
If you consider yourself a good cook, you may or may not know how to make a souffle or baklava. But there are certain things you probably do know how to do that form the basis of many recipes. For example, you can probably boil water, crack an egg, and brown meat. With Linux or Unix systems, you can make the same observation. You might not know how to set up a Wayland server or write a kernel module. But there are certain core skills like file manipulation and editing that will serve you no matter what you do. One of the pervasive skills that often gives people trouble is regular expressions. Many programs use these as a way to specify search patterns, usually in text strings such as files.
If you aren’t comfortable with regular expressions, that’s easy to fix. They aren’t that hard to learn and there are some great tools to help you. Many tools use regular expressions and the core syntax is the same. The source of confusion is that the details beyond core syntax have variations.
Let’s look at the foundation you need to understand regular expression well.
Programs that Utilize Regexp
Perhaps the most obvious program that uses regular expressions — or regexps, for short — is grep. This is a simple program that takes a regexp and one or more file names (unless you want to read from standard input). By default, it prints any lines that match the regexp. Like I said, simple, but powerful and one of the most used command line tools which is why I use it as the example in this article.
But grep isn’t the only program that uses regular expressions. Awk, sed, Perl, editors like VIM and emacs, and many other programs can use regular expressions for pattern matching. And because regexp is so common you will see it pop up in user settings and even web apps as a way to extend the utility of the applications.
Depending on your system, you may have similar programs like egrep. On my system, egrep is just a wrapper around grep that passes the -E option which changes the kind of regular expression grep parses. For the purpose of this post, I’ll talk about egrep by default.
Character Matching and Classes
Consider this command line:
egrep dog somefile.txt
This would search somefile.txt and match the following lines:
I am a dog. There is a special dogma involved. ---dog---
Period as Wildcard
It would not match “Dog” because regexps are case sensitive by default. If that was all there was to it, regexps would not be a very interesting topic. You can use a period as a sort of wildcard that will match any character. So the pattern "d.g" would match both “dog” and “dig” (or “d$g” for that matter).
Escape Characters
What happens if you want to match a period, then? You can escape any special character with a backslash. So "d\.g" will match “d.g” and nothing else. However, keep in mind the tool you are using to enter the regular expression might use backslashes, too. For example, consider this session:
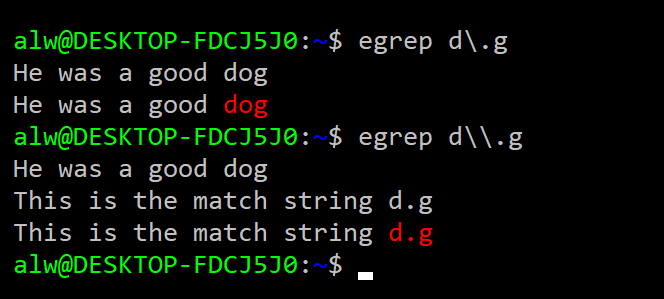
There is a gotcha here. The shell interprets \. as a single period. It doesn’t see the backslash are part of the search but as an escape character in the shell itself. To properly pass \. to grep, you have to escape the backslash (\\) as in the second example. Quoting special characters can get tricky and depends on what shell you use. If you use bash, you might want to just enclose your expressions in quotes or double quotes. Even then, the rules about backslashes still apply.
Character Classes
Sometimes you don’t want a single character, but you don’t just want any character, either. That’s where character classes come in. For example:
egrep [XYZ][0-9][0-9][0-9]V afile.txt
This will select strings like “X000V” or “Z123V”. It is common to use these to allow case insensitivity (for example, [aA] or [a-zA-Z]).
You can also create a negative character class using the ^ character. For example, [^XYZ] will match any character except X, Y, or Z. The If you need to match a dash (-), it should come first. If you need to match a caret (^), it should not come first. Since the order of characters in a class isn’t significant, that won’t cause problems. For example, if you want to match any digit, a dash, or a caret you can write:
egrep [-0-9^]
Repeats
Finding dog, dig, dug, and d$g is fine, but we need to be able to do more. A very powerful part of regular expressions is that you can specify that a character repeats. You can also make a character optional. For example here’s a match for bar or bear: "be?ar"
A very common requirement is to have zero or one occurrences of a pattern (that is, make it optional). You might also want zero or more characters repeating or, sometimes, one or more. Suppose you wanted to match a number in a file from a data logger with an optional negative sign and a decimal point. You might use "-?[0-9]+\.?[0-9]*". It may be helpful to understand this syntax if you to walk through it graphically in the diagram.
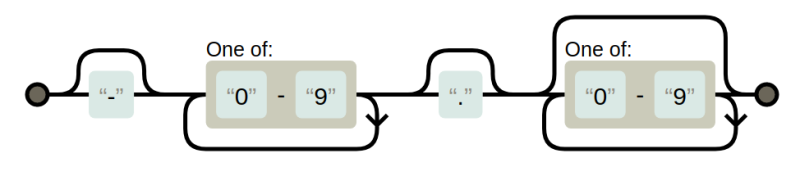
That pattern will match -25.2 or 33. or 17.125. The plus sign indicates that there must be one digit, but there can be more. The * allows for any number of digits including none at all (that is, zero or more matches). Note the decimal point needs an escape. The funny part is, it will work without it because the period will match “any character.” The bad part about that is it will also match things like 14X2 which isn’t a properly formatted number.
Getting Advanced with Repeats
A more advanced regular expression repeat is to use curly braces to specify how many times a pattern can repeat. Some tools require you to escape the curly braces, but grep doesn’t. So to match exactly 4 lower case letters in a row you can use the pattern "[a-z]{4}"
Of course, that’s the same as saying [a-z][a-z][a-z][a-z] but easier to type. You can also set a lower and upper limit as in: [a-z]{2,4} which would match two to four letters. This is the same as [a-z][a-z][a-z]?[a-z]?
Multiple Match Behavior Varies by Program
For grep, the fact that a match occurred is sufficient. For some other tools, it matters if you match the most characters that match or the least. For example, "abc*" applied to a string containing “abccccc” could match ab or it could match the whole thing. This depends on the tool (and sometimes options to the tool or command) but it is good to keep in mind. Different tools work differently, too, on how they handle multiple matches. For example, matching the pattern “X” with a string: “XyyX” could match the first X or both, it just depends. Again, for grep, it doesn’t matter. If the line matches at least once, that’s all that is important.
Anchors
You probably noticed that the pattern match can occur anywhere in the string. You can anchor the match to the start of the string with the ^ character and the end of the string with a $ character. For example, this matches blank lines: "^ *$" or if you want to include tabs: "^[ \t]*$"
As in C, the \t character is a tab. Depending on the tool, there may be other escape characters available, too. You can match lines that have a percent sign as the first nonblank character like this "^[ \t]*%"
Grouping
There are a few ways to group regular expressions. You can use parenthesis, although some tools require you to escape them if you want to use them for grouping. For example:
egrep a(bc)?d
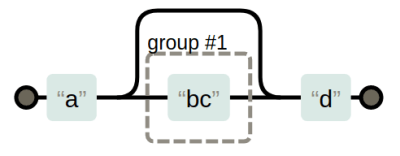
This would look for a match starting with “a” then it will match a “d” or a “bcd”. This isn’t the same as "ab?c?d" because that would match “acd”. You can also use a pipe character as an “OR” operator. For example, "a|b" will match either a or b, which isn’t much different from "[ab]"
However, combined with grouping this is useful. For example, "(dog)|(cat)" will match either animal. In some tools, the grouping will mark a part you want to read as part of some other code or make available in a replacement. For example, in some tools, you might search "id=([0-9])+" then in the replacement string you could use \1 to refer to whatever number matched the expression in the parentheses. The exact details vary by tool. For example, some might use &1 or some other syntax.
Motivation: How Is Regexp Useful?
There’s more but let’s take a break and figure out what good all this is. To do that, assume you have a file full of data from a logger that has temperature data in degrees C. It also has other data in it. However, all the temperatures are in the format of a number followed by a space and an upper case C. So temperatures might be “-22 C” or “13.5 C” as examples.
It would be easy to convert these numbers using a program like awk. I don’t want to get into too many details about awk, but it has a match function and a gensub function that find and replace regular expressions, respectively. It also allows you to filter lines using a rule that is just a regular expression between two slashes. Consider this:
/ C$/ {
if (match($0,/([-0-9.]+) C/,matchres)) # . inside [] doesn't need escape
print gensub(/[-0-9.]+ C/,matchres[1]*9.0/5.0+32 " F","g")
else
print
next; # start over with next line
}
{ print } # print other lines
The first line matches text that has a space and a C at the end of the line. The match subroutine gets the number in matchres[1]. Granted, it can parse nonsense like “-…C” but you can assume there’s nothing like that in there. You could do better with "-?[0-9]\.?[0-9]*" perhaps (but note that if you try this with grep, the leading dash will require a -e option). The gensub function does the conversion. Plenty of regular expressions to make this work.
Variations
Unfortunately, there are subtle differences between different tools. [Donald Knuth] once said:
I define UNIX as “30 definitions of regular expressions living under one roof”.
I’ve mentioned some of these. For example, some implementations treat parenthesis as grouping unless they are escaped while others require you to escape them if you want them to group and not be regular characters.
It is common to see shorthand expressions for things like digits and spaces. This is good because it ought to understand the system’s localization, too. For example [:digit:] is a stand-in for [0-9]. Some tools use special escape characters like \d for the same purpose. Instead of trying to describe it all, I’m going to simply direct you to a table from Wikipedia that describes some common systems.
Tools for Debugging Regexp
That’s all you really need to know. If you want to debug regular expressions interactively. there are plenty of tools for that online. You can also get a visual diagram of a regular expression to help work your way through them.
You might also enjoy a library of regular expressions you can — ahem — borrow. If you’d rather learn while having fun, you might try crosswords or even golf.














Ah, fu
https://regexr.com
A great tool for debugging and practicing with regular expression.
O’Reilly’s “Mastering Regular Expressions ” was a good starting point for the nuances of regular expressions.
Just what I thought of when I read this. A good read, even if you never come close to needing the complexity it covers.
Regex should die like C or COBOL. I prefer to make a simple python class to parse what I need.
C is dead?
COBOL is dead?
I say “kill the damn snake!”.
Now that Microsoft is embracing bash, regular expressions will be everywhere!
But just think, instead of typing “ls *.c” you could type in a bunch of gnarly python instead! How glorious!
Like this: https://docs.python.org/3/library/re.html#re-objects ?
without using regular expressions? at least https://github.com/python/cpython/blob/3.6/Lib/html/parser.py appears to be using regular expressions. I don’t mind python, but the zealots are something else.
+1 excellent troll post. The troll-force is strong with this one…
C? Dead? What are you smoking? https://www.tiobe.com/tiobe-index/
Are you sure that “C” is dead ?? Nice joke Maam. It seems that you are unaware of the fact the the entire Python Interpreter is implemented in 99% “C” only not even “C++”.
1)http://pgbovine.net/cpython-internals.htm 2)https://github.com/python/cpython/tree/master/Python 3)https://github.com/python/cpython/tree/master/Modules 4)https://github.com/python/cpython/tree/master/Parser
If you are are interested in life and death of “Regex” then you might value Linux. and Linux kernel is purely written in “C” with some Assembly. Even windows “kernel” is moslty in “C”.
I’ve tried sooo many times to learn and use regular expressions. It seems easy enough, I think I’ve got it but then it rarely comes out with the results I intended.
So… bash applies it’s own escaping before passing the pattern to grep? I think this might be what I was missing. It also seems to be missing from the several online tutorials I have read, thanks for including that fact!
shell escaping is very confusing when combined with programs that use regular expressions, and also with programs like find that use characters that need to be escaped. The echo program is your friend when you’re trying to figure out how many double quotes and backslashes you need to type to get what you want.
The response by F is correct. I would also add that you can avoid the whole issue with escape characters if you enclose your whole regex in single quotes (If you are not sure of the difference between single vs double quotes in Bash, it’s worth 5 minutes to google and find out). The article mentions that you CAN quote, but i would recommend that you ALWAYS do so, just to save yourself the headache later.
Thanks, I need to brush up on this!
I had some weird gotcha on Linux Mint using egrep. I had to add -e for one of the examples shown in this article:
mike@krusty ~ $ egrep "-?[0-9]+\.[0-9]*"
grep: invalid option -- '?'
Usage: grep [OPTION]... PATTERN [FILE]...
Try 'grep --help' for more information.
mike@krusty ~ $ ^C
mike@krusty ~ $ egrep "-\?[0-9]+\.[0-9]*"
grep: invalid option -- '\'
Usage: grep [OPTION]... PATTERN [FILE]...
Try 'grep --help' for more information.
mike@krusty ~ $ egrep -e "-?[0-9]+\.[0-9]*"
25
25.3
25.3
33.
33.
That’s my bad. Starts with a dash.
Ahh, GNU getopt dashes our plans once again!
Don’t forget bash has regexp’s too, via the =~ operator and the expr builtin.
Regex is fun when you play around with it. On many many occasions I’ve used it in notepad++ to cleanup csv files, generate csv files or cleanup texts to extract data. I also use it with FreeCommander XE to rename a bunch of files.
In my opinion the best way to work with regexes as a beginner is to take it step by step. Use notepad++ and make selections piece by piece, check if it grabs the part you intended and go to the next part.
There are also online regex debuggers/checkers that interactively show you the result. There are many flavors however, often with different ways to delimit the stand and end of the expression, options and how to use parenthisized substrings for searching and replacing/reordering.
A fun way to test, freshen and extend your skills is to play regex crossword games like this: https://regexcrossword.com/
It starts very simple but gets more difficult progressively.
xkcd 208
I learned regexes when using lex (and yacc) to create my own parser for a custom config-file syntax. I still love the occasional chance to work with lex/yacc, or flex/bison, or some of the more modern tools for creating DSLs, like JavaCC. Fun times.
The Regexper Image is wrong – or the Regexp is wrong … there is missing a ? after the dot.
Yes, you are right. If you read the text, the regexp didn’t match. Fixed.
“Some people, when confronted with a problem, think
“I know, I’ll use regular expressions.” Now they have two problems.” –Fredrik Lundh
For more fun with regular expressions, next stop;
sed.I’ve found I’ve been using that more and more as time goes on.
sed -ne "/some pattern of interest/ { s/substitution/for those lines/; p}" somefile.txtbeing extremely useful for plucking out bits of information out of all kinds of text files.sed is also great for making modifications to files:
sed -i -e “s|old text|new text|g” /my/file.txt
it’s just the ticket for an install script that has to tweak files in /etc/ and such. It’s more robust than using diff. diffs will often fail because different linux distributions will make gratuitous changes to files in /etc/ for no apparent reason and we want install scripts that will run on anything
regexp?! regexps is even worse!
Is that actually a common abbreviation somewhere in the world? Like the “My S.Q.L” v “My Sequel” thing?
I’ve always read of, and used it as, an uncountable noun: regex. Adding a “p” on the end just feels wrong!
https://en.wikipedia.org/wiki/Regular_expression If it is in Wikipedia, it must be true.
You can say “regexp?” and you”re covered either way.
Dang F. I wish I had thought of that.
REGEX Exists on any POSIX System but there are so many different syntaxes that its best avoided unless absolutely nessesary.
The example d$g won’t work in some systems as the $ symbol matches end of string. Likewise in some systems the clarett represents start of string so instead you use the ! Symbol
… and it’s never absolutely necessary.
PCRE for the win!
Without “grep -P …” I can’t hardly make it from bed to breakfast :^)
Then for extra whipped cream and cherry atop: named groups in Pythons re – yummy!
I know this is mainly directed at Linux, but there are plenty of great uses outside of strictly Linux, or even the command line generally.
Batch Rename Utility – Windows: This is one of the most brilliant batch file renaming programs I have seen. You can use a bunch of dialogs, but when that inevitably is insufficient, you can do search and replace with regular expressions. And you get feedback before the renaming is actually done.
KiCad – Win/Linux: Since KiCad saves all data in ASCII format, it is prime picking for regular expressions. I frequently use regular expressions to do things like change the size of text on the PCB silkscreen for only certain types of components. It is also helpful in editing fp-lib-table manually.
@Al_Williams – There are a couple of typos in the Grouping section:
* “(dog)|(cat)” should be “(dog|cat)”
* “a|b” should probably be “(a|b)”