gone.
If we only had kept alive the individual, closed platforms such as the old national online services (Minitel, BTX) or private online services (CompuServe, AOL, Prodigy etc). Or the X.25 various bigger networks.
I was wondering the other day if people who have physical access to unused fiber optic lines (often a lot of spares are included with each cable) have set up their own point to point links or even hubs.
I used to have that kind of physical access, but didn’t do anything about it. For it to work, I would’ve needed to know someone with similar access at the other end – which I didn’t. But I’m sure it is going on somewhere by now.
There should be a movement to encourage everyone in those positions to simply hook up all dark fiber to an old switch, and a cheap simple server that hosts a landing page describing the network, what’s its for, etc, for anyone who connected to it unknowingly. The server would also act as a means to chat with whoever down the line. The goal would be to have a parallel network that is not connected to the internet. It could be like the internet of old, only a few hundred nodes would be needed to cover the US broadly speaking, no? The network wouldn’t have to be terribly complex. Might be strategically useful in the event of a cyberattack as well.
Hi, other Joshua! Interesting ideas! 🙂
Didn’t you think to hook a spare fibre up to a VOIP ATA and then scream hello to see if you got a reply from the other end?
Other than all the sites that are entirely broken for its lack, sometimes for good reason. Though that is the most annoying bit to me, so many places are so full of it when there is no need to be.
All that JS and bloat to make actually getting the data you wanted a near Herculean task of scrolling through the pretty marketing pictures and bull crap advertising slogans looking for link to the detail you wanted – I went to your website to find out which RAM slots went with which channel, or some other technical detail, likely of a product I already bought, often enough of a product you are not even selling anymore! And yet you can’t just have a plain and simple user manual, bios updater etc to download…
And on the occasions when I haven’t yet bought the product as I was looking for the useful information, often these days with USB-C on how fast it is and which alt modes are actually supported I don’t need to see a load of art shots of the darn product before you will let me see the tech spec!
For instance I was loading my Sister’s new phone that initially seemed quite nice with some media files and noticed it was really really slow at file transfers for a brand new phone. Took a very long time looking through their BS filled webpage to entirely fail to find out if the phone really is just USB1 or 2 with a USB-C port, or if the cable or perhaps onboard flash was the problem.. So now rather than thinking about getting one as it seemed nice I shall just keep my 10+ year old junker that I barely use going a bit longer.
U-block does a great job to ‘clean’ pages. I am always surprised when I come back to a site I know from a non-u-block browser: I check if I am really on the site I wanted to connect to.
Indeed, but when the page entirely fails to function while the script blockers or advert blockers are functional, which is depressingly common, especially for the script blocker… Sometimes that is at least justifiable as doing everything that webpage is supposed to do would be next to impossible with static HTML etc, but when it is just the ‘support’ page for a motherboard/phone/etc…
… and then you get a glimpse of the information you want, only to have the cookies pop-up obliterate it, which wastes even more time rejecting unwanted cookies. Perhaps I should always accept them, and then corrupt them immediately.
heh when i think ‘enshitification’ my mind goes to jquery before it goes to the productization of customers. websites take so long to load and have such an enormous diversity of failures. is it cookies or did something cache a transient dns failure in one of the 10 cross-site scripting vulnerability references? i can’t typecross-site scripting without typing vulnerability. i had to go back and insert “without typing” in the middle of the completed phrase. and yet that’s how all the top websites waste seconds of time loading.
the thing about all these trends is they’re only add-ons. we didn’t go from a web 1.0 where every bank had a good slim website to a web 3.0 where every bank has a cross-site scripting vulnerability for a login page. instead, we went from not having online banks to having…what we have. if you want to go back to the 1990s you can — you just have to visit a bank in the flesh (i visited one just 2 hours ago, and then i got home and logged into both of their two websites and received an email from them). the web of the 1990s featured a very small number of html/1.0 webpages hosted by individuals, and i daresay if you look today, you will find a larger number of those than you could 30 years ago (well, does mine qualify? i use html 1.0 in the body but css in the head).
it’s not that there’s no longer good stuff. it’s that the bad stuff has grown. but the good stuff really is still there, and flourishing. you wouldn’t want to limit yourself to it, but you would certainly notice if it went away. or anyways, i would.
so anyways my point is i think artificially limiting yourself or sequestering yourself is pointless. the point of the web is that we can hyperlink between these disparate resources. i wouldn’t want to wall myself off from that any more than i’d want to load 10MB of javascript just to compensate for not properly learning css. if you want to be good, just be good. with the masses.
This!
No need to separate yourself from all the regular users by using some obscure protocol.
HTML and CSS work just as they did more than 20 years ago. Cancel a few of those stupid subscriptions and you have enough money for a very beefy hosted server.
Decide if you want to take the comfortable route or go full server admin — or upgrade along the way.
The choice is yours.
Hear, hear! HTML still works, it’s fast, and it looks nice with just a sprinkle of CSS. My friends and I run a static blog on Github pages. It loads in under 1 second. Actually the articles take 1.2sec because of Disqus JS.
Static hosting is so low-resource that it’s FREE as in beer. The phrase “indie web” is gaining traction and it mostly refers to this kind of website. The often-free, usually-static, very personal websites. Some are projects, blogs, or super customized journals. In a sea of corporate crap, churn-out SEO websites, and now AI drivel, these hand-made websites feel sincere.
They are sincere
Greg A and El Gru are spot on. The old means of making information available to users work fine. Altruists can serve the data with minimal effort and secure it with moderate effort. But they will get no help in reaching wide audiences without a way to monetize it.
Big Tech controls access to the uninitiated.
Consider a samisdat model.
“but of course, setting up and maintaining a web server is either hard, or costly.”
That is the reason I didn’t set up a web server, I didn’t want to run my PC 24/7 because of the cost of electricity and the cost of data to/from an Internet provider. And around that time the attacks on insufficiently protected machines were increasing.
I moved my hosted-on-expensive-commercial-server-since-1996 webpages over to github recently. If you’re writing HTML like it’s 1998, with small mostly text-based pages, it seems to do a reasonable job at zero cost with great uptime. I have a couple dozen pages about how to do foundrywork in your back yard and lost-PLA casting, and they’re mostly text with just a few pictures, and people have consistently found them useful, based on email I’ve gotten.
Thanks!
And please post your github link if you are so inclined!
Link please! I’m just setting up my back yard foundry!
There’s also neocities, which tries to recreate that 90s, 2000s experience.
https://neocities.org/
What’s the catch?
At university, in 1997 I believe, we got hold of an old PC from the college, and we (well, not me for this part) installed a very early version of Apache on it, and gave access to anyone who wanted to put up some webpages. I forget the specifications, I think it was a 386 with 32MB RAM, but it might have been a Pentium – but given that the university email system was exim+pine via telnet at the time …
The important thing was that the college had a fairly new 10mbit ethernet network that it was allowed to be hooked up to and run all the time.
And all the webpages were informational, and adverts were a secondary concern. It’s so enshittified today :(
I have been poking around the same corners of the infoverse lately. My interest has been trying to keep perfectly functional tech (ancient iPad and 32 bit netbook) usable. Javascript laden sites and manufacturer’s policy of discontinuing OS upgrades, with the attendant inability to install updated software is the chief impediment. Lynx doesn’t cut it and other TUI’s (text user interfaces) are anemic. I will have to look into Gemini to see if it fills the bill. A wiki mark-up Lynx mashup may be the answer.
Pi home servers are OK if there is a public DNS that updates automatically when your non-leased IP changes. Folks with popular info-sites would probably have to get a fixed IP and heftier hardware.
“and manufacturer’s policy of discontinuing OS upgrades”
This!
I am aware that some of my old Android tablets and phones may not have the “horsepower” to run the latest Android version. But it seems usable versions are “end of lifed” just as they become mature.
32-Bit is dead and for good reason.
https://hackaday.com/2021/06/06/is-32-bits-really-dead/
The capacity of both address ranges and storage media used in daily life has exceeded 4GB.
32-Bit, 16-Bit and 8-Bit now are home computer territory.
Still good for the hobbyists and microcontrollers though (weather stations, washing machines etc).
heh when 64 bit pointers were still a novelty i was aware of how, if you aren’t referencing a lot of data, they really do waste an absurd amount of memory just storing the pointers. in some data structures, it doubles the size, with every other 32-bit word being 00000000. so wasteful.
thank goodness, then, that by the time 64 bit pointers were foisted on me as a daily occurrence, ram was an effectively unlimited resource! :)
It’s still better than the alternative, using PAE and the 36-bit extension of Pentium Pro.
In the past years, 32-Bit OSes were getting as much of a limiting factor as 16-Bit MS-DOS on a Pentium.
Yes, you could use EMS, XMS and DOS Extenders supporting ACPI and DPMI. And it was fun to use them.
But once you had hit serious applications, such as SQL databases and networking OSes (Novell Netware etc) all these hacks started to become a headache.
And that’s what we have now with web browsers.
They’ve become so large and memory hungry that a 32-Bit OS nolonger is practical.
Even if it’s, say, a Windows 200X Server with PAE kernal support.
It’s nolonger good enough in terms of capabilities. It also has issues with large storage media. 2TB for MBR based HDDs is limit, I think.
Just like MS-DOS 6.2x with FAT16 support is being limited to 2GB partitions and a 8GB maximum capacity.
That’s equally limiting, so many DOS fans use DOS 7.1 instead.
32-Bit user mode applications can still be run on 64-Bit OSes, with the advantage that they now have most of an 4GB address space for their own.
It’s just 32-Bit hardware and OS software that’s primarily obsolete.
PS: It’s possible to store pointers in compressed form, I think.
And registers in 64-Bit processors are always natively 64-Bit wide. There’s no wasting per se happening, it’s not depending on the pointer width used by applications.
That being said, I agree that bitness used to have an effect on performance somehow.
16-Bit applications written for Windows 3.1 often used to be much smaller and quicker than those 32-Bit applications written for Windows 9x.
But maybe that’s a generational thing, also.
48bit computing would have been nice…
2x24bit or 3x16bit… good for audio and graphics… and smaller code.
” if there is a public DNS that updates automatically when your non-leased IP changes.”
I’m yet to try cloudflare tunnels, it seems like a good alternative so we don’t need dynamic dns, or the good will of ISP giving a static IP, and the added “”””security””” bonus of not having to open up a port in your router.
You should have noted the late Cheshire Catalyst, AKA Robert Osband, who was an advocate of the spare and effective use of bandwidth.
For decades…
https://archive.org/details/HOPE-2-Low_Bandwidth_Access
Well, if there was any site that would naturally fit there, I’d imagine Hackaday would be a prime example. Do it! :)
Not a “presence” per se, but Hackaday did (does?) some time ago have a site for 8-bitters to access.
http://retro.hackaday.com/
Unfortunately / fortunately, it seems to be broken, and honestly I don’t even know what generates the pages anymore. :)
In addition to Gemini could you look at Pubnix and Tilde servers? SDF as well as the contents of tildeverse? SDF is special in that it actually pre-dates the internet as it went live in 1989. These servers often have a host of services byond just gopher/gemini/html hosting. They will often have internal forums, mail servers, and there’s even a tilde-wide NNTP service.
It’s quite facinating to look at, and honestly? I’m glad HaD is covering the Smol Web as I think I speak for us all.
The web as it is? 90% of it is bot traffic and is only getting more bot infested with LLMs generating content.
About 2003 I was involved with building wiki’s for engineering use. Everyone could have their own wiki, but we built an interlink mechanism so you could say //astro/WikiPageName and it would go, find the “astro” wiki in a master directory and cross link to it. It made it much easier to share information around than doing full site names or ipaddresses.
Lots of engineers would leave the edit access open on public pages, so you could edit the page, do updates and have it saved.
Where we were ahead of the game is the //astro/WikiPageName could get updated with a redirect to //rosie/WikiPageName. If the caller hit one, it would go back to the calling page and update it with the new location. This allowed people to push pages to a central server and kept dead links from becoming an issue.
Oh, careful with SDF, we might suck you into the Plan9 rabbit hole… perfect OS for Gemini and ad-hoc networking.
I’m not part of SDF. It feels… Spicey. I hover around Ctrl-c and the tildeverse.
SDF is a relic of a bygone age. I both want to find more people and am afraid it will become a parody of itself.
I think we’ve also lost track of the fact that originally, the internet at its core, was a source of information…like a library (this is where I expected the internet to go in the late 80’s). At the moment, only the last vestiges of the “information source” is still there, and dying faster by the day. Getting to that information is almost impossible without going through a “filtered” search engine. This is where I think Gopher shined. I still miss the old girl…
That is also where I expected it to go also…. A library of technical information at your fingertips… Not for banking/infotainment/social stuff/google search/inference. If certainly wouldn’t need the ‘bandwith’ if you could eliminate the social/entertainment side of things that plug up the information highway….
That’s how it was here in Germany. Internet was the domain of universities.
Commercial users used Datex-P, citizens used Datex-J (aka BTX or T-Online).
The later was also used for shopping and for doing home-banking.
The banking-software could even disconnect from BTX and then do establish a direct connection to your bank.
That’s because BTX mainframes supported external databases.
In early 90s, our national telco Deutsche Telekom AG had envisioned an infrastructure based on ISDN, to provide FAX, Datex-P, telephony and video telephony services.
It was completely unrelated to the internet. The internet wasn’t a thing until 1996, when the T-Online software 1.02 had offered an additional internet gateway and shipped with Netscape 2.01.
The software ran on MS Windows 3.1/95 and System 7.
So yeah, the internet wasn’t mandatory in our little world here.
The closest thing the US had was AOL, I think. Like CompuServe, it had its own databases and resources, not based in internet technology.
It was connected to internet, of course, just like CompuServe and T-Online. But also independant like them.
This is something people tend to forget nowadays. Or maybe they’re too young.
Anyway, I think it’s important to keep these little details in collective memory.
The young internet was historically relevant for sure, but it didn’t came out of nowhere, either.
There had been older technologies predating it, and not just Arpanet.
To elaborate a little bit more, we did have ISPs early on.
1und1 provided an internet access in 1994, or so.
And CompuServe was an internationally known service, but it didn’t have logins in Germany and other places in Europe.
So users had to make a connection to the USA, somehow.
Here in Germany, we used other online services (Datex-P and J, for example) to connect to the US mainframes.
CompuServe was more like an online database, a big BBS. Tech companies like Microsoft or Apple had their support forums at CompuServe.
It was also possible to retrieve weather information, driversm updates and other things vis CompuServe.
It was an international meeting point in computing, sort of. That made it so special.
AOL in Germany and other European countries never had this status, I think.
AOL, especially in the US, got popular when it had gotten internet-centric already.
Wheras CompuServe’s star began to sink with advent of public internet and www.
It had been relevant in 80s and early 90s. AOL didn’t exist in the 80s yet.
That’s when Promenade, Quantum Link and so on were around.
https://technologizer.com/2010/05/24/aol-anniversary/index.html
CompuServe and AOL provided Internet access back then?
I thought they were just their own proprietery networks that only connected to themselves until the late 90s when Computserve died and AOL added Internet access in a bid to extend it’s life.
At least in the US anyway. I assumed the same company was the same network in other countries though.
”
CompuServe and AOL provided Internet access back then?
I thought they were just their own proprietery networks that only connected to themselves until the late 90s when Computserve died and AOL added Internet access in a bid to extend it’s life.
At least in the US anyway. I assumed the same company was the same network in other countries though.”
Yes, CompuServe did by 1996, at least. Maybe earlier also, say 1994, 1995?
Some versions of WinCIM (v2.xx ?) included Internet Explorer 3, I remember.
That’s what CD-ROMs of Pearl Agency often had been bundled with, I vaguely remember.
I remember it because I had once installed it on a 486 laptop running Windows 3.10.
Pearl Agency was (a mail order company with paper catalogs that sold all sorts of computery stuff and multimedia gadgets.
It’s now renamed Pearl for 25 years, I think.
Mosaic browser might have been included in some earlier versions of WinCIM, also, I think. But not all.
But Mosaic was outdated by 1995/1996 already, so I didn’t test it (with CompuServe).
AOL was a bit late over here, it arrived in the Windows 95 days.
So I can’t really say at which point it had begun to provide internet access.
It surely was around in second-half of the 1990s, though.
Correction. We didn’t have CompuServe logins in Germany and other countries initially.
A few years past 1990 we got our regional CompuServe logins (modem “ports”?) in our countries over here, I think.
So we did nolonger have to use gateways from other networks, or -yikes- call an dial-up login directly in the US.
Because phone calls to overseas was very expensive back then.
Agreed. I certainly don’t mind the other aspects and applications sharing the same network, but balance have been lost. As a start, the internet should have been a repository of human knowledge. Search engines also served an important function here in the early days, but have since become tools of narrative, so…pointless.
Here in South Africa libraries are closing faster than the government can “reallocate” money, and the internet could have been a viable replacement (which was gov “justification”). Currently, we are a bit screwed as far as knowledge go (paper format or otherwise).
“Anyone foolish enough to point their Windows Personal Web Server directly at the Internet would find their machine compromised by script kiddies, and having your own “proper” hosting took money and expertise. ”
Ok… Where to begin…
Windows Personal Web Server? Probably not a good idea.
Windows anything directly exposed.. probably not good.
I’ve had Apache running since about 1998. (with many upgrades of course) Since.. I don’t know, 1999 maybe this has not be on a machine that was directly connected to the internet itself but rather is on the LAN with ports 80 and 443 forwarded.
I don’t consider myself to be any sort of network or server admin professional.
I have NEVER experienced anything bad from this.
I repeat, I have NEVER had a problem. Yah, sure, anecdotal experience is only worth so much by we are talking about 25 years of it! I bet many of the people arguing that this is unsafe weren’t even born yet when I began.
The only thing I have experienced was about a billion (fortunately failed) attempts to log into my ssh service. There are a few tips I think anyone exposing SSH should know but… we were talking about a web server, not SSH.
I see other commenters mentioning electricity use… Well. a Raspberry Pi or other SBC is more than enough for one H3ll of a personal site. Even a current sipping Pi Zero would take care of most people’s needs there. I used old PCs as my server back in my bad old days of irresponsible electric use but an SBC has done the job for probably over a decade now. I don’t remember when actually.
Ok.. maybe what I am describing is beyond the abilities of the average internet user? (Probably well under the abilities of the average HaD reader right?) But really… how hard can it be even if one is stuck with Windows? If we are talking about a static page then just a simple basic web server app running that only looks in a specific folder where you put your site and nothing else. Then just port 80 forwarded to the machine that runs it. This is not rocket science.
I suppose.. if you want to get more interactive… if you are going to run some sort of local cgi… then you are going to either have to know your scripts are all safe or you are going to need a sandbox. But we have already gone way past the “small web” described here at that point haven’t we?
Then there are the various appliances that started to pop up which acted as personal web servers. It was getting easier!
I don’t think there is any technical reason that self-serving faded away but rather just the fact that most “normal people” really just wanted the mindless drivel that social media makes so easy and the drive was lost.
From my experience, for most people, setting up port forwarding might as well be rocket science.
That’s my experience too. But… I would add that those same “most people” aren’t likely to discover Gemini or Gopher any time soon. Among the outliers… I expect a lot of overlap.
Now and then I get interested in Gemini and Gopher, toy with it a bit and then put it back down for a while.
I love simple protocols. The HTTP spec… so big, so heavy!
How much bandwidth and energy are wasted with all those headers that convey nothing that the end user will see? How much CO2 does that produce?
A protocol simple enough to understand should be a lot easier to implement securely too.
But there is no real way to submit a form to Gopher (or I think Gemini). That’s just a little bit too simple I think. (I suppose one could get very hacky with the search submit feature but… no.)
Totally OT.
I read this on a tablet, and scrolls with my left index finger.
Several times I accidently hit the “Report comment” field.
I apolygize for that, but maybe it would be a reeeeally smart idea if HAD had an accept button before posting the reporting!
I reported your comment.
I was under the impression that Hackaday DID pop up a confirmation box, and I was going to confirm that it did.
But, I was wrong.
I really didn’t mean to send you to Hell!
I don’t understand why Gemini needs its own format, when Markdown already existed and has a similar feature set, with more flexibility in creating hyperlinks. IMO it needs to catch on to use markdown for the small web. Download it and render it directly, don’t convert it to HTML first. The limited feature set makes a lot of kinds of misuse impossible. I think I found a while back that one or two gemini clients can handle markdown already.
Now of course it’s hard to google for anything about gemini… that’s a new problem.
And yeah, we need some new search engines.
We also need content addressing: fetch a page from a p2p network by its hash, or by some other guaranteed-unique ID, rather than by connecting to a particular server. It’s inevitable that servers go down, and we don’t want links breaking anymore, do we? Gemini has not solved this. IPFS solved it, but it’s a bit of a pig. There’s no reason the IPFS ideas can’t be implemented in a more lightweight way. I want to see a tray application for Windows users (since they are still in the majority): to view the small web, you need it running; and you are encouraged to keep it running. Everything you have looked at will be cached for a while and shared with anyone who’s looking for the same content. And you can serve up your own “home pages” and blogs too: no need for hosting in a data center. It doesn’t have to runt 24×7, because other people are caching what you publish. Of course written in a good portable compilable language (go or rust) and also available as a proper daemon on Linux and such.
500MB.mp4 as a background image?
11 different scripts with explicit 5 second wait times that either return data to a server or have to time out before the server begrudgingly sends the information to you?
Pages refusing to load the primary elements until the ad auction completes and those elements are enroute?
The Internet is shit now because the content on the page has the lowest (or no) priority anymore.
We don’t need to return to a single black on white font, but it should not be taking 45 seconds to finish loading a page in 2024.
It used to be that your browser could request an almost pure text “mobile” page from a web server, but those went away when smart phones got common enough that “mobile” just became “portrait layout”.
Yeah I used to do this, use the WAP sites. I think possibly you still can, if you declare your browser to be running on something old, it cuts down the cruft.
Aral Balkan makes a really good case for the small web, IIRC. He says that each part of the globe – the cities and countries – should have a small web of its own, where people interact and find common interests. I think searching for his Mastodon account is a good start.
This point is key.
Anyone can provide info for free via the web easily.
Search engines and ISPs have no incentive to help users to find that info without the ability to monetize the search.
There is little reason to think that accessible free info is true without some validation / curation by some authoritative body – that probably has financial incentives.
Basically you can post it but I probably can’t find it or trust it unless we have an existing relationship.
Reminds me of this excellent presentation from a while back:
https://idlewords.com/talks/website_obesity.htm
Honourable mention to https://512kb.club/ as well as https://1mb.club/ and https://250kb.club/
This idea doesn’t seem to address the stated problem, unless I really misunderstood the problem, which is quite possible. We have sites like Facebook where almost anyone can share what they have to say, but it is tricky to retrieve it on Facebook itself and nearly impossible from outside. And we have sites that have managed to manipulate search engines enough to drown out good content with ads and search engine optimized spam.
This seems like its most likely result, at least in the short term, is to create another walled garden of its own, only one walled off by obscurity. If you want a way where anyone can say what they have to say and find an audience, this isn’t it.
I don’t mind a smaller web from the old days, just NOT the font of the old days…
My CV was written in html, initially by hand, but later I got lazy and use word.
There was an intermediate time when ISP’s would give you a bit of web space and you could put html pages on there. So I had my CV to advertise my contracting capabilities.
These days people have their smartphones on 24/7. I expect you could easily host “small web” content from them. The main difficulty being hostname resolution to an IP address and port redirection.