
[Ken Shirriff] has been sharing a really low-level look at Intel’s Pentium (1993) processor. The Pentium’s architecture was highly innovative in many ways, and one of [Ken]’s most recent discoveries is that it contains a complex circuit — containing around 9,000 transistors — whose sole purpose is to multiply specifically by three. Why does such an apparently simple operation require such a complex circuit? And why this particular operation, and not something else?
Let’s back up a little to put this all into context. One of the feathers in the Pentium’s cap was its Floating Point Unit (FPU) which was capable of much faster floating point operations than any of its predecessors. [Ken] dove into reverse-engineering the FPU earlier this year and a close-up look at the Pentium’s silicon die shows that the FPU occupies a significant chunk of it. Of the FPU, nearly half is dedicated to performing multiplications and a comparatively small but quite significant section of that is specifically for multiplying a number by three. [Ken] calls it the x3 circuit.
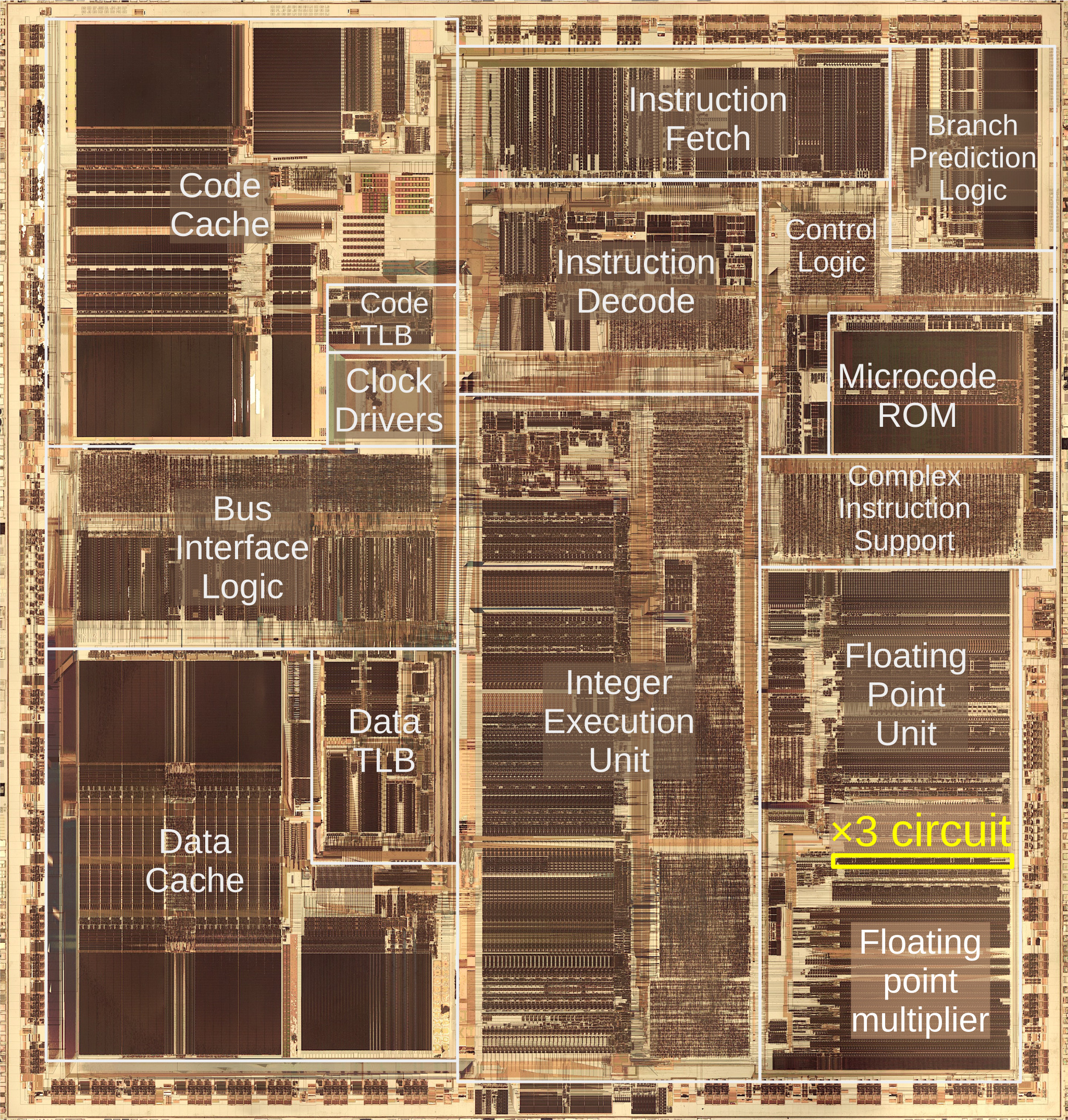
Why does the multiplier section of the FPU in the Pentium processor have such specialized (and complex) functionality for such an apparently simple operation? It comes down to how the Pentium multiplies numbers.
Multiplying two 64-bit numbers is done in base-8 (octal), which ultimately requires fewer operations than doing so in base-2 (binary). Instead of handling each bit separately (as in binary multiplication), three bits of the multiplier get handled at a time, requiring fewer shifts and additions overall. But the downside is that multiplying by three must be handled as a special case.
[Ken] gives an excellent explanation of exactly how all that works (which is also an explanation of the radix-8 Booth’s algorithm) but it boils down to this: there are numerous shortcuts for multiplying numbers (multiplying by two is the same as shifting left by 1 bit, for example) but multiplying by three is the only one that doesn’t have a tidy shortcut. In addition, because the result of multiplying by three is involved in numerous other shortcuts (x5 is really x8 minus x3 for example) it must also be done very quickly to avoid dragging down those other operations. Straightforward binary multiplication is too slow. Hence the reason for giving it so much dedicated attention.
[Ken] goes into considerable detail on how exactly this is done, and it involves carry lookaheads as a key element to saving time. He also points out that this specific piece of functionality used more transistors than an entire Z80 microprocessor. And if that is not a wild enough idea for you, then how about the fact that the Z80 has a new OS available?














If they reduced the silicon to just 2x + x, decoupled the circuit from the clock for the carry to ripple on its own, and with extra bit(s) set to always carry to a READY line, would that work just as well?
The original article explains that the whole reason for the complicated x3 circuit is that ripple carry would be too slow.
Kind of surprised to never have heard of anyone optimizing multiply and divide by ten or even just supporting them as machine instructions. Think of how often you need to deal with human readable numbers – and every last digit you encounter incurs at least one x10 or /10 depending which way it’s going. Idk, maybe in the grand scheme of things this is less than 1% of what a CPU spends its time doing. Otoh, certain logging operations famously went to writing binary files for speed reasons.
Multiply by 10 is super easy because 10x=8x+2x. So x10=(x<<3)+(x<<1). In quasi assembly, you can do even better:
; A x 10SAL ; shift left (x2)
STA tmp ; tmp=A
SAL ; *4
SAL ; *8
ADD tmp ; A=A+tmp = 8x+2x = 10x!
Divide by 10 isn’t as easy
In practive:
; Input X in EAX
SHL EAX, 1 ; EAX=X2
LEA EAX, [EAX4+EAX] ; EAX=X8+X2
Multiplying with 3 would be:
; Input X in EAX
LEA EAX, [EAX2+EAX] ; EAX=X2+X
I would guess that multiplying by 10 is not particularly frequent. It’s true that us humans might do it often, so once every few seconds the cpu might have to respond to a human input that asks for a 10x multiplication. But something that happens every few seconds is essentially negligible to a CPU doing millions of ops per second.
The cpu spends orders of magnitude more time catering to our fetish for rounded window corners than it spends catering to our base 10 fetish.
https://folklore.org/Round_Rects_Are_Everywhere.html
Happens alot in the Linux kernel where we can’t use floating point numbers. So to get decimal precision you just cheat
If I want 10.1 + 10.2 =20.3 but can’t use float you just use 101 + 102 =203 this is an over simplification but often you want to keep the decimal precision when adding or multiplying large datasets. You just x10 the numbers then /10 the answer. Sure you can x8 /8 instead. The math is quicker and only slightly less precision but let human readable. When I see 101 I can with zero effort see 10.1 in my head.
That is just basically fixed point but in base 10. Using fixed point binary numbers is very common in hardware and software when you don’t have an FPU.
When this sort of mattered for what CPUs where doing, they did not optimize binary to/from decimal conversion, but implemented BCD encoding and instructions instead, so all calculations where just done in base10
Yeah, the old 8 bit CPUs had their BCD modes. The 6502 for sure, and I think the Z80 did too. Not sure about the 6809. Did the 8086/8088 or the 68K? Now wondering what was the last CPU to support BCD?
Quickly, to the Bat~Computer!
Lots of old machines operated in base 10, so converting between human-readable numbers and internal numbers was trivial. One example is the IBM 1401 (1959), which I use regularly. Bizarrely, the IBM 1401 had hardware support for base-12 and base-20 as an option. For the UK market, you could purchase support for pounds/shillings/pence (£sd) arithmetic, back when there were 12 pence in a shilling and 20 shillings in a pound. The IBM 1401 could perform arithmetic, including multiplication and division, on pounds/shillings/pence values. This was implemented in hardware, not even microcode, but boards of transistors, so you could add two £sd number with a single instruction. Try doing that on your modern CPU!
? If Intel added sterling operations to x86, would it be anywhere near the bulkiest microcode on the die? You, of anyone, will actually know this ;-)
Because x10 pauses everything….
Computer balks: Really? You want me to do this? For you? What happened, is your decimal point seized? Did you run out of zeroes? Do you not know how much of the universe is filled with F@(#ing ZEROES? I mean, WTF?
“Multiplying two 64-bit numbers is done in base-8 (octal), which ultimately requires fewer operations than doing so in base-2 (binary).”
I’m aware I’m ignorant of the details of multiplying 64-bit numbers (I let silicon do this). But, but, does this sentence make sense? At the level of transistors comprising a digital circuit, what element can input, hold, & output an octal digit?
And, no, I haven’t read the referenced article.
/me is usually on overload after reading half of Ken stuff.
Google for “radix-8 Booth’s algorithm”. Looks like everyone and its mother has done something with that. It reads like black magic, like Shahriar Shahramian does at The Signal Path, only different. Vodoo & witchcraft, if you ask me.
Is there anything about the development process? I mean, that thing has 3.1 million transistors in 1989. Was it emulated? How?
You asked about the Pentium development process. They used several techniques for validation: black-box architecture verification, logic-level design verification, random instruction testing, and a logic-design hardware model called QuickTurn. Ironically, in view of the famous FDIV bug, they “dedicated a special effort to verify the new algorithms employed by the FPU. We developed a high-level software simulator to evaluate the intricacies of the specific add, multiply, and divide algorithms used in the design.”
See “Architecture of the Pentium Microprocessor” for details (DOI 10.1109/40.216745)
Thanks. DOI 10.1109/40.216745 is an interessting read.
It’s just the particular way original Pentium implemented multiplication of 64-bit numbers.
Most processors before it did multiplications bit-by-bit, often taking close to 64 cycles to do it. Pentium did tricks to get it down to 2 clock cycles, of which this x3 multiplier is one part.
More recent processors have more transistors available and now even cheap microcontrollers do 32×32 bit multiplication in a single clock cycle. I’m not sure how they do it internally.
“At the level of transistors comprising a digital circuit, what element can input, hold, & output an octal digit?”
Three of whatever holds a binary digit.
Saying it works in base-8 just means that if you start with a multiplicand A and a multiplier B, both of, say, 64 bits, instead of summing 64 partial-products of “A x each digit of B” you sum 22 partial products of “A x (each group of 3 digits of B)”. The reason it ends up being so much faster is that optimizing a 64 partial-product add is a nightmare compared to optimizing a 3-bit multiplier.
Using base-8 (radix-8) means that the multiplicand is processed three bits at a time rather than one bit at a time. Multiplying two 64-bit numbers in binary means that you have 64 terms to add to get the final result. Multiplying in radix-8 means that you have 22 terms to add, but the tradeoff is that it is more complicated to compute each term since you’re multiplying by 0 through 7 instead of just 0 or 1. The numbers are all represented in binary, of course, not 8 voltage levels.
Isn’t this just a hardwired 2x + x then? If not, why would 2x + x be any slower than x + x or x + y? Hardwiring 2x shouldn’t cost any time whatsoever since it’s just a bit shift.
Yes, it is just 2x + x.
The 2x is easy. The x is easy. It’s the add that’s the problem. And 3x in a radix-8 Booth multiplier is the only one that needs an add.
Booth’s algorithm doesn’t have this problem of multiply by 3. It takes only powers of 2 and add/sub to handle this issue.
It’s not a “problem”. This is a modified Booth’s algorithm for radix 8: sure, you need a multiply by 3, but it’s literally one multiplier for a big reduction in partial products.
Radix 4 is often used because it doesn’t need the x3, but it’s just a question of if the x3 multiplier is worth the cutdown in partial products.
My brother bought a Gateway pc with one of the first Pentium processors. The chips had some kind of error that was doing math wrong. He was FedEx’d a replacement processor to install before the scandal got out of hand.
The Pentium FDIV bug was quite infamous https://en.m.wikipedia.org/wiki/Pentium_FDIV_bug