It’s 2018, and while true hoverboards still elude humanity, some future predictions have come true. It’s now possible to talk to computers, and most of the time they might even understand you. Speech recognition is usually achieved through the use of neural networks to process audio, in a way that some suggest mimics the operation of the human brain. However, as it turns out, they can be easily fooled.
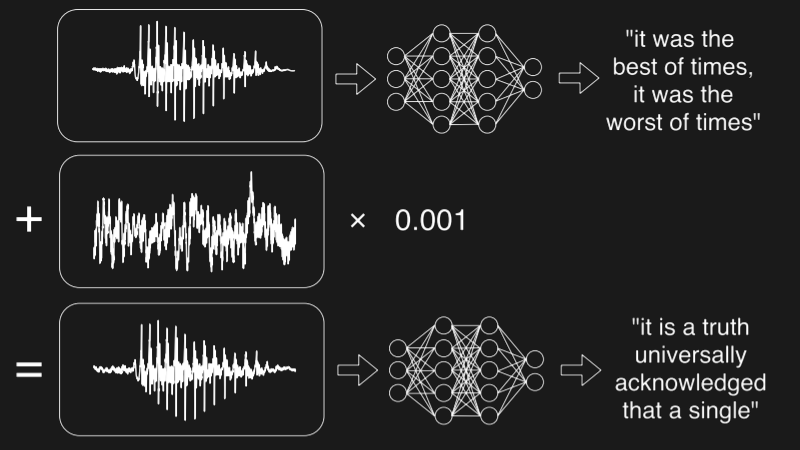
The attack begins with an audio sample, generally of a simple spoken phrase, though music can also be used. The desired text that the computer should hear instead is then fed into an algorithm along with the audio sample. This function returns a low value when the output of the speech recognition system matches the desired attack phrase. The input audio file is gradually modified using the mathematics of gradient descent, creating a result that to a human sounds like one thing, and to a machine, something else entirely.
The audio files are available on the site for your own experimental purposes. In a noisy environment with poor audio coupling between speakers and a Google Pixel, results were poor – OK Google only heard the human phrase, not the encoded attack phrase. Given that the sound quality was poor, and the files were generated with a different speech model, this is not entirely surprising. We’d love to hear the results of your experiments in the comments.
It’s all a part of [Nicholas]’s PhD studies around the strengths and pitfalls of neural networks. It highlights the fact that neural networks don’t always work in the way we think they do. Google’s Inception is susceptible to similar attacks with images, as we’ve seen recently.
[Thanks to Wolfgang for the tip!]













Most of the time? I think you mean some of the time.
We play a game with the GPS in the car: trying to fool it into obeying nonsense phrases that sound like commands. For example: “oyster man” and “horse demand” are accepted as “voice command.” It’s fun to tell it what to do in complete gibberish.
As someone researching in the same lab as people doing speech research I find this amazing. Although speech recognition is a ‘dead’ research area for small labs, I’m sure we can have fun with systems made by previous researchers.
As an Australian, I used to enjoy the fact that the Google Assistant would respond to “OK, Googz”.
if TV commercials could figure how to do this it would be great! make google and alexa do strange things without anyone knowing.
Go to a bar, find the biggest, drunkest guy and get up in his face and tell him “Go vuck yourself!”
After you regain consciousness laugh at him because you hacked his neural network. He misheard “vuck” as something else.
Eminem and Fack…. sounds a bit like fu** doesn’t it?
Oh, I’ve heard the phrase “English people grunt when they speak” from various (Mostly language-education) sites and people whom have intricate sounded languages… Thinking Chinese, Japanese, Arabic, Hindi, Sanskrit, Gujarat, And too many to list here.
So where is this “grunt” we don’t hear? Well I’d guess if people whom speak a more vocally sophisticated language can hear something a lesser vocal-oriented language speaker can’t hear, then I’d say the neural network is working exactly as intended.
P.S. The neural network doesn’t emulate a human brain, just like extracting 5 neurons from a human brain and 5 from a cat’s brain and training them up will not simulate either of the brains they’ve derived from.
You need a cat’s worth of neurons minus the relative excess motor-neural-networks to simulate the cat’s cognitive behavior.
You need a human’s worth of neurons minus the relative excess motor-neural-networks to simulate a human’s cognitive behavior.
Reason behind the lesser motor-neurons is because electronic motors are simpler to actuate than muscles and there is no digestive system or heart to keep track of so those nerves can be omitted from simulation, yet the reason for not removing anything else is to allow the simulation to acquire a similar neural-environment experience to a real human. The networks have to be structured similarly to simulate various chemical chambers.
I was under the impression that even the motor areas of the brain lit up during certain thought processes while being observed with FMRI. This would lead me to believe that in order to mimic the thought pattern of a human brain, you would need to utilize an entire human brain’s worth of neurons. I could be wrong, of course.
Ask any German speaker why selling Vicks cough syrup in Germany under the same name they used in English speaking countries was a horrible idea. (Hint: The F and V are much closer sounding in German than in English.)
How about auditory illusions and neural nets?
If we talk about illusions in general, than this totally different audio tricking the NN is a good example of an illusion for deep NN.
If we talk about _human_ illusions in Deep NN, I don’t think they are possible. On the contrary, with HTM (Hierarchical Temporal Memory) NN it’s expected to see the same type of illusions as humans have.
Context is very important for humans to recognize speech.Going up to a drunk in a bar sets a context. Also, the voice used matters. Laughing and smiling while saying “Go vuck yourself” may not have a violent reaction. The current state of voice recognition generally falls short of human capabilities as they focus on pattern recognition with a minimal understanding of context and, more importantly, with an extremely limited understanding of how the world works and human behavior. IMHO, true AI requires that the systems have good internal “real world” models describing how things works. This could be part taught and part learned, just like we humans do. We learn that insulting a large drunk is generally not a good idea. We learn that “horse demand” makes no sense for a GPS. We are taught many things about human behavior by our parents and so on. In the future, AI systems will be built with internal “real world” models that can evolve and expand with experience. Until then, pattern recognition systems will be error prone. Hopefully their use will be limited if the results could be hazardous. Imagine having a voice activated nuclear plant without the system having an understanding of potential consequences of its actions. Interestingly, true real world model based AI may be better at such systems as they could be made devoid of human limitations such as boredom, distraction, panic etc.
It is a given default that our artificial underlings should always pay full attention to us and always obey us. We should cut them some slack, allow them to just plain play deaf if combination of moot context and noisy input does not excite them enough.
Mainstream AI, as in deep NN speech recognition, is based on math. Sometimes, these mathematical constructs (deep NN) _appear_ to do what a brain does, but they are doing it in a very different way. That is why a complete different phrase can trick the voice recognition, but can not trick a human. Yet, a human can be tricked too, but with a word that sound “similar”, or with a context.
There is another approach for NN, based on reverse engineering the human brain and its data flow. Talking here about HTM (Hierarchical Temporal Memory). HTM was developed by looking at what a real brain does (see Jeff Hawkins and his book “On Intelligence”. If you like it, there is an open source framework, Numenta. Give it a try: https://numenta.com/).
Other said “Deep NN” versus HTM is like math vs physics. First are based on theory and on how a world _could_ be, the second are based on observing and how the world _is_.
My bet is that a HTM based speech recognition can not be tricked by a completely different sound.
So we could expect hardware based Automatic Misheard Lyrics Generator?
It’s here, and it’s called Amazon’s Alexa. For extra giggles, it also mishears items added to your shopping list.
To wreck a nice beach.
I can hear the hidden messages. They sound vaguely like a person trying to speak with an electric toothbrush in their mouth.
It’s clearly speech, and it doesn’t take long to start recognizing the words. It’s just coming in at an unfamiliar band.
Electronic larynx.