Here’s a history quiz: What architecture did the first C++ compiler target? Of course, it is a trick question. The original C++ — known then as C with classes — compiler wrote out standard C code that you then compiled for whatever your target was. This has a lot of advantages since C compilers are everywhere. Now we are seeing a similar approach to bring C23 to the world with Cake. Cake can translate C23 or other versions to C99 which you can then compile with normal compilers.
While the old C++ compiler, cfront, needed special steps to compile (since it was built using C++), you can build cake for Windows or Linux easily. However, it can also be built with emscripten and you can try it yourself in your web browser.
Curious about what’s new in C23? Well, some old stuff was removed and even more was deprecated. But the really interesting things are the additions which include decimal floating point types, integers with specified bit size, standard attributes, and many changes involving constants and initialization. You can find a summary over on cppreference.com. Of course, many of these things have been around in C++ or in common extensions for compilers for a long time, but this brings a lot of common practice together in standard C.
The only other thing to watch out for is that some features are really in the library. Compiling your code isn’t going to help with differences in libraries, although many of the changes are just bringing in functions that most libraries provide any way for things like POSIX compliance.
If you don’t want to dig around for an interesting example, the drop-down box at the top of the browser “playground” lets you pick among many examples. Just press the “Compile To” button and then you can compile the output to see the program execute.
The new standard does bring some complexity, but still nothing like C++. Why use C? Lots of reasons, not the least of which is that it is energy efficient.














I miss K&R C.. It was so easy to memorize, clean and tidy. *sigh* 😔
Unspecified behavior for integer overflow is not so tidy.
Why not? Signed integers should not overflow.
++!
…and have you seen B?
I’m the (main) maintainer for the only known modern cross-platform B compiler toolchain! And by ‘modern’ I mean that I ported the ABC open-source B compiler to work with the Amsterdam Compiler Kit, meaning that it’ll target anything that the ACK targets. So far there’s _working_ support for 8080, 8086, 80386, MIPS, PowerPC, and the VideoCore IV, but there’s a whole slew of other code generators which haven’t been made to work yet.
http://tack.sourceforge.net/
B’s a fascinatingly minimalist language. Sadly, it’s very much tied to the world where everything’s a sixteen-bit word, and it gets on very badly with 32-bit systems — B has a single data type, the word, which is used as both a pointer and an integer depending on context, and it’s defined so that adding one to a value increments the pointer to the next _word_. So it can’t address individual bytes. There are system libraries for string management that pack chars two-to-a-word. So, you’re basically SOOL if you want to access unaligned data structures on a 32-bit system.
Agreed.
I miss it too. As you say, easy to memorize, clean and tidy. Didn’t have the crowd around that feels they need high side boards to generate code good or bad ;) — they seem to come out of the wood work every time good o’ C is brought up :) and have to put in their two cents. Anyway, I notice I have to ‘reference’ documentation ‘a lot’ more often now when using C++, Rust, Python, C# or whatever OO language I happen to be using. Instead of simplifying, it actually has made programming a bit more complicated to navigate at times.
So after the 2037 epoch bug when do we get the 2 digit year versioning wraparound bug for programming languages, 2077?
The idea of the StackOverflow comments around “which C77 do you mean” is oddly terrifying.
Why were these useful time functions deprecated and what is the recommended work-around? I know these functions work properly, I use them.
From: https://en.cppreference.com/w/c/23
Deprecated:
asctime()
https://en.cppreference.com/w/c/chrono/asctime
ctime()
https://en.cppreference.com/w/c/chrono/ctime
Definition of Deprecated:
https://www.dictionary.com/browse/deprecated
Computers. (of a software version or feature) marked as not recommended for users and developers because of the risk of damage or compromised security, the existence of superior alternatives, or an impending upgrade.
Pffft… what superior alternatives, or impending upgrade?
The notes say “The C standard also recommends strftime instead of asctime and asctime_s because strftime is more flexible and locale-sensitive.” The same note is at ctime.
Read the docs? Each has another version, with _s, that is not deprecated. Same behavior, just writes to your own buffer (via standard c convention) rather than supplying it’s own. It says that the origional function is not thread safe, likely because it uses 1 global buffer for any call to that function, which is modified whenever you call it.
A lot less error prone to write to your own buffer under those circumstances.
Ah-so. I was focusing on the complex equivalents.Thank you [Nathan].
asctime_s() and ctime_s, whose big features seems to be an output buffer size specifier and output nullptr checking. These functions have been around since c11 too so they ought to be stable and proven
https://en.cppreference.com/w/c/chrono/ctime
“These functions have been around since c11…” Didn’t know that. I need to pay closer attention to these alternatives. Thanks.
POSIX has been calling them obsolete since 2018.
* https://pubs.opengroup.org/onlinepubs/9699919799/functions/ctime.html
* https://pubs.opengroup.org/onlinepubs/9699919799/functions/asctime.html
as for their replacements:
* https://pubs.opengroup.org/onlinepubs/9699919799/functions/strftime.html
* https://pubs.opengroup.org/onlinepubs/9699919799/functions/strptime.html
For some reason, strptime never made it into standard C while strftime is old hat. Either way, they will be on anything remotely POSIX.
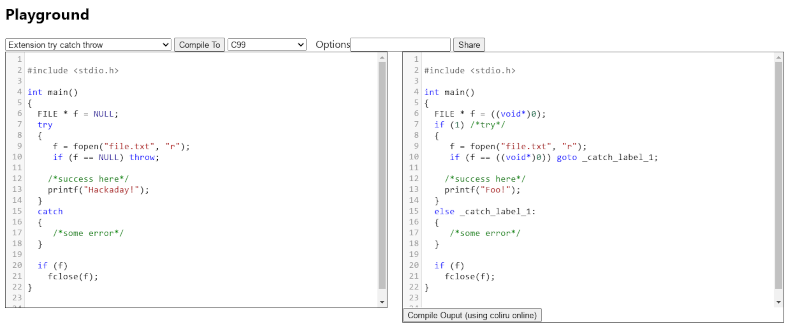
The example in the screenshot shows a try…catch statement, but I don’t see any mention of it in the linked C23 summary doc. Does anyone have more details?
It is a C extension, meaning unofficial support only.
It’s listed in the manual.md file: https://github.com/thradams/cake/blob/main/manual.md#extensions-not-in-c23
* go to: http://thradams.com/web3/playground.html
* select “Extension try catch throw”
there is of course https://github.com/guillermocalvo/exceptions4c which is macro based.
Bah, it’s just a thin wrapper around goto — I was hoping it was something with proper non-local jumps. Thanks!
Hmm. I am more interested in those compiler rules that turn the string “Hackaday!” into a string “Foo!”. Couldn’t find those rules in the docs either. :P
This seems to be specific transformaitons from Cake. See http://thradams.com/web3/manual.html#toc_26
the new #embed preprocessor directives seems to make including existing images, audio, … and other external data a lot easier.
No more python scripts or strange linker calls which change from platform to platform
usage example:
const unsigned char icon_display_data[] = { #embed “art.png” };
I’m not sure that’s good for C as a language. Breaking legacy code (due to deprecations and removals) and making the language more complex — this for me is the antithesis of what has been C’s success until now.
Let’s just hope this ‘committee’ don’t end up effing the language the way most ‘committees’ usually do.
If they do, I just hope compilers keep supporting the previous standards via a command-line option or similar, so whoever is inconfortable with C23 and newer can keep programming the way we’ve done over the last 40+ years and ignore the new ‘standards’
it’s true. and if you look at C99, they added some things like variable length arrays that made things more complicated (sometimes *much* more complicated), which no compiler ever actually properly implemented, which also never hoped to provide user value. otoh, a lot of the changes in C99 have been non-controvertial and a lot of them have been no-brainers (like va_copy(), stdint.h, etc).
C23 deprecating “non-thread-safe” interfaces built upon hidden memory buffers within the C runtime library is not a bad step. The new “thread-safe” (explicit allocation for return values) interfaces are not complicated. This isn’t going to join the list of things like locale support that made every libc balloon out to 10x its original size 20 years ago. in fact, though it will take decades to fully bear fruit, it will probably result in a slow erosion at the habit of a mess of #ifdefs around calls to unsafe functions to deal with host-specific hacks to achieve the same safe result. i know i personally can’t wait for pre-C99 environments that don’t support vsnprintf() to die out!
i can’t speak for all compilers but gcc -std=c89 etc isn’t likely to go anywhere. and if you think C hasn’t changed in 40+ years then you’ve successfully managed to ignore C99 and C11 already. in fact, you’ve probably used a lot of modern C99 features without recognizing them as novel or undesirable. and you know, if you get a warning for using something deprecated, i hope you know to google it to get rid of the warning, right?
anyways, as a compiler developer, speaking for myself, since C18 made VLAs “a conditional feature that implementations need not support”, i no longer view the standard committee as an antagonistic force.
“What architecture did the first C++ compiler target?”
I’m going to go x86 with Zortech C++ in 1988. At least it’s the first true C++ compiler that shipped on MS-DOS/Windows, and I don’t know of any earlier true C++ compilers.
“Of course, it is a trick question.”
Not really a trick question at all… (unless the trick is you are asking the wrong question on purpose, i.e. ask for “…first C++ implementation target” instead) For a long time C++ was a translated to C, after gaining some popularity proper C++ compilers start popping up which enabled better optimization.
I have been programming C for more than 20 years now. I still love it, but since the language is more than 40 years old, the age is showing. That’s why i started the C2 language (c2lang.org). It aims to be an *evolution* of C, not a completely new language. So the approach is just keep the good stuff of C and change the rest. C programmers should not feel alienated. The ‘biggest’ change is the discarding of includes and other intensive preprocessor usage. Every anti-pattern that I find in C programs is translated into something in the C2 language that solves this.
For example the #embed I saw above, C2 has (some standard) compiler-plugins you can use to translate a file / command into a variable available in your program. This allows for so much flexibility without becoming a mess.
A second change was incorporating the build system (eg make) into the language, since these are so intertwined and often cost so much time in a project. This allows some features like full program optimization with a single option, instead of a lot of work.
Sadly I feel the C standard committee is already making a mess of the new C standards.
To me it is especially the little syntax details that bothers me. For example, why are new keywords named ‘_Decimal32’ instead of straightforward ‘decimal32’ or maybe ‘decimal32_t’ which I would consider more consistent with the traditional C keyword syntax. The same applies for _Bool, _Complex, _Imaginary, etc.
I mean, look at this keyword mess:
“char, int, short, long, signed, unsigned, float, double, _Bool, _Complex, _Imaginary, _Decimal32, _Decimal64, _Decimal128”
Which should have been:
“char, int, short, long, signed, unsigned, float, double, bool, complex, imaginary, decimal32, decimal64, decimal128”
Please don’t start littering our standards with _X stuff for regular keywords.
Does the C standard committee simply not care about beauty nor consistency of the C language?
I believe that if you don’t care about such details you should not be in a language committee.
Well, I can’t speak for the committee, but my guess is they are trying not to break existing code any more than necessary. Think about it. You may very well already have code with Bool, Complex and maybe even Decimal32 as types. But I do wonder why the uppercase (_bool is as good as _bool). Or you could have a #include that says #define bool _user_bool and then code that uses the new standard shall not include that header. But I feel like that was the intent there. Not perfect, but nothing is.
Still I think they are doing it wrong – the C standard committee should prioritize new syntax, even if it breaks old code, to strengthen the C language and prepare it properly for the future. If they want developers to hang on to C then it needs to continue being a concise and beautiful language and not warp into a syntax mess like the new C++ standards have become.
They are already breaking code by deprecating stuff so people will have to go back and fix their old code regardless so lets stop doing half measure stuff and do it right. Also, there are ways to avoid breakage of old code even if they decide to make e.g. ‘bool’ part of the new C standard. Most if not all C library implementations follow the IEEE Std 1003.1 specification meaning that ‘__bool_true_false_are_defined’ will be defined and if so the compiler could simply undefine the ‘bool’ macro from and so the compilers ‘bool’ definition will be used instead without breakage. And even in situations where people are facing real breakage but are reluctant to fix their code, they can simply instruct the compiler to continue use an older C standard.
As a professional developer I would rather handle a little breakage of future standards than seeing my favorite language turn into an inconsistent syntax mess. I think the original creators of C would agree with this sentiment.