Machine learning has brought an old idea — neural networks — to bear on a range of previously difficult problems such as handwriting and speech recognition. Better software and hardware has made it feasible to apply sophisticated machine learning algorithms that would have previously been only possible on giant supercomputers. However, there’s still a learning curve for developing both models and software to use these trained models. Uber — you know, the guys that drive you home when you’ve had a bit too much — have what they are calling a “code-free deep learning toolbox” named Ludwig. The promise is you can create, train, and use models to extract features from data without writing any code. You can find the project itself on GitHub.io.
The toolbox is built over TensorFlow and they claim:
Ludwig is unique in its ability to help make deep learning easier to understand for non-experts and enable faster model improvement iteration cycles for experienced machine learning developers and researchers alike. By using Ludwig, experts and researchers can simplify the prototyping process and streamline data processing so that they can focus on developing deep learning architectures rather than data wrangling.
Key to Ludwig is that it ships with a number of model architectures. You can add your own, but for many cases using the built-in ones will allow you to quickly get a model up and running. You don’t have to code, but you do have to build a YAML configuration file, which isn’t that bad. There are a number of known data types such as text and images and that helps simplify configuration, as well.
The post shows a simple example. A spreadsheet-like database containing books is the training data. It contains a book title, an author, a description, a cover image, a genre, and a price. The goal is to learn this dataset and then, for future data, predict the genre and price. The YAML file is really simple:
input_features: – name: title type: text – name: author type: category – name: description type: text – name: cover type: image output_features: – name: genre type: category – name: price type: numerical training: epochs: 10
You could make it more complicated if you wanted to select options. For example, by default, the text fields use a CNN encoder, but you could override that and pick RNN instead.
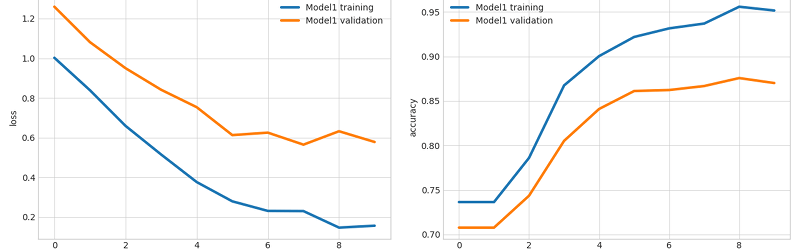
Ludwig itself is a command line program that takes a command line. The train command, of course, generates a model. The visualize command produces graphs for loss and accuracy. The predict command applies new data to the model. You can see a number of other examples on their website. If you decide you really want to write code, Ludwig exposes a Python interface.
If you decide to go further, you can actually run TensorFlow in your browser. You can even read our very own tutorial.














This makes me a bit nostalgic., perhaps showing my age. It takes me back to the excitement I felt reading books about LISP. I hope Ludwig has more staying power. There is so much more room for improvement.
The open source movement could have benefited LISP greatly.
LISP is still around tho. More and more features from LISP are being imported into modern languages as well.