It is a classic problem. You want data for use in your program but it is on a webpage. Some websites have an API, of course, but usually, you are on your own. You can load the whole page via HTTP and parse it. Or you can use some tools to “scrape” the site. One interesting way to do this is woob — web outside of browsers.
The system uses a series of backends tailored at particular sites. There’s a collection of official backends, and you can also create your own. Once you have a backend, you can configure it and use it from Python. Here’s an example of finding a bank account balance:
>>> from woob.core import Woob
>>> from woob.capabilities.bank import CapBank
>>> w = Woob()
>>> w.load_backends(CapBank)
{'societegenerale': <Backend 'societegenerale'>, 'creditmutuel': <Backend 'creditmutuel'>}
>>> pprint(list(w.iter_accounts()))
[<Account id='7418529638527412' label=u'Compte de ch\xe8ques'>,
<Account id='9876543216549871' label=u'Livret A'>,
<Account id='123456789123456789123EUR' label=u'C/C Eurocompte Confort M Roger Philibert'>]
>>> acc = next(iter(w.iter_accounts()))
>>> acc.balance
Decimal('87.32')
The list of available backends is impressive, but eventually, you’ll want to create your own modules. Thankfully, there’s plenty of documentation about how to do that. The framework allows you to post data to the website and easily read the results. Each backend also has a test which can detect if a change in the website breaks the code, which is a common problem with such schemes.
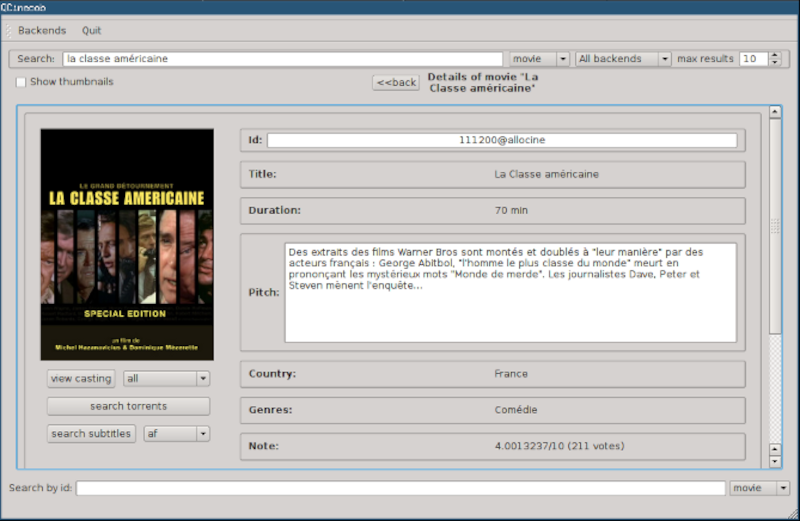
We didn’t see a Hackaday backend. Too bad. There are, however, many application examples, both console-based and using QT. For example, you can search for movies, manage recipes, or dating sites.
Of course, there are many approaches possible to this problem. Maybe you need to find out when the next train is leaving.














Well well well… I once made a HaD.io scraper but it was quickly broken by “updates” to the pages.
Considering I have > 100 projects, I would love to have a snapshot of everything.
From HAD TOS:
(e) introduce software or automated agents or scripts to the SupplyFrame Offerings so as to produce multiple accounts, generate automated searches, requests and queries, or to strip or mine data from the SupplyFrame Offerings;
So, STOP DOING THAT!
I am the author. This is MY DATA. And the goal is not to take the server down to its knee, I included random delays to prevent DOS.
BTW what does that mean ? ” introduce software or automated agents or scripts to the SupplyFrame Offerings” Do lawyers even know computers ? Is sending a HTTP request “introducting software” ?
C’m’on.
Correct me if I am wrong, but I believe the site is now under new ownership? Corporate presumably still haven’t got around to updating the ToS.
Knowing Hackaday/Supplyframe, I’d be surprised if there *wasn’t* an API. I just suspect it’s not public maybe?
It’s connected to Commodore 64 in Mike S.’ basement, though.
And was written by Benchoff.
There is an API, though not knowing what exactly YGDES is looking for, I can’t say if it has the necessary features or not:
https://dev.hackaday.io/
https://hackaday.io/project/8536-hackadump
I just want a mirror of my writings, files, comments and projects for offline backup and lookup.
I have contributed hundreds and hundreds of logs through the years and sometimes I have to search through obscure reference, for example.
And NOBODY can tell us that HaD will “never shut down or die”, from corporate, incompetence or malware to name a few eventualities.
What I would like to see/develop is a tool to read “Hackaday Offline”. If you had an API for the blog like the one you listed above for IO, that would be fantastic. End goal is to be able to “print” a weeks worth of previous articles at a time to a PDF that I can read from anywhere while offline.
Python is so good at doing this anyway. I need one for rust.
“Here’s a script I wrote… put your bank account info into it and it will do nice things for you. And let me update the script as I see fit…”
Nice project for non-sensitive data but a big fat watering hole target for financial info.
I was really excited about this but then I looked into how it works and each site is a python script. There are ZERO security measures taken to ensure a module can’t just steal your info.
Err, you could just do something crazy, like read the source?
“Un flim sur le cyclimse”
Frenchness intensifies…
Try the Hackaday RSS feed: hackaday.com/blog/feed/
Due to the limitations of RSS, it’s pretty much locked down in terms of ‘features’ and ‘upgrades’.
I like command line and ftp, guess I’m old!!
Or try Huggin…
https://github.com/huginn/huginn
Thanks for reminding me that I have StackStorm https://docs.stackstorm.com/overview.html on my wish list of tools to learn.