
Given the accuracy of Moore’s Law to the development of integrated circuits over the years, one would think that our present day period is no different from the past decades in terms of computer architecture design. However, during the 2017 ACM Turing Award acceptance speech, John L. Hennessy and David A. Patterson described the present as the “golden age of computer architecture”.
Compared to the early days of MS-DOS, when designing user- and kernel-space interactions was still an experiment in the works, it certainly feels like we’re no longer in the infancy of the field. Yet, as the pressure mounts for companies to acquire more computational resources for running expensive machine learning algorithms on massive swaths of data, smart computer architecture design may be just what the industry needs.
Moore’s law predicts the doubling of transistors in an IC, it doesn’t predict the path that IC design will take. When that observation was made in 1965 it was difficult or even impossible to envision where we are today, with tools and processes so closely linked and widely available that the way we conceive processor design is itself multiplying.
Once Stratospheric Development Costs Have Become Merely Sky-High
In the past, innovation in computer architecture could be a risky move for a business to undergo, especially if there wasn’t any good reason why the industry standard had to be surpassed. At best, they could spend a fortune investing in R&D and output a game-changing design. At worst, they could tank their company and end up with a massive stock of unsellable units. While ideas like increasing cache sizes or buffer sizes could optimize one chokehold of an architecture, either the logistics of manufacturing or the costs of production can surpass these re-adjusted sticking points. Prior to VLSI, it would have been incredibly difficult to include as many processes on a single chip, and long wires between large components slowed down computation.

It is inarguable that with the democratized chip design by Mead and Conway and developments like RISC architecture, branch prediction, and the high-level programming languages that use them, the 1980s ushered in major innovations for computer architecture. It begs the question, where is the peak? Dennard scaling (a scaling law that states that as transistors get smaller, their power density stays the same, resulting in significant frequency increases) may have ended in 2006, and Moore’s Law looks to be breaking down in the near future, but with major industry support for faster computation in machine learning, and renewed interest in higher-level languages, domain specific architectures and custom-manufactured chips seems to be ushering in innovation for a different view of computer architecture. A focus on supercomputers and niche chips may help improve computation even faster than Moore’s Law predicts.
Uncorking the Bottleneck of Silicon Production
The new wave of Chinese semiconductor manufacturing is no secret — in 2014, The State Council of China issued the National Guidelines for Development and Promotion of the Integrated Circuit (IC) Industry, a national policy for improving the country’s semiconductor production. They increased investment, adopted a market-based approach, and focused on creating national champions through changes in industry revenue generation, production volume, and technological advances. With surging demand for Chinese smartphones (Huawei, Lenovo, Meizu, Xiaomi) and China-based consumer demand, there has been a lot of encouragement for improving manufacturing throughput.
While Chinese chip manufacturers may not be producing the most advanced architectural designs, they are still edging out competition in terms of the affordability and efficiency of their processes. Funding for nanoscience, cheap labor, and lower costs for factory maintenance and materials all contribute towards the lower cost of Chinese products, although there are also other manufacturers in countries such as Taiwan and Vietnam that are similarly providing cheap fabrication services.
To see how far silicon production has come it’s interesting to look at Application-Specific Integrated Circuits (ASICs) — chips designed to perform a particular set of operations better (in terms like power or speed) than a general CPU could.
In the 1980’s the manufacturing of ASICs was a process that required a separate designer and manufacturer since there wasn’t a direct link between third-party design tools and semiconductor processes. Since then the process for manufacturing custom chips has massively improved. The results are obvious. For instance, the popularity of Bitcoin mining drove many new ASIC designs, as specialty hardware would provide greater hash power at a lower price, which translates into greater profits from electricity. Companies like Halong Mining, Bitmain, and BitFury produced — and continue to sell — a flurry of mining hardware to Bitcoin hopefuls. Many realized that the capabilities of GPUs to process large amounts of visual data efficiently was closely tied to the resource needs of new algorithms, ASICs can do the same but at a lower cost and power budget. You can probably guess that the algorithms now driving the industry focus on machine learning.
Architectures for Machine Learning

In 2016, Google announced their commercial TPU, one of the first chips created specifically for the purpose of running machine learning algorithms. TPUs are used within the company for neural network computations behind products such as Google Search, Street View, Google Photos and Google Translate. Compared to RISC architecture, which focuses on simpler instructions that are used for a larger portion of applications (load, store, add, multiply), the TPU is based on CISC (Complex Instruction Set Computer) architecture, which implements higher-level instructions for running more complex tasks (such as many multiplies and adds for matrix multiplication).
Some other differences that mark the TPU as an improvement over CPUs and GPUS are the systolic array, deterministic design, and quantization choices. The systolic array mimics how the heart pumps blood since data flows through the chip in waves. For matrix multiplication, this is especially useful since the same inputs are reused many times without being stored back to a register. Wires only connect adjacent ALUs that performed fixed patterns of multiplication and addition, simplifying their design and shortening the wires needed.
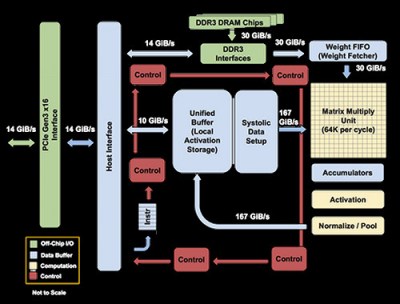
Deterministic design seeks to be ultimately minimal, with no requirement for supporting a wider range of applications than neural network models. Due to the nature of the chips, prediction is much more reliable since only neural network predictions are ever being run. Control is a lot easier to design than for CPUs and GPUs, and while more ALUs and on-chip memory are needed for TPUs, they tend to be smaller than other chips. This has the nice side effect of reducing cost (a function of area cubed) and increasing yield since smaller chips are less likely to have manufacturing defects.
Quantization uses an 8-bit integer for approximating a value given a max and min value. The technique helps reduce noise in calculations, since neural network predictions don’t require floating point precision with 32-bit or 16-bit values. Even an 8-bit value can suffice for the levels of accuracy needed, thus reducing the size of models quite dramatically.
There is also the matter of flexibility. Because the TPU is programmable, it is able to accelerate computations for many different types of neural network models. The computational resources used include a Matrix Multiplier Unit (MXU), Unified Buffer (UB) or SRAM working as registers, and an Activation Unit (AU) for hardwired activation functions. A dozen high-level instructions interface with these resources, such as multiplying or convolving with data and weights, reading weights from memory, and applying activation functions.
Microchips No Longer All That Micro
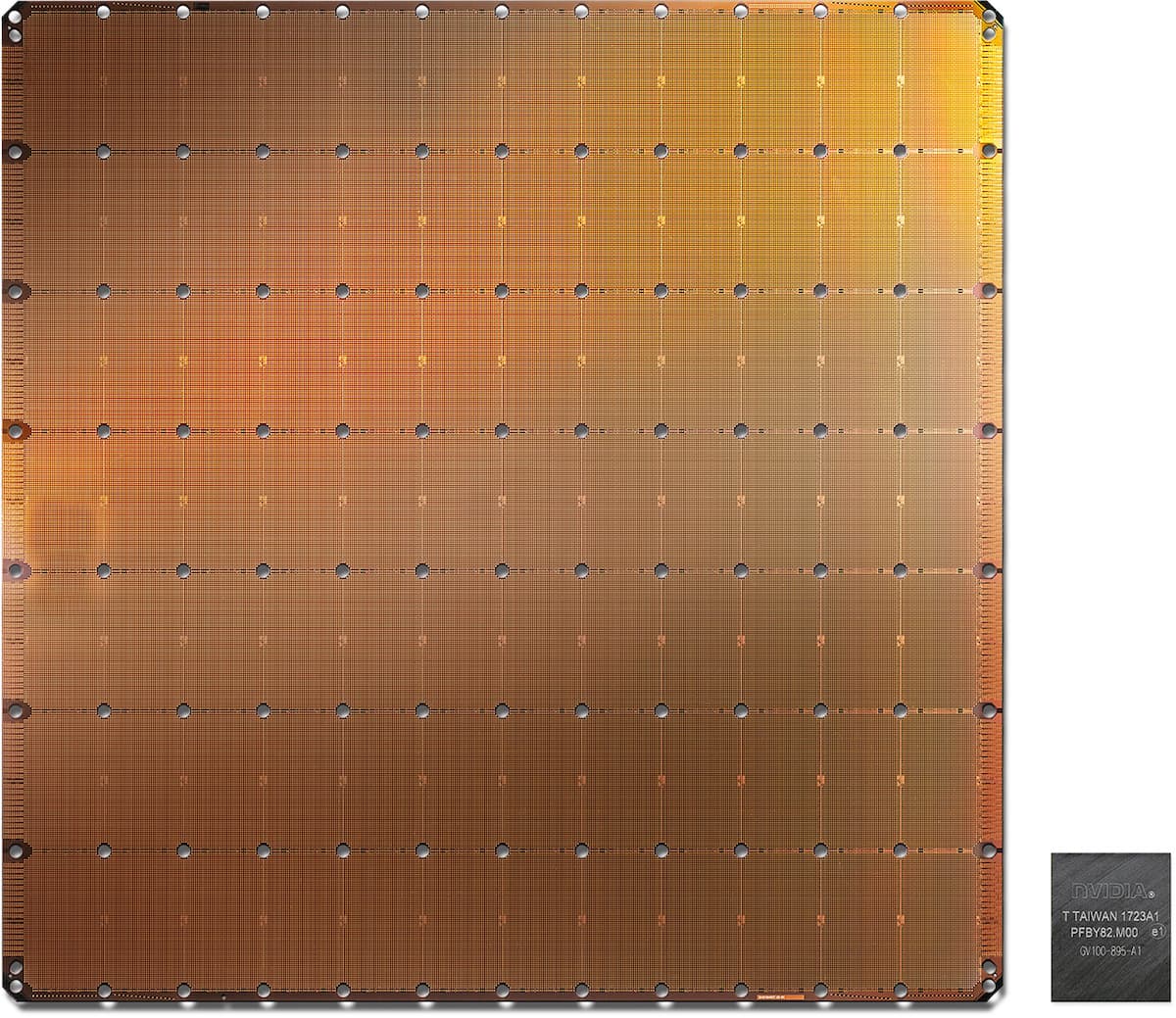
One of the most viral stealth companies, Cerebras, has been working on the largest silicon chip ever built. It measures at 46,225 mm2 of silicon, with 1.2 trillion transistors. Compared to the largest GPU, it’s nearly 100x the size. The chip is designed around handling tensor operations and moving around data more efficiently. With SRAM memory on the chip, it simplifies operations that would typically travel longer distances within a cluster to processes that can communicate on the same chip. While there are general operations supported for control processing, there are also optimized tensor operations for data processing. In terms of the materials inefficiencies involved with the high power consumption and heat generation, a connector layer between the silicon and PCB handle the mechanical stress created by thermal expansion while a cold plate transfers away heat from the wafer chip.
The chip boasts 1.2 trillion transistors, 400,000 AI optimized cores, 18 Gb on-chip memory, and 9 PB/s of memory bandwidth. Compared to the Nvidia GeForce RTX 2080 Ti GPU, with 18.2 billion transistors, 4,352 CUDA cores, 11 Gb on-chip memory, and 616 GB/s of memory bandwidth, it is clear that the Cerebras has massive improvements over even the best commercially available GPUs. What had once been a manufacturing nightmare has become a reality with improvements in silicon manufacturing.
An Ever-Changing Landscape
With Moore’s law constantly on the horizon, researchers are constantly on the lookout for new methods for reducing latency in computation. Concepts such as neuromorphic computing, probabilistic computing, and quantum chips are making their way from theory to development. Neuromorphic computing uses low-power artificial synapses to mimic the neural structure of the human brain, although matching human cognitive flexibility can be challenging. Quantum chips have an immense number of factors that must be controlled in order to maintain the integrity of the qubits — the quantum bits most commonly created by a Josephson junction (superconductors coupled by a weak link consisting of a thin insulating barrier).
Just as Dennard may not have been able to foresee multicore processors, Moore was likely unable to predict the advent of machine learning and its effect on hardware manufacturing. Even the most creative visions for the future of computer architecture will have a difficult time predicting just how far computing will go, and to what lengths new companies will take memory and instruction set manipulation to strive for ever-increasing speed in the coming decade.














Thank you for a great article. This subject would be an amazing talk at Grace Hopper next year. We have a hardware track and are looking for incredible speakers. The CFP will probably go out in January. Please apply. I would love to hear you speak.
This article touched on a wide array of topics, but it’s clear the author has only an enthusiast’s passing knowledge. Pretty divorced with how the internals of the modern semiconductor industry actually function.
Do more research.
I assume the Cererbras chip even has a yield by just disabling the units the defects fall on?
46,225 mm2 of silicon is exactly 215mm x 215 mm which would fit inside a circle of diameter 304mm which would be larger than one 300mm wafer. If you look at the image above the corners are curved so that it would fit inside a 300 mm slice. Which begs the question why would they not make the device circular and use the other ~ 24,460 mm2 (70,685.775 – 46,225). Is it because they would need a custom system for bonding wires to a circle or that the highest rate of faults would be closer to the edge ?
It is 10 to the power of 3.14 harder to cut circular chips than to cut rectangular chips from a brittle silicon wafer.
All litho tools currently in use are designed to expose dies of a certain maximum size. Those dies are rectangular because it’s A: Easy to process, B: fastest to expose accurately in a continuous process, C: the silicon crystalline structure is rectangular and is matched to the litho process orientation for the most accurate and consistent etching result
The Cerberus chip uses the same semicon equipment used for normal chips, it’s just a bunch of the same die exposed over and over, just interconnected on the wafer and not sliced/diced like a normal wafer would be. Hence the individual dies need to be rectangular.
If I do the maths with the information provided above (46,225 mm2 of silicon, with 1.2 trillion transistors) the individual transistors are at most the 196 nm square. If I also allow an extremely generous 2.5 mm for bonding wire connection pads along all sides, it is probably being produced at a 180 nanometer process, which would have a much lower failure rate, than the current bleeding edge.
Sorry, actually for a full transistors is going to be less than 180 nm, maybe 90 nm or possibly a 65 nm process.
TSMC 16nm FF.
hm, a bit smaller than I expected. Guess the research project had better founding than I expected.
Guess that 16nm had good enough yield, since the chip should be possible to build on 22nm, though, for CMOS logic, 16nm as some advantages.
I’m wrong and so are you!
https://www.extremetech.com/extreme/296906-cerebras-systems-unveils-1-2-trillion-transistor-wafer-scale-processor-for-ai
“The Cerebras WSE contains 400,000 sparse linear algebra cores, 18GB of total on-die memory, 9PB/sec worth of memory bandwidth across the chip, and separate fabric bandwidth of up to 100Pbit/sec. The entire chip is built on TSMC’s 16nm FinFET process. Because the chip is built from (most) of a single wafer, the company has implemented methods of routing around bad cores on-die and can keep its arrays connected even if it has bad cores in a section of the wafer.”
Sorry I thought you said 22 nm for some reason, I’m wrong.
Except, the feature size of a production node denotes the smallest single feature that it can produce. Ie a dot.
A transistor is far far more than just a dot. (Practically all transistors dwarfs the feature size needed to build them by a lot.)
And most chips, especially CPUs and GPUs needs to space out their transistors from each other for thermal reasons. Leaving a rather sizable amount of baren waste land between them. (In less active parts of the chip, like cache/memory, transistors can be more densely packed.)
But regardless, the chip is most likely not produced at the sub 20 nm nodes, and not on a node larger than around 65nm. My guess would be 22nm to 32nm, since there is a lot of such factories throughout the world.
Though, the yields even on the 22nm node has improved remarkably since the days that it were used by CPU makers. So it is likely sufficient to produce wafer scale integration, though might need to toss out 9 out of 10 wafers though.
But making a wafer and building a chip on it only costs a few dollars per square inch, so even an abhorrent yield of less than 5% is still not that bad for what will arguably be a very special and likely extremely expensive piece of equipment.
A fascinating read. Thank you.
Careful with the units there, a Gb isn’t the same as a GB. The RTX 2080 Ti has 11GB of memory, and I presume the Cerebras also has 18GB of memory, not 18Gb. It’s still quite a small amount of memory for all those cores, but with that much throughput they’ll probably use it on something with enough memory to make that up.
For embedded systems, the hardware is there; the software is nowhere to be seen.
Look at the pile of steaming turds that makes (pun intended) today’s commercial C compilers for the common and capable microcontrollers from and/or for PIC, ST, etc.
Probabilistic and quantum computing hardware will not find the future of humanity until we can make reliable code that harnesses the power of billions of distributed microcontrollers. Racks of centralized processors are evil and will only serve to further empower the googles, the microsofts, and the apples, and/or to further the power of the state.
Need more time and monies on our code tools – the hardware is already there.
The worst offender is the CCS “C” compiler. Never again.
Wow, who knew that weather forecasting is evil!
I suppose medical research is evil, too
Only if one’s a certain WW2 German doctor.
Hear hear, brian. The proliferation of different architectures and diffeerent locked down boards is tearing our community apart. the ratio of new developers over the amount of archetectures is such a low value that it’s preventing us from organizing.
I sometimes get the impression at some point we took a few missteps in hardware design that are now just “The way it’s done” and its subtly hampering us in countless ways.(and not *JUST* x86 with some obvious missteps) Imagine if cars had settled on a 3 wheel designs. They work and have some real advantages over 4 wheel designs after all right?
“Engineers like to solve problems. If there are no problems handily available, they will create their own problems. ” — Scott Adams
Google “Top Gear Reliant Robin” and see for yourself why 3-wheel cars are not at all advantageous. The “you can’t rock a tripod” adage might be okay for 3-legged stools and other things that sit still, but vehicles don’t sit still.
Rolling chairs have five legs.
https://www.osha.gov/SLTC/etools/computerworkstations/components_chair.html
Was discussing this with Josh at Supercon re: kinematic vs traditional design. Three points determine a plane, but five make for a nice wide base.
Your point is valid for any 3 wheeler with one wheel in the front. However, having the single wheel in the back with the other two out front for steering is actually quite stable.
That being said, we use 4 wheels because the shape of the space in between them is square, and beyond the fact that making accurate squares/rectangles is allot easier than triangles for the unskilled worker, the square/rectangle is the most efficient way to organize and utilize a given space. The maximum storage efficiency is achieved when using a cubic area in combination with items that are cube shaped.
That being said…. The interiors of most vehicles are not optimized for storage, instead opting for the safe conveyance of squishy meat bags.
But their offering running one’s Ai on those servers where they get a copy of your data, code and results….
Look at how many web sites now run only by using third party links/code/services. They’re giving/selling you away.
that comment was in reply to N who replied to Brian’s “For embedded systems…”.
wtf
Replies under a comment show/build under the comment, but post as a new comment. This used to work. What did you break.
>”The technique helps reduce noise in calculations, since neural network predictions don’t require floating point precision with 32-bit or 16-bit values.”
That depends on how faithfully you want to emulate a neural network, or do you just want to make a “neural” networks for the training/evolving of algorithms in a black box.There’s evidence that real neural networks use noise to maximize their information processing capacity, and vary their sensitivity cyclically to alternate between solving problems and implementing the solution (aka. brain waves).
https://igi-web.tugraz.at/people/maass/psfiles/166.pdf
https://www.wired.com/2014/05/criticality-in-biology/
>””You’ve got randomness, and you’ve got order. And right between them, you’ve got the phase transition,” Beggs said. “The idea is, you want to get as close as possible to chaos, but you don’t want to go into the chaos. You want to be on the edge, on the safe side.”
>”Beggs’ own research involves these avalanche behaviors in networks of neurons. These have been documented at small scales encompassing a few hundred or thousand cells, and also in large-scale, across-the-brain activity in organisms as disparate as roundworms and humans.”
>”It’s been proposed that these criticalities may underlie cognition — the extraordinary dynamics of memory formation and sensory integration and on-the-fly processing”
It was my understanding that neural-net training requires precision (e.g. floats at least), but after the training is done neural-net processing can work with very low precision (bytes or even booleans). Is training now done with low-precision values as well? Or is that only used for running already-trained models?
I think it’s worth noting that MS-DOS was far from the first computer operating system. By the time the product sold as MS-DOS and PC-DOS was developed, IBM had a far more capable DOS of its own for S/360 and later machines. And those machines had all of the features (and then some) that only recently have come to the personal computer.
Integrated circuits were not developed for miniaturization, they were developed for densification. Moore’s Law does not predict “speed”, it was an observation of the rate of densification of integrated circuits c. 1970. Today the word “microchip” usually refers to the little transponder that a vet implants into pets, so they can be identified if they’re lost. Although there’s no law of man or nature declaring that IC chips must be tiny, it is a fact that the circuits on them are much more compact than the same circuit if it was executed using discrete components.
I remember how excited academics were about RISC as an undergrad in the 1980s. The basic raison d’être for RISC was the notion that a lean CPU would be able to run at much higher clock speeds than a comparable CISC CPU. With many more simple instructions per second, the RISC CPU would be able to execute instructions that required multiple CPU cycles to complete on par with CISC, and execute single-cycle instructions much faster. It was also assumed that most tasks could be done with single-cycle instructions. RISC was a hit for education because the simplified architecture was easier for CS and EE students to grasp. What they hadn’t counted on was the rise of graphical user interfaces and using computers for multimedia. The imagined greater clock speeds never materialized, and outside of the classroom RISC had to get a lot more complex to keep up with new demands. Today what’s still called “RISC” uses SIMD, co-processors and other complex methods to restore power lost to the RISC dogma.
True. Except RISC-V. It’s really, really reduced.
Boston dynamics is doing the body, Cerebras is doing the “brain”, US Army will assemble both. T-800 in more near than you can image.
ARM machines (RISC) now changing the best.