Last time, I talked about a simple kind of neural net called a perceptron that you can cause to learn simple functions. For the purposes of experimenting, I coded a simple example using Excel. That’s handy for changing things on the fly, but not so handy for putting the code in a microcontroller. This time, I’ll show you how the code looks in C++ and also tell you more about what you can do when faced with a more complex problem.
I built a generic base class that implements the core logic and can handle different vector sizes. Here’s the header:
class Learn
{
protected:
unsigned int stimct; // number of stimulus (will be +1 due to bias)
unsigned int resct; // number of results
float threshold; // threshold (default 1.0)
float **weights; // weight matrix
float *result; // results
float *_stim; // place to put stim + bias
void set_stim(float *s); // helper to load stim+bias
public:
// Note: stimulusct is your stimulus count;
// The code will add one to it to account for bias
Learn(unsigned int stimulusct, unsigned int resultct);
~Learn();
int init(void); // reset weights and threshold
// perform training (stimulus should give result and use a training rate)
int train(float *stim, unsigned int result, float wt=1.0f);
// Get result for given stimulus
unsigned int fetch(float *stim);
// set/get threshold value
void setThreshold(float t) { threshold=t; };
float getThreshold(void) { return threshold; };
// load weights from file
int load(const char *fn);
// save weights to file
int save(const char *fn);
// debug output
void dump(void);
};
The class handles adding the bias input and doing all the math for training and classification. You can find the class code, along with a simple demo called simple.cpp, on Github. Just run make to build the example program.
The simple demo has an array of training data for AND logic and another for OR logic. Here’s the AND data:
float and_trng[4][2] = {
{ 0.0, 0.0},
{ 0.0, 1.0 },
{ 1.0, 0.0 },
{ 1.0, 1.0}
};
int and_trngr[]={ 0, 0, 0, 1 };
The code does the training repeatedly until the right answers appear:
for (i=0;i<4;i++) lobj.train(trainingdata[i],trainresult[i],TRAINRATE); for (i=0;i<4;i++) if ((res=lobj.fetch(trainingdata[i]))!=trainresult[i]) again=1;
The again variable causes the training/testing sequence to repeat. If the data isn’t linearly separable (for example, try changing the data to do an XOR), the code will break out after 500 passes through the training data.
Less Exciting
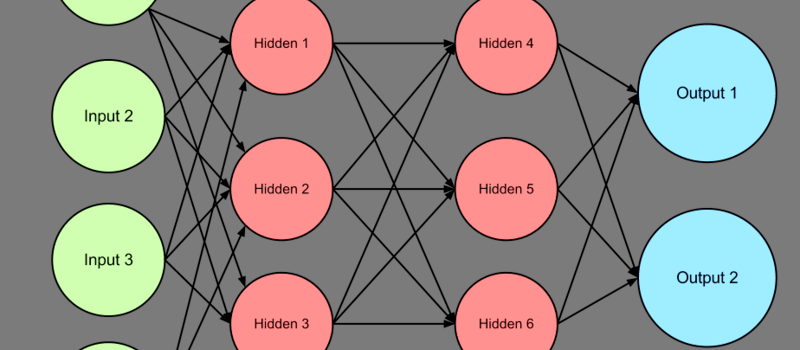
Of course, AND and OR gates aren’t very exciting. To do anything really interesting, you need multiple layers of perceptrons to form a real neural network. According to the math, three layers of perceptrons is sufficient to handle any case. One layer accepts inputs. The outputs from that layer feeds the “hidden” layer. Those outputs feed a layer of output perceptrons.
Training a network like that is more difficult, of course. However, the principle is the same. Errors in the outputs are backpropagated to the perceptrons using a learning algorithm.
Open Source and Hardware
I wanted to write some basic software to illustrate the principles. However, if you want to really ramp up, you probably should turn to a well-developed library like OpenNN (you can see a similar example for OpenNN and it even includes XOR). Or you might consider FANN, if you don’t like OpenNN.
If you want to try something in hardware, these algorithms are not very hard to do in an FPGA. Or you can buy some hardware (you can see a video about that card, below).
If you want to see some of the projects we’ve looked at that use neural networks, you can read about targeting cats, play Super Mario, or control a helicopter.















Cool article. I’ve been doing some machine learning classes online but they implement everything with either Matlab or Python. I like the C++ take on ML. I do wish that HAD would allow a bit better syntax highlighting in the embedded code blocks though.
For more C++ justice, here’s my friend’s C++11 templated superfast version: https://github.com/TrentHouliston/FMLP
We did some testing and it compiles down to pretty much pure vectorized ops. The run-time speed is pretty nice.
Really neat stuff. As a person who builds OSH electronic neuron simulators (albeit they are designed for biology education rather than ANN research) I’m a bit embarrassed that I hadn’t heard of some of those open-source projects. Thanks for the excellent article!
So 20 years later C++ experts still implement NN by encapsulating C code. Then I was right in the first place, C++ is not a language for NN. Actually it is less efficient than C since it uses Call Tables to reach the methods. Encapsulation is not OO programming. It just slows down your process…
Actually C++ uses call tables only for virtual functions, and I don’t see any in the posted code.
>>So 20 years later C++ experts still implement NN by encapsulating C code.
Maybe to keep the example short, but in general you are very unlikely to see an expert do that. This is two star C code.
>>Then I was right in the first place, C++ is not a language for NN.
No, please refer to the code linked by Josiah Walker above for code that is actually C++.
>>Actually it is less efficient than C since it uses Call Tables to reach the methods.
I don’t see any virtual functions. Please check with the C++ standard, or better yet look at the instructions that your compiler actually generates.
>>Encapsulation is not OO programming
Yay!
>>It just slows down your process…
If you do it wrong. If you have enough complexity that it makes sense to have classes with virtual functions there isn’t really a better way to do it.
Well, when I used to teach C++ I often mentioned to my class that just because a tool CAN do something doesn’t mean that you SHOULD do it or that it is the right way to do everything. In this case, I was going for clarity of exposition, so I didn’t want someone to have to parse a complex class hierarchy just to understand the principle. If I had wanted to do that, I could have just linked to some of the nicely-done class libraries (which I did) and say “go read that.” I did want to encapsulate so that you could extend the code without having to tear up the core (e.g., if you wanted to test other learning algorithms).
I don’t have a link handy, but my buddy Rud posted a piece on here awhile back that I think covered the vtable overhead issue nicely. The summary is that yes it adds a little overhead, but if you are using it because you need that capability, it is slower to do it without vtables. Now, granted, if you are comparing C static calls to C++ virtual calls, your performance will suffer. So the question isn’t: are vtables inherently bad? The question is: do I really need a virtual call here to meet my requirements?
Interestingly, the nicely built class hierarchies are often where you need vtables for no other reason than to support your nicely built class hierarchy because you want polymorphism.
Any chance you could post a link to the excel file?
The link is in the first installment: https://hackaday.com/2016/11/02/machine-learning-foundations/
I cant seem to find it there. Can you post it again?
Rats, something “ate” the link. I’ve fixed it, but here’s the direct link: https://github.com/wd5gnr/perceptron
Am I the only one that thought of Futurama when I saw the word “perceptron?” :)
https://theinfosphere.org/images/thumb/8/89/Perceptron.png/345px-Perceptron.png
I recently wrote a neural net in C++. It compares well (better) than googles simplest model Softmax. You can see the results here: https://adil-nnet-adil-malik.c9users.io/test-data-preview.html , of 1 hour learning on the handwritten digit train set called MNIST. The accuracy is about 96%. The link is to a web based GUI i made to go through the first 1000 characters in the test set and see my models prediction.
I trained my four-lagged robot to walk with a CortexM4…
I have used the FANN lib you considerd…
https://sebastianfoerster86.wordpress.com/2016/11/07/robot-controlled-by-artificial-neural-network/
It makes a lot more fun to have some practical examples, but without the theorie you will stuck even with the simplest thinks…
Thanks for this post(s)!
I used FANN during my PhD, in order to estimate blood alcohol content from user playing video games (monitoring the racing wheel and controls, no invasive measurements, nor any sensors on the user) up to +/- 0.1g/l after only 15s of driving in supertuxkart.
This is the first paper on this work : https://www.thinkmind.org/index.php?view=article&articleid=achi_2011_9_40_20101
I later on expanded the work with realistic simulators, and used other machine learning methods for such tasks, and took on other driving problematic.
Later on, i preferred using SVM to MLP for it’s speed and optimization process. Indeed, for the MLP, it’s not that simple or fast to select the best hyper parameters (layers count, neurons per layer, and i was excluding the sparseness of the connections between layers : i had always fully connected layers), select relevant inputs, etc…
There are methods to optimize MLPs, such as optimal brain damage, described by Lecun (this guy works for facebook now!) et Al. , but it’s not implemented right away in FANN and wasn’t in OpenNN when i checked.
On the other hand, SVM are quicker to optimize, and are equally as fast in generalization. In my use cases, i obtained comparable results with both. However, i can’t prove that there isn’t an MLP configuration with better results, since
the search time grew really fast when increasing the range on one parameter, and some are in R, so can’t test all values.
That caused, for me, a lower interest in MLP compared to SVM. However, with other neural network topologies, such as hopefield or other reccurent networks, there is a huge potential. It showed with the recent advances in AI due to deep learning. However, those are way more complex than SVM, and you are unlikely to find a lirbrary laying around :)
Oddly enough, I tried to do a more complex version that tries to take into account the effect of neurotransmitters as well as the triple layer preceptron. https://hackaday.io/project/5681-multi-function-selective-firing-neurons
Although I must admit, it’s not as elega2as yours.
*elegant as
What alway’s troubles me is that you first have to give the network the answer and then it starts learning by trail and error . Somehow this does not feel right. But maybe I am the only one who thinks this way? The second thing I don’t understand is as soon as it learns the AND and OR logic (or whatever the goal you set) how do you use it?
I thought exactly that! Being an EE i said exactly that to a Comp Sci friend and he wasnt that pleased! The fact that we are doing a glorious form of trial and error didnt sit with me well either, however once you consider that if done correctly, it can tackle ridiculously abstract problems that were once thought as a no go for computers. Id take that.
You use a Net the same way you trained it, however instead of feeding it with training data you feed it with actual data and observe the output.