
I once asked a software developer at work how many times we called fork() in our code. I’ll admit, it was a very large project, but I expected the answer to be — at most — two digits. The developer came back and read off some number from a piece of paper that was in the millions. I told them there was no way we had millions of calls to fork() and, of course, we didn’t. The problem was the developer wasn’t clear on the difference between a regular expression and a glob.
Tools like grep use regular expressions to create search patterns. I might write [Hh]ack ?a ?[Dd]ay as a regular expression to match things like “HackaDay” and “Hack a day” and, even, “Hackaday” using a tool like grep, awk, or many programming languages.
So What’s a Glob?
The problem is the shell also uses pattern matching and uses many of the same characters as regular expressions. The fork call? The pattern the developer used was fork*. This would be OK — maybe not great — as a glob if you were afraid there were calls that started with fork but then had something else following (like an exec call which might be execl, execv, or one of several others).
If the shell saw that pattern it would look for anything that started with fork and then had zero or more characters following it. But as a regular expression, the meaning is quite different. The pattern actually meant: the letters f o r followed by zero or more occurrences of the letter k. So for would match. So would fork. As would forkkkkk. Also things like forth, format, and formula. So the matching number was enormous.
Glob Survival Guide
Globbing is typically a function of the shell. When you enter something like:
ls a*
The ls program never sees the a*. Instead, it sees the shell’s expanded list of files that start with the letter a. Well, that’s not exactly true. If there are no files that match the glob pattern, then ls will see the text you entered and will probably print an error message that it can’t find a*. At least, this is the default behavior. You can modify what the shell does if it can’t find a match (lookup nullglob and failglob).
This is a good thing because it means programs don’t have to write their own globbing and it all works the same inside a single shell. There may be differences, of course, depending on the shell you use. You can, also, turn off globbing in some shells. In bash, you can issue:
set -f
You’ll probably find that frustrating, though, so undo it with:
set +f
The most common special characters for globs are:
- * – zero or more characters
- ? – any character
- [] – A class of characters like [abc] or [0-9]
- [^] – Negative class of characters
- [!] – Same as [^]
If you have filenames that have a year in them like post07-26-2020.txt, you might write the following globs:
- post*2020.txt – All posts from 2020
- post*202?.txt All posts from 2020-2029 (or, even, 202Z; any character will match)
- post0[345]*2020.txt – All posts from March, April, and May of 2020
- post[!0][01]*.2021.txt – Posts from October or November 2021
You can do a lot with a glob, but you can’t really do everything. Bash has other expansion options that can help, but those aren’t technically globs. For example, you could enter:
process post{01,02,03,11,12}-*2020.txt
However, that will expand, no matter if the files exist or not, to:
post01-*2020.txt post02-*2020.txt post03-*2020.txt post11-*2020.txt post12-*2020.txt
Then the shell will glob those patterns for actual file names. You can learn a lot more on the bash man page. Search for pattern matching.
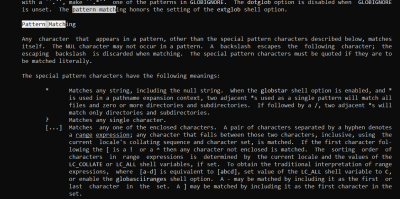
A Little Regex Syntax
Regular expressions are much more expressive, but also more variable. Every program that offers regular expressions uses its own code and, in some cases, it is significantly different than other programs. The good news is that the majority of regular expressions you want to use won’t be different. Usually, it is only the more obscure features that change, although that is little comfort if you hit one of those features.
The basic syntax is probably best represented by grep. However, if you are using something else you’ll need to check its documentation to see how its regular expressions might be different.
The biggest problem is that the * and ? characters have completely different meanings from their glob counterparts. The * means zero or more of the previous pattern. So 10* will match 1, 10, 100, 1000 and so on.
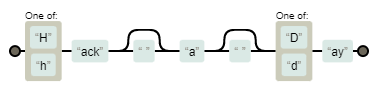
The question mark means the previous pattern is optional. So, 10?5 will match 105 and 15 equally well. For any character, in a regular expression, you use a period. So, going back to my original example, [Hh]ack ?a ?[Dd]ay you can see how this is not meaningful as a glob. The Regexpr website does a nice job of graphically interpreting regular expressions, as you can see.
Even More Confusion
To make matters even more strange, starting with version 3, bash offers regular expressions in scripting so you could have a script with both globs and regular expressions that are both going to bash.
Then there’s the fact that bash offers a different style of glob you can turn on with shopt -s extglob. These are actually closer to regular expressions, although the syntax is a bit reversed.
Learning Regular Expressions
I had thought about offering you a cheat sheet of common regular expressions, but then I realized I couldn’t do better than Dave Child so I decided I’d just point you to that.
Regular expressions have a reputation for being difficult, and that reputation is not wholly undeserved. But we’ve looked at ways to make regular expressions more literate, and if you need practice, try crosswords.














If you want a glob in your own program check out the function fnmatch(). It’s also not difficult to write a portable version for those of your not on a POSIX system.
Perl already has glob() natively :-P
yea, it’s a re-implementation of fnmatch with extensions. the original glob() probably was a call directly to fnmatch, but I’m no source code archaeologist.
Some languages (java and node js off the top of my head) have a hook for a filter function in their directory listing API, so that you can use arbitrary criteria to determine which files get included in the list.
Every linux user should keep a cheatsheet for bash, regex and vim to hand. They’ll soon become redundant for 90% of what you need. They’ll save you hours on the other 10%.
Alternatively, just one cheatsheet for emacs to cover everything. :D
We had a private dev IRC channel at work. After many messages from junior devs along the lines of, “Help! I’m trying to replace from using and it’s not working!”, a colleague wrote a regex testing bot to help. If the bot saw a regex pattern, it would attempt to match it against the previous few user messages, vi-style. The junior could enter their followed by their , and we could immediately see what matched and help with a different .
It soon became a game to see who could write the most elegant regex to turn the most innocent of IRC messages into a puerile joke.
I’m having Tacos for lunch
s/T.*f/your Mom f/
I’m so mad, I got into a shunt this morning
s/s.*a /a c/
Okay then, here come the relevant POSIX specifications:
Globs: https://pubs.opengroup.org/onlinepubs/9699919799/utilities/V3_chap02.html#tag_18_13
Regex: https://pubs.opengroup.org/onlinepubs/9699919799/basedefs/V1_chap09.html
Have a lot of fun!
PS: For more serious fun, try SNOBOL-style pattern matching.
There are sites (I generally use regex101.com) where you can past in regex to explain, build, plan, and verify a regex.
BBEdit’s find function can also use regex for both find and replace which I’ve found much more useful than websites. It also has a built in cheat sheet and allows you to save patterns.
So far I’ve found this and a good sturdy brick wall to bang my head against the only things I need to get through writing a complicated regex pattern.
“ If you have filenames that have a year in them like post07-26-2020.txt,”
… you should probably be using ISO standard dates instead, so they sort.
I do, but my users don’t always (or even often) ;-)
Also, globs being expanded by the shell is a fantastic gotcha when you actually meant to send a * or ? as part of a parameter.
That is true, but escaping with a \ is perfectly acceptable in shells. You can even escape spaces.
In fact it’s been a part of *NIX since even before UNIX existed: MULTICS supported them and Ken Thompson’s shell (pre-Bourne) in UNIX/UNICS copied it as it was what he and Ritchie were used to.
Of course, globbing wasn’t an asterisk because that was a system interrupt that killed the current program, and other oddities like # for backspace, and @ for line delete….. So there have been _some_ improvements to shells since then.
Backslash ( \ ) is your friend in that case.
What sane person puts dates in filenames with the year last? If you put dates in filenames they should be in YYYYMMDD so that numerical sorting rules apply. Thanks for coming to my TEDx talk, be sure to fill out a satisfaction survey on your way out today.
You must not meet many users.
For a good in depth read on the fine details of regexpen, check out O’Reilly’s “Mastering Regular Expressions”
https://www.oreilly.com/library/view/mastering-regular-expressions/0596528124/
There is much to be said for using Extended Regular Expressions in preference to obsolete Basic Regular Expressions.
The former are used by egrep, grep -E, awk, and any other modern utility. The most immediate benefit, apart from POSIX compliance, is that the old BREs often suffer from a backslash storm, as so much needs to be escaped in practice. That is bad enough when writing the regex, but infinitely worse when attempting to read one’s way through all the backslashes to the nub what is intended.
As
$ man 7 regex
says:
Regular expressions (“RE”s), as defined in POSIX.2, come in two forms: modern
REs (roughly those of egrep; POSIX.2 calls these “extended” REs) and obsolete
REs (roughly those of ed(1); POSIX.2 “basic” REs). Obsolete REs mostly
exist for backward compatibility in some old programs; they will be discussed
at the end.
Now if only Vim would ditch its mire of multitudinous regex syntaxes, and acquire
POSIX ERE perfection, the world would be a better place.