
A few years ago, [Artem] learned about ways to focus sound in an issue of Popular Mechanics. If sound can be focused, he reasoned, it could be focused onto a plane of microphones. Get enough microphones, and you have a ‘sound camera’, with each microphone a single pixel.
Movies and TV shows about comic books are now the height of culture, so a device using an array of microphones to produce an image isn’t an interesting demonstration of FFT, signal processing, and high-speed electronic design. It’s a Daredevil camera, and it’s one of the greatest builds we’ve ever seen.
[Artem]’s build log isn’t a step-by-step process on how to make a sound camera. Instead, he went through the entire process of building this array of microphones, and like all amazing builds the first step never works. The first prototype was based on a flatbed scanner camera, simply a flatbed scanner in a lightproof box with a pinhole. The idea was, by scanning a microphone back and forth, using the pinhole as a ‘lens’, [Artem] could detect where a sound was coming from. He pulled out his scanner, a signal generator, and ran the experiment. It didn’t work. The box was not soundproof, the inner chamber should have been anechoic, and even if it worked, this camera would only be able to produce an image or two a minute.

The idea sat in the shelf of [Artem]’s mind for a while, and along the way he learned about FFT and how the gigantic Duga over the horizon radar actually worked. Math was the answer, and by using FFT to transform a microphones signals from up-and-down to buckets of frequency and intensity, he could build this camera.
That was the theory, anyway. Practicality has a way of getting in the way, and to build this gigantic sound camera he would need dozens of microphones, dozens of amplifiers, and a controller with enough analog pins, DACs, and processing power to make sense of all of this.
This complexity collapsed when [Artem] realized there was an off-the-shelf part that was a perfect microphone camera pixel. MEMS microphones, like the kind found in smartphones, take analog sound and turn it into a digital signal. Feed this into a fast enough microcontroller, and you can perform FFT on the signal and repeat the same process on the next pixel. This was the answer, and the only thing left to do was to build a board with an array of microphones.
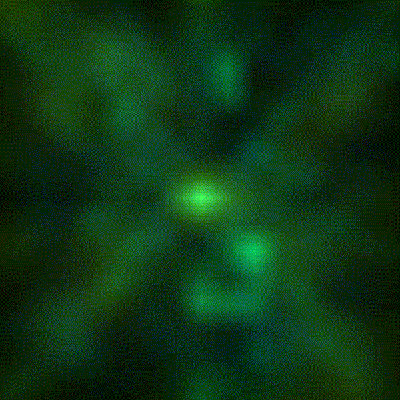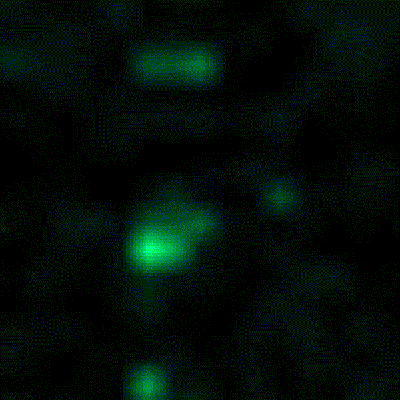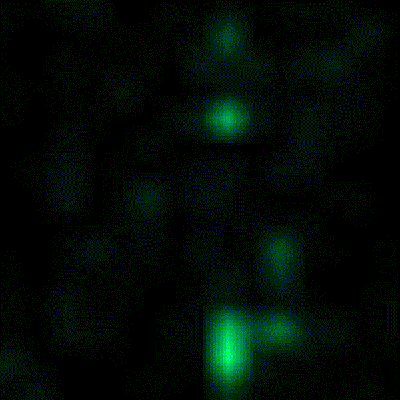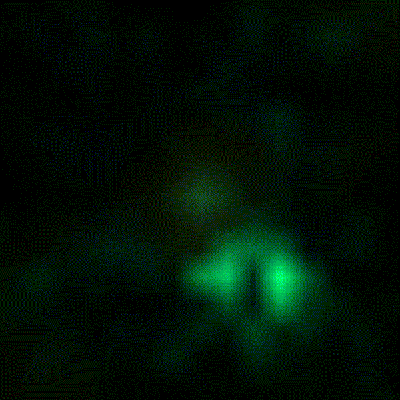 [Artem]’s camera microphone is constructed out of several modules, each of them consisting of an 8×8 array of MEMS microphones, controlled via FPGA. These individual modules can be chained together, and the ‘big build’ is a 32×32 array. After a few problems with manufacturing, the board actually worked. He was recording 64 channels of audio from a single panel. Turning on the FFT visualization and pointing it at a speaker revealed that yes, he had indeed made a sound camera.
[Artem]’s camera microphone is constructed out of several modules, each of them consisting of an 8×8 array of MEMS microphones, controlled via FPGA. These individual modules can be chained together, and the ‘big build’ is a 32×32 array. After a few problems with manufacturing, the board actually worked. He was recording 64 channels of audio from a single panel. Turning on the FFT visualization and pointing it at a speaker revealed that yes, he had indeed made a sound camera.
The result is a terribly crude movie with blobs of color, but that’s the reality of a camera that only has 32×32 resolution. Right now the sound camera works, the images are crude, and [Artem] has a few ideas of where to go next. A cheap PC is fast enough to record and process all the data, but now it’s an issue of bandwidth; 30 sounds per second is a total of 64 Mbps of data. That’s doable, but it would need another FPGA implementation.
Is this sonic vision? Yes, technically the board works. No, in that the project is stalled, and it’s expensive by any electronic hobbyist standards. Still, it’s one of the best to grace our front page.
[Thanks zakqwy for the tip!]















Hmmm, what an interesting idea :-)
The green gif video image example reminds me of the cosmic ray background signal. Which leads me to wonder that if we get more resolution & better instrumentation re gravity waves we might be able to correlate those vectors with the static CMB image we have and offer a modicum of animation…
Back to project, I like this idea for a few other areas re crowd dynamics ie Possibility to predict mob movement & pre-empt with barriers/negative re-inforcement in times of riot/conflicts – yes a bit “out there” but, there is a looming rationale behind it, cheers & well done :-)
“I like this idea for a few other areas re crowd dynamics ie Possibility to predict mob movement & pre-empt with barriers/negative re-inforcement in times of riot/conflicts” — which for some reason makes me want to model a large-scale Tesla fluidic valve as a crowd control device (maybe a “boids” flocking simulation).
Back to sound — you can use microwave designs to focus sound (including parabolic dishes, zoneplate focusing, waveguides, etc.). In fact, (as I recall) 2.4GHz antenna designs can be tested with 2400Hz audio, with sound transducers replacing antenna active elements (and your ear to detect sounds in the signal path). Perhaps such microwave designs could be used in a project like this sound camera.
It is all about phase. Some space-time distortion detectors far enough apart and you can get direction. Or in the same place but detecting on 3 axis gets a line without knowing which direction along the line. You don’t need a phased array plate like this camera.
As in a tetrahedral mic?
https://en.wikipedia.org/wiki/Soundfield_microphone
This is fantastic!
Would it be possible to layer the sound data onto live video, like the thermal cameras we keep seeing here? I can imagine aiming this device at the trees and seeing activity where birds and other wildlife are.
Nice microphone array! Sell this as a kit please. :D
I’ve been wanting to do the camera part for years. I hadn’t even thought about the audio array until now. My idea of the visual camera part would be 3 cameras overlaid on a screen, like a semitransparent Google Glass type display. The required electronics would be in small hip pouch or something.
1) a day/night camera, like a visible + IR security camera
2) a thermal (long IR), like a FLIR One.
3) a Gen 3 night vision camera (IR illumination + starlight)
There would be a *ton* of uses, especially for public safety people, like fire departments, and search & rescue.
Adding something like this audio sensor would be amazing. An extreme example would be something like a gunshot in a crowd. Now you’d see the pulse from the noise, the hot gas plume, brass falling, and the tip of the weapon. I’d suspect the a shooter would already look hotter, simply because of nervousness.
… or they might just see it was a car backfiring.
Unfortunately, we have the same problem. No one has enough disposable money to throw at.
I’m wondering if a grid of foam, a square surrounding each mike, would increase the accuracy.
Probably not. Those microphones are not directional, “pixels” are extracted using advanced postprocessing, where you remove shifted signal from adjacent microphones for each one microphone in order to do reverse beamforming. It’s software-defined scanning, so grid of foam probably would add some unwanted distortions.
I disagree. Adding foam around the sensors would serve to decrease the angle of detection (attenuating sound from wider angles only), and thus increase the SNR in regards to sound coming from a smaller area in front. This would allow you to (potentially) gain higher resolution of sounds coming from in front of the device, while losing sensitivity to sound coming from wider angles, like the sides. Depending on what you want to do with it, it could be good or bad. I may be wrong so please correct me as necessary.
P.S. I accidentally reported your comment while trying to reply, so moderators, please don’t delete his post. Sorry!
I disagree with your disagreement :-)
For light the easiest way to create an “image” is to have optical detectors each detect the light coming from a single direction. You have an optical system that does two things. First it lets only light coming from a single direction hit each of the sensor elements. Secondly it concentrates light: allowing for detection of lower source signal levels.
But that is NOT what we’re trying to do here. We are NOT trying to get each sound-detector-element to detect just sound from a single direction, we’re trying to get each detector to hear all of the sounds, and the post-process step will calculate where everything came from. This does NOT depend on the sounds being separated, the opposite actually, it is essential that all the sensors hear all of the sounds.
With light we can do something similar. The bandwidth of light however is so large that we cannot record the amplitude-and-phase in real-time and then do the math. What we can do is however to record those things at one point in time and then use physical tricks to reproduce the original signal. This is a hologram.
The Fourier Transform is referred to as the “Lens of Science” for that reason, and as I pointed out above there are even newer methods.
I think it would be interesting to use Pyramid Foam and have the sensor element (and LED) at the peak of each. This should at least attenuate sounds coming from behind the sensor.
Follow the link below to the Sorama microphone grid array and take a look at what they’ve built. It’s essentially identical to what this builder has created, but they mounted the microphones to an open grid to minimize reflecting the sounds.
If you want to find out more, this technique is more commonly called ‘acoustic beamforming’, and is very widely used for sonar and communications subsea (as well as other areas, but subsea is what I know best!). With an array like this you can fairly accurately measure (and track) the direction of arrival of sounds, and also ‘focus’ on that sound rejecting noise from other directions.
Some ‘in air’ applications include gunshot localisation and picking audio out in a noisy environment, I think both have featured on HaD previously.
This is also how the Kinect 2 works for background noise rejection, it also has some trick features where applications can “focus” the camera on someone (a direction) when they speak in a teleconference for example.
Although I am sure thats only a 4 array element so its not 100% accurate.
The Dutch company Sorama builds these microphone arrays as well: http://mobile.sorama.eu/CAM1K/. Love this project though, good to see ‘hackers’ picking up on this as well.
That looks cool!
I started laughing when I found this on the spec sheet:
Third party requirement Microsoft Silverlight 5
That looks very expensive
http://www.sorama.eu/sites/default/files/banner/cam_mems_surface_black_banner1.jpg
great build!!
if you are going to reference the DUGA radar, you really need to look at what we do in Australia
http://www.dst.defence.gov.au/innovation/jindalee-operational-radar-network
https://en.wikipedia.org/wiki/Jindalee_Operational_Radar_Network
All that technology just to track kangaroos!
That is actually really interesting. :)
This is similar to a sonogram, right? Aside from the sonogram having an active part (sound emission) and low resolution, are there other differences? DIY sonogram would be good for searching wires, leaks, etc. on walls.
Sonogram and this are both imaging with sound, but sonogram is like scanning with beam of sound, it detects how things reflect sound. This “camera” looks at sound sources, more like normal camera.
Sound camera with real camera:
http://yle.fi/uutiset/milta_aani_nayttaa_videolla_katso_miten_helsinki_meluaa/8937587
This is called “seismic imaging” or “migration” in the oil patch. Of, course, since big oil is mostly in Texas, things are much bigger. Recently this was done using 18 streamers and several hundred thousand sensors at once. And tens of thousands of cluster nodes will be used to process the data once a few dozen TB have been collected. It’s also the basis of 3D ultrasound imaging.
In principle you can image the entire room, but that is a seriously non-trivial undertaking. Both the compute and the math. Well understood, but lots of complexity to master when dealing with the limitations imposed by the sampling.
So with enough computing power, could this be used to isolate a single specific sound source? This would be terrific for speech recognition if it could isolate a single voice in a noisy room.
It is already good enough if the sampling rate is high enough, like 10 or 16 KHz for phone quality sound. He can “focus” as fine as a single pixel in the imaging and do the computations for just that location or really, that direction. In fact, I think for a single location you can just shift the data from each microphone to adjust for the delay of a sound from that direction and add them all up. Dang! Now I have to read the whole thing. Is he using I/Q sampling of each microphone?
I can’t see any reason that the image should not have much higher resolution than the array size. Angular resolution, or the ability to measure phase/delay should determine the display resolution. Higher sampling = finer angular resolution = finer display. The number of detector elements (and their spacing) will determine the spatial resolution of a sound source. So yes, you can get ill defined blobs in the image yet have high potential resolution as far as location of the blob.
Anyway, that’s my theory and I’m sticking to it – for the moment.
Why a planar array instead of cylindrical or spherical?
If I had to guess it’s because it’s much easier to process a square.
Looks like a 256 “pixel” sound camera (16×16), not 1024. Still, neat idea with nice execution.
They are not really the same. A few radio antennas can give very high resolution image of a radio source be means of aperture synthesis and interferometry. Basically the same processing methods used here.
I wonder if he tried imaging a point source, like a balloon poping?
Or an insect. Moving target, but I want to see!
Perhaps a good sound source would be a brief duration pulse such as an electrical arc between two electrodes since this can be controlled very precisely by simple means. It still gives a very large sound pressure and is highly reproducible with minimal effort.
Could he get the phase information for each imaging cell by using the random mask and compressive sensing method? This allows you to make a spherical sensor and map an entire environment from one point.
You aren’t going to get good performance trying this with basic FFT tricks, look up DAMAS for the pro way to make sound cameras, you can get very good results with as few as 64 microphones.
http://asomb.larc.nasa.gov/directory/sdarticle%282%29.pdf
That is a great paper, but I think that there are newer methods that do not require scanning therefore they may be faster and less electronically complex. But I have to admit I can’t quantify that as the new methods may be computationally more or less intensive so with unknown trade-offs I can be sure if they turn out to be “better” over all.
“No, in that the project is stalled, and it’s expensive by any electronic hobbyist standards.”
I would still love to see a schlieren photography setup where a sound source flickers at 1KHz while the light source flickers at 1002Hz so that you can visualize the pressure waves and see them move at 2 wavelengths per second…
with clever math and an FPGA implementation, incoming audio from microphone could shift all frequencies by 2Hz (ring modulation) and this resulting signal fed to illumination source so you could visualize arbitrary spontaneously present sound waves
I might try and build that. Wonder what amplitude would be visible?
the amplitude in sound pressure determines the change in index of refraction of air, which determines the deviation angle. the change in intensity is caused by displacing (the deflection caused by the change in refractive index) the image of a point light source so it falls on the blade/different color zone on a slide. so the sensitivity is proportional to the distance between the blade and the mirror, but this distance is limited by the spot size and shape, and thus the quality of the mirror, and the quality of the point source. In a normal schlieren photography setup sound is not visible because the frequency is too high for the shutter time, unless the frequency is low (you can see a hand clap pressure wave in one of the youtube videos)
correction:
In a normal schlieren photography setup sound is not visible because sound is periodic and the frequency is too high for the shutter time, averaging out the light intensity for multiple sound cycles during the frame… unless the sound is impulsive and not periodic (you can see a hand clap pressure wave in one of the youtube videos)
forgot to mention this is also used to visualize the pressure/sound waves (in water) of focused ultrasound probe, theres a youtube video of that as well, but instead of syncing to the ultrasound cycle, you’d want to light a frequency shifted signal from a microphone…
I’m not sure why I proposed using an FPGA last time, since ring modulator can be built with minimal analog components… perhaps it was for flexibility?
Combined with a video camera for a background image.
Without video, you can not really locate the soundsource.
1 Year later, and now?
When can we build it?
What will it cost?
And perhaps also a new additional “toy” for ghost hunter…