
Historically, one of the nice things about Unix and Linux is that everything is a file, and files are just sequences of characters. Of course, modern practice is that everything is not a file, and there is a proliferation of files with some imposed structure. However, if you’ve ever worked on old systems where your file access was by the block, you’ll appreciate the Unix-like files. Classic tools like awk, sed, and grep work with this idea. Files are just characters. But this sometimes has its problems. That’s the motivation behind a tool called Miller, and I think it deserves more attention because, for certain tasks, it is a lifesaver.
The Problem
Consider trying to process a comma-delimited file, known as a CSV file. There are a lot of variations to this type of file. Here’s one that defines two “columns.” I’ve deliberately used different line formats as a test, but most often, you get one format for the entire file:
Slot,String A,"Hello" "B",Howdy "C","Hello Hackaday" "D","""Madam, I'm Adam,"" he said." E 100,With some spaces! X,"With a comma, or two, even"
The first column, Slot, has items A, B, C, D, and E 100. Note that some of the items are quoted, but others are not. In any event, the column content is B not “B” because the quotes are not part of the data.
The second column, String, has a mix of quotes, no quotes, spaces, and even commas inside quotes. Suppose you wanted to process this with awk. You can do it, but it is painful. Notice the quotes are escaped using double quotes, as is the custom in CSV files. Writing a regular expression to break that up is not impossible but painful. That’s where Miller comes in. It knows about data formats like CSV, JSON, KDVP8, and a few others. It can also output in those formats and others like Markdown, for example.
Simple Example Runs
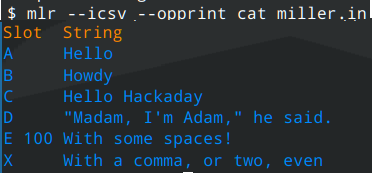
Because it knows about the format, it can process the file handily:
$ mlr –icsv cat miller.in
Slot=A,String=Hello
Slot=B,String=Howdy
Slot=C,String=Hello Hackaday
Slot=D,String=”Madam, I’m Adam,” he said.
Slot=E 100,String=With some spaces!
Slot=X,String=With a comma, or two, even
 Notice there is no command called “miller.” The command name is “mlr.” This output wouldn’t be a bad format to further process with
Notice there is no command called “miller.” The command name is “mlr.” This output wouldn’t be a bad format to further process with awk, but we don’t have to. Miller can probably do everything we need. Before we look at that, though, consider what would happen if you just wanted a pretty format output:
Not too bad! Don’t forget, the tool would do the same trick with JSON and other formats, too.
So Many Options
The number of options can be daunting. There are options to pass or ignore comments, process compressed data, or customize the input or output file format a bit.
But the real power to Miller is the verbs. In the above example, the verb was cat. These are mostly named after the Linux commands they duplicate. For example, cut will remove certain fields from the data. The grep, head, and tail commands all do what you expect.
There are many new verbs, too. Count will give you a count of how much data has gone by and filter is a better version of grep. You can do database-like joins, sorting, and even statistics and generate text-based bar graphs.
The filter and put commands have an entire programming language at their disposal that has all the things you’d expect to find in a language like awk or Perl.
What’s nice is that when you want to remove a field or sort, you can refer to it by name (like “Slot”), and Miller will know what you mean. There is a way to refer to fields with numbers if you must, but that’s a rare thing in a Miller script.
For example, if you have some data with fields “stock” and “reserve” that you want to get rid of, you could write something like this:
mlr --icsv --opprint cut -f stock,reserve inventory.csv
Or, perhaps you want to select lines where stock is “N”:
mlr --icsv --opprint filter '$stock == "N"' inventory.csv
Go Read
There’s simply not enough room to cover all the features of this powerful program. I’d suggest you check out Miller in 10 Minutes which is part of the official documentation. You’ll still need to read the documentation further, but at least you’ll have a good start.
Don’t get me wrong, we still like awk. With a little work, you can make it do almost anything. But if you can do less work with Miller, why not?














Great tool! I was just fighting with csv files recently, and I had to resort to a lot of regexes and other unholy string manipulations, due to quotes. In Python.
I’ve just used the ‘csv’ module that comes with Python. Works fine for all the use cases I have had to deal with. I suppose there are edge cases for ‘some’ csv files though. Just haven’t run into any.
If you can install a module and aren’t limited to whatever is natively supported, learning Pandas is just the best idea.
There’s a lot to learn, but for cvs it’s been the best part of helping my wife study data science.
The only regret is that I did it after I wrote an influx checking script. It would have saved so much time and effort. (and bad code)
Honestly, people are better off learning littler (command line R) with deplyr library, a tool that can easily parse csv and work just like perl or Ruby one liners
“Don’t get me wrong, we still like awk. With a little work, you can make it do almost anything. But if you can do less work with Miller, why not?”
Blasphemy.
Where was this when I was trying to convert my contacts list from my Motorola V60s to a modern smartphone. I had to play around with a comma-laden CSV file which I manually manipulated with a lot of search and replace functions from within notepad and word. I got the job done in about 4 hours, but it wasn’t fun.
MacOS install:
e.g. “brew install miller”
I know a lot of people that vehemently hate Microsoft are going to pile on here (although probably not as bad as they do in the El Reg comment sections), but I can say that PowerShell is absolutely great for dealing with these sorts of use-cases.
It’s certainly not going to help someone who wants a lightweight package to install on their favourite Linux distro (although you can install it if you’re happy to install .NET and the kitchen sink), but it Just Works™ on Windows – out of the box – so if you’re ever stuck in a Windows environment imposed by your IT overlords, give it a try 😉
In the meantime, I might just give this a try, as parsing structured data in Linux with bash, awk, sed, and friends is certainly a pain, and this seems like a good solution.
It’s not that bad.
https://woshub.com/install-powershell-core-on-linux/
No thanks. Why deal with PowerShell when you can install (the backwardly-named) WSL instead?
Because it’s *much* easier to do stuff like `Import-Csv some.csv | where Enabled -eq True | sort Surname | select GivenName,Surname,Enabled,UserID | Format-Table` than do the equivalent in Bash (even with Miller).
Having each item in the pipeline be an object with properties (and even methods) – versus a a flat string – means that when dealing with tabular/structured data, you only need one command to understand how to parse it, and then subsequent commands in the pipeline only have to deal with the already-parsed data, and can do things like filter on individual properties/attributes.
Whilst Miller certainly goes a long way to making this easier on Bash, it ultimately still depends on having its own internal “commands” that access the properties of the already-parsed data, as once it gets sent onwards down the pipeline, those commands are back to (re-)parsing strings again.
Honestly, give PowerShell a go: whilst you won’t have the same ecosystem of Linux commands at your disposal, you have a different one and nicer syntax (IMO) to boot. I know I much prefer curly braces over things like case/esac, and it’s nice to know you’re less likely to shoot yourself in the foot (or introduce a vulnerability) when using variable expansion.
Nice. I recently resorted to importing a CSV into google sheets when I couldn’t come up with a simple sed + cut pipe. It looks like miller would’ve done the job.
Nice!
And the package manager Homebrew knows about it. So on Mac OS, install with “brew install miller”, assuming you’ve installed Homebrew.
I usually import CSV/TSV files into a “real” database, like SQLite or MariaDB. They already are experts at parsing CSV/TSV. But often, you need to massage or adjust such files first, like excluding certain columns, fixing date formats, or getting rid of currency symbols and commas in numbers.
I used a Ruby CSV library, and it was fairly painless, but miller looks easier still!
LibreOffice Calc does give you some options when importing a CSV file, too.
There’s lots and lots of good, free (OS) CSV tools out there.
See “A carefully curated list of CSV-related tools and resources” here: https://github.com/secretGeek/AwesomeCSV
I’ve eagerly sampled some of those CSV tools, and my bad luck was to stumble across tools which were not written in the *nix stream-processing tradition of cut/awk/join etc — which were designed to process databases many times larger than the RAM on 64k PDP-11’s and such. One of the query CSV with SQL tools loaded the entire table into sqlite, which is a very clever way to re-use sqlite. But that doubles the disk required and is much slower than the equivalent awk program (when quoting isn’t an issue). Iirc another of the tools read the table into memory. Both were showstoppers for me. The Census SF1 database has thousands of columns and zillions of lines, and the FCC databases I process daily are no joke either. Luckily SF1 and many of the FCC tables contain no quoting so the old tools can work as is, but for the exceptions, a tiny program carefully unquotes them in a way compatible with both their future use and the old stream-oriented tools.
Oh, that’s a completely other world :)
I just needed tools to gather a few thousand CSV lines into a more readable format, not millions of lines:
So of course you’re right: the tool needs to fit the use-case!!!
I’ve been using App::CSVutils recently, and particularly appreciate csv-grep -H which allows me to implement some very complex row-selection logic very cleanly e.g; with first-class regexen.
Excellent article. I will use this! My favorite problem example missing from your article is when a data item within quotes in a csv file contains a line feed. That breaks all the classic process by line tools.
I am in agony over just that problem. How do you see Miller helping in that case ?
Rfc4180 allows line breaks in quotes access Miller claims to handle rfc4180 so… Test it and let us know!
For those using vscode (or its forks), there’s a nifty extension called “Rainbow CSV” that can do queries against CSV and TSV files with an SQL-like language, and have the query results output in either format.
https://marketplace.visualstudio.com/items?itemName=mechatroner.rainbow-csv
looks like a commady of errors.
I usually resort to python if I have to deal with complex csv’s or sometimes for JSON if I can’t get jq to work for me. I have really wanted another command line tool for this kind of problem and this sounds like it might be just the ticket.
VisiData is also something worth looking into. It’s an interactive terminal-based tool that supports numerous formats including CSV. It’s amazingly useful.
I recently asked ChatGPT to write me a python script which parses a text file consisting of fields separated by commas… etc ;)
Huh. The CSV file that I had handy was a KiCad-generated BOM file. Those are semi-colon separated, but miller has an option for that. It turns out there is a flaw in the BOM files. The header line is column title short compared to the data lines. I guess miller is a KiCad BOM lint tool.
I’m partial to Visidata (dot org), basically a terminal version of Excel that deals with any tabular data.
Miller is super cool. It’s worth checking out the source code too, It has a complete scripting engine (grammar,parser,compiler, and runtime) implemented for the scripty bits, well documented too.
Very cool!