In previous episodes of this long-running series looking at the world of high-quality audio, at every point we’ve stayed in the real world of physical audio hardware. From the human ear to the loudspeaker, from the DAC to measuring distortion, this is all stuff that can happen on your bench or in your Hi-Fi rack.
We’re now going for the first time to diverge from the practical world of hardware into the theoretical world of mathematics, as we consider a very contentious topic in the world of audio. We live in a world in which it is now normal for audio to have some form of digital compression applied to it, some of which has an effect on what is played back through our speakers and headphones. When a compression algorithm changes what we hear, it’s distortion in audio terms, but how much is it distorted and how do we even measure that? It’s time to dive in and play with some audio files.
How Good A Copy Does A Copy Have To Be?

Were we to record some music with a good quality microphone and analogue tape recorder, we know that what came out of the speakers at playback would be a copy of what was heard by the microphone, subject to distortion from whatever non-linearities it has encountered in the audio path. But despite that distortion, the tape recorder is doing its best to faithfully record an exact copy of what it hears. It’s the same with a compression-free digital recording; record those musicians with a DAT machine or listen to them on a CD, and you’ll get back as good a copy as those media are capable of returning.
The trouble is that uncompressed audio takes up a lot of bandwidth, particularly when streaming over the Internet. Thus just as with any other data format, it makes sense to compress it such that it takes up less space. There are plenty of compression algorithms to choose from, but with analogue sources there are more choices than there are with text, or software. A Linux ISO has to uncompress as a perfect copy of its original otherwise it won’t run, while an image or an audio file simply has to uncompress to something that looks or sounds like the original to our meaty brains.
Those extra compression options for analogue data take advantage of this; they use so-called lossy compression in that what you get out sounds just like what you put in, but isn’t the same. This difference can be viewed as distortion, and if you have ever saved an image containing text as a JPEG file, you’ll probably have seen it as artifacts around sharply defined edges.
So if lossy compression algorithms such as MP3 introduce distortion, how can we measure this? The analogue distortion analyser featured in our last installment is of little use, because the pure sine wave it uses is very easy for the compression algorithm to encode faithfully. Compression based on Fourier analysis is always going to do a good job on a single frequency. Another solution is required, and here the Internet is of little help. It’s time to set out on my own and figure out a way to measure the distortion inherent to an MP3 file.
Math Will Give Us The Right Answer!
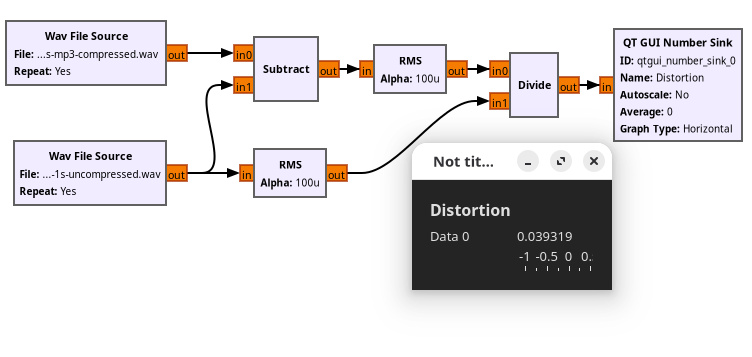
At moments like these it’s great to be surrounded by other engineers, because you can mull it over and reach a solution. This distortion can’t be measured through my analogue instrumentation with a sine wave for the reasons discussed above, so it must instead be measured on a real world sample. We came up with a plan: measure the difference between two samples, compute the RMS value for that difference, then calculate the ratio between that and the RMS of the uncompressed sample.
As is so often the case with this type of task, it’s a relatively straightforward task using GNU Radio as a DSP workshop. I created a GNU Radio project to do the job, and fed it an uncompressed and compressed version of the same sample. I used a freely available recording of some bongo drums, and to make my compressed file I encoded it as a 128kbit MP3, then decoded it back to a WAV file. You can find it in my GitHub account, should you wish to play with it yourself.
Math Will Give Us The Wrong Answer!
The result it gives for my two bongo samples varies a little around 0.03, or 3%, depending upon where you are in the sample. What that in effect means is that the MP3 encoded version is around 3% different from the uncompressed one. If that were a figure measured on an analogue circuit using my trusty HP analyser I would say it wasn’t a very good quality circuit at all, and I would definitely be able to hear the distortion when listening to the audio. The fact that I can’t hear it raises a fundamental question as to what distortion really is, and the effect it has upon listeners.
What I would understand as distortion due to non-linearities in the audio path, is in reality harmonic distortion. Harmonics of the input signal are being created; if my audio path is a guitar pedal they are harmonics I want, while if it’s merely a very low quality piece of audio gear they’re unwelcome degradation of the listening experience. This MP3 file has a measurable 3% distortion, yet I am not hearing it as such when I listen. The answer to why that is the case is that this is not harmonic distortion, instead it’s a very similar version of the same sound, which differs by only 3% from the original. People with an acute ear can hear it, but most listeners will not notice the difference.
So In Summary: This Distortion Isn’t Distortion Like The Others
So in very simple terms, I’ve measured distortion, but not distortion in the same sense of the word. I’ve proven that an MP3 encoded audio source has a significant loss of information over its uncompressed ancestor, but noted that it is nowhere near as noticable in the finished product as for example a 3% harmonic distortion would be. It’s thus safe to say that this exercise, while interesting, is a little bit pointless because it produces a misleading figure. I think I have achieved something though, by shining some light on the matter of audio compression and subsequent quality loss. In short: for most of you it won’t matter, while the rest of you are probably using a lossless algorithm such as FLAC anyway.














>be 60 years old
>finally can afford hi-fi audio gear
>can’t hear his own farts anymore
Oh the irony
A lifetime of going to gigs and listening to live music has left my ears in a similar state.
On the upside, it means I don’t have to spend much money on audio gear to get something which sounds perfect (to me).
The paradox of building a good sound setup is that most music is so poorly recorded and mixed that it just won’t sound good anymore once you can hear the difference.
Your old “lo-fi” just drags everything down to the same level, and you get used to it. Once you upgrade, you’ll be chasing that magic EQ lineup that fixes whatever compromises the audio engineers made in trying to master the recordings. You start to hear things like, oh, this singer was probably recorded in their kitchen using a laptop’s mic, and they just mangled the heck out of it to mask the echo.
And it’s different from recording to recording, so you’ll never find that optimum.
I hear this (pun intended) all the time, but wonder if it’s objectively true. My guess is that most folks in the industry are professionals and know what they are doing. While there may be a lot of material available that is self produced by people just hitting record, isn’t most of the stuff released actually well polished?
And of course, poorly recorded and sound good are super subjective concepts. I wonder how much of it is actually just folks releasing stuff that they consider sounding good, which might just be different than what others think sounds good.
Then again, they probably just don’t know what sounds good! ;)
Depends on what you mean. Studio monitor speakers for example are considered “harsh” by most because they aim to have an absolute flat frequency response and no distortions or coloration to their sound. Every sound should be heard, and their amplitudes should be comparable even if it doesn’t sound good in an aesthetic sense. If you buy studio monitor speakers because they’re “technically perfect”, you’ll be in for a disappointment.
The audio engineers have to consider what kind of sound setups the average consumers have, because if they mix the audio to sound good on studio monitors it’s going to sound completely different in your stereos or headphones. Are they mixing with streaming services in mind? Radio play? Movies and home theater?
The performing artists themselves have a say, because if the artist says “This sounds like crap, I want it this way instead of that way”, then that’s what’s going to come out. Your listening experience will be influenced by the tinnitus of a rock star who has been playing gigs for 20 years and can’t hear anymore.
Then there’s artists who insist on doing things like recording on tape because they like the way it sounds, but you don’t know that it’s supposed to sound like that, so you’ll start twiddling your knobs trying to “fix” whatever is wrong with your setup. Then you switch albums and oh no, it’s all wrong again.
Also, one of the things I’ve noticed – since so many modern speaker setups no longer have big mid-frequency drivers but instead consist of a subwoofer and a pair or two of tiny satellites, the mixing has started to emphasize the lower speech frequencies somewhere from 100-300 Hz to push that sound through regardless. That’s where the subwoofer cuts out, and the satellites don’t yet pick up properly.
So, when you listen to new recordings with proper speakers that do have plenty of power in that region, it sounds wrong, and if you turn the volume down your ears lose sensitivity in the sub-bass below 100 Hz and high frequency ranges above 1-2 kHz and the sound becomes muddled. Too much emphasis around the “movie trailer narrator” voice range. Sometimes speech, especially male voices, become unintelligible.
This is what the “loudness” button in old Hi-Fi systems was for: it changes the equalization setting to correct for different listening volumes. In modern systems there’s no such button because people don’t care or understand what it is.
The ear can be fooled if the compression is modeled to the way we hear.
I use an open-source project LAME MP3. LAME uses a sophisticated psychoacoustic model to compress music in a way your ears can barely notice, giving you superior sound quality at smaller file sizes than a lossless WAVE file. It also supports Variable Bit Rate that scales the bit rate to the complexity of the sound.
With VBR it gives a medium file size with great sound quality.
I’ve used LAME for years, the VBR is great. But having said that anything below 192kHz still makes cymbals sound like they’ve been put into a washing machine. There are so many variables in sound reproduction it’s hard to apply any single compression algorithm to it to account for the timbre of the sound. In fact there’s a Modest Mouse song I listened to for years that drove me mad because I only had it as an MP3 and the backing vocals sounded badly encoded (like a cheap sound compressor ran through a really bad 8bit compression). Turns out when I finally got a decent recording of it that’s the way it was recorded anyway.
On a side note I think exploring the compression in Bluetooth and Mini disc might be worth an article here. Minidisc did a decent job because it was essentially for headphones (and later for recording sound bytes for radio and TV up until relatively recently as far as I’m aware) but Bluetooth is here to stay (so says all the smart devices manufacturers).
“When a compression algorithm changes what we hear, it’s distortion in audio terms”
Audio compression is not a new thing. Good old grammophone records are also kind of compressed. Lower frequencies (bass) are damped which is why the sound is very thin unless you feed the audio into a RIAA preamp which apart from amplifying the weak signal also reverses the distortion introduced when making the record.
The RIAA curves are usually referred to as equalization, not compression. In audio, compression can refer to 2 different things. One is dynamic range compression, which is not the subject of this article. The other is reducing the number of bits in a stream of audio data.
I prefer to think of distortion as a signal corruption resulting from nonlinearities in the amplitude response curve. Bumps in the frequency response curve may be annoying, they don’t preserve the original signal, but to my way of thinking they’re not distortion. Similarly noise is not distortion, although a communications system engineer may consider distortion a type of noise (I don’t.)
By my definition, quantization noise is distortion because it results from the stepwise nonlinear nature of digitizing.
Distortion is when the signal energy is spreading to other frequencies for whatever reason – it changes the shape of the signal which introduces additional frequency components. Simple amplitude change does not.
So, Jenny: I see no shift operation in that GNU Radio block diagram. What happens if/when the compression algorithm delays (shifts) the signal a few sample periods, like most digital filters do? The compressed version and the uncompressed version will not be time-synced, and there will be an larger-than-real difference between the two signals. This would falsely be called “distortion”.
There should be a control to time-shift the two inputs relative to each other, to minimize the difference between the two (preferably by sub-sample-period amounts). The residual could then properly be called “distortion”.
The code for that one above is free to download and modify. Do it.
An MP3 should contain a lesser quality version of the original signal, most of the frequency components will be there but phase measurements won’t align since the MP3 encoding uses transforms of sinewaves.
technically it is cosines but, yes, that’s a good point.
The math is messy, but there are (at least) 3 ways to get the same results. Encode/decode with sine and cosine at N frequencies. Encode/decode with sine at 2N frequencies. Encode/decode with cosine at 2N frequencies. Jean-Baptiste Joseph Fourier will happily tell you that all will give you the same output. Phase info is not necessarily lost. This can be proven with trig identities.
Best conversation I’ve had in a while, thank you all. This happens to be my favorite technical subject, audio and music maths.
I notice the most distortion in MP3 codec on hihats and other noisey and harmonically dense transients. Cymbals. Guitar picks against strings, and speech
Part of the psychoacoustics of MP3 is about removing masked frequencies. If you have a strong single frequency signal, it looks for adjacent frequencies and if there’s a weaker signal nearby that is less than -6 dB from the stronger one, it will simply delete it because your brain will ignore it anyways.
When gives some wide band noise, like a cymbal hit, it tracks to the strongest peak and starts deleting frequencies around that to maintain the allocated bit rate. Random noise is difficult to compress, so it ends up deleting too much.
Of course, what your brain ignores depends on whether you’re listening closely. It’s not that your ears don’t hear it – just that you’re not necessarily paying attention.
If you don’t know what the original sound is supposed to be like, it passes like false money.
Luckily for audio, compression artifacts are also referenced in contemporary musical idioms. There are now VST fx which simulate GSM, MP3, etc. Personally I use nonlinearities and distortion frequently during mixing and mastering. Saturation, bitcrushers and filters mainly.
yeah i don’t remember the song off the top of my head but i heard clearly to me what sounded like 64kbit mp3 distortion. so i cursed my toolchain and ripped the cd again and listened to the uncompressed wav…oh, they did it on purpose :)
It is not a very utilitarian effect, but then I guess most SFX are not lol
It is hilarious how someone bothers to code a 320 kbps mp3 file yet chooses to use joint stereo. Darwin award nominee for sure.
I do not think that this is a good example of how Darwin awards work, considering that there are (as far as I know) no recorded events of people dying (or unable to reproduce) from “bad” audio or “bad” compression choices.
i’m dyin on stage
Joint stereo can be better than separate channels.
Intensity joint stereo is always worse; that’s per-band panning, and will never sound as good. The only reason it exists is that adding per-band panning to a mono encode is cheap in terms of bits used.
But MP3 supports mid/side joint stereo, where it encodes (L+R)/2 and (L-R)/2 instead of L and R, which is identical quality in a lossless codec, and can be higher quality than separate channels in a lossy codec (since the two channels are correlated).
In this respect, mid/side is similar to YCbCr 4:4:4 versus RGB; it’s exactly the same information in a different layout, and it happens that this makes it easier to compress.
That sounds fine in theory, but you have to consider that MP3 isn’t that clever in allocating bitrate to each of the channels. CBR joint stereo is usually a bad idea, while VBR helps but it’s not perfect. Even VBR doesn’t scale the bitrate all that well to account for times when massively more is needed e.g. for a cymbal hit. The emphasis in the encoding isn’t usually to improve the sound so much as to reduce the file size, but that depends on the encoder, and there are limits to how much and how fast the dynamic allocation can vary.
The sum channel is going to end up with a lot more information because it’s essentially a mono mix of left and right channels. Meanwhile, the difference channel doesn’t usually contain a whole lot of information because what is mutually the same between left and right gets removed. So, the bitrate allocated to that can be reduced by a lot, reducing the overall file size, except when it does happen to matter and there’s a whole bunch of difference between left and right.
The end effect is usually that the sum channel becomes more difficult to compress but isn’t necessarily given enough bitrate to do that, resulting in more artifacts, and the difference channel is allocated too little bitrate for the times when it needs it, again resulting in more artifacts. The average sound quality becomes better relative to the file size, at the expense of introducing worse individual distortions.
In essence, the joint stereo scheme works well when the stereo image is achieved by panning volume left and right in mixing, and it doesn’t work well when it’s an actual stereo recording done with multiple mics where there is both amplitude and timing, reverb, noise, etc. differences between the channels because the two mics hear the same thing in different ways all the time. The assumption that the difference channel can be given much less bitrate breaks down, yet that’s what the encoder is trying to do to reduce the file size.
MP3 uses a psycho acoustic model for compression. RMS is a technical measurement and does not reflect psycho acoustic features of the human ear and brain. Therefore RMS is quite useless for trying to quantify human hearing impression.
https://en.wikipedia.org/wiki/Psychoacoustics
Isn’t that the conclusion I reached above? I am sure you read the article.
That’s what she said!
Not as many people today listen to music actively; their streamed playlists are wallpaper – pleasant bg noise for a party, or distraction on the bus, etc. I’m not immune; I like pleasant tunes in the car, in the workshop, etc, and streaming is pretty darned good for that. I’m not always seated in an armchair, positioned perfectly between two $$$$ speakers in a tuned room.
To me, compressed streamed files tend to lose a little air or a sense of detail AND space in stereo, when compared to the original. This probably doesn’t matter as much with modern pop recordings which are aimed at streaming users. But it is a loss, and if users ever pivot back to a pursuit of sonic excellence, there will be a great trade in uncompressed classics. And hopefully some new artists embracing a better quality of sound reproduction.
Personally I would choose some basic wave (square, saw) as a sound source before bongos. Those are fairly rich in harmonics so compression algorithm have enough material to remove and harmonics appear in frequency domain as regular spikes so difference between original and compressed sound should be more visible. Finally comparing signals in time domain would also be as easy as just showing two waves next to each other. I did just that in Audacity second ago – funny I never came up with this long time ago when I was playing with sound more. Perhaps it’s good time to pick up GNU Radio lessons.
That (basic square or saw wave) works out conveniently for the math, but not so well for a good musical experience, at least for most people’s tastes. Which does sound like Jenny’s final conclusion – that distortion measured in the most straightforward mathematical spaces is different from distortion as eventually perceived by the ears and brain.
Related : “The ghost in the mp3” or an art project which released a version of the first song ever compressed as MP3 (Suzanne Vega – Tom’s Diner) in which the MP3 is substracted to the uncompressed version.
More info : https://www.theghostinthemp3.com/theghostinthemp3.html
Long time ago I hook up my MD to oscilloscope to see the different on compression.
Higher compression has smoother curve.