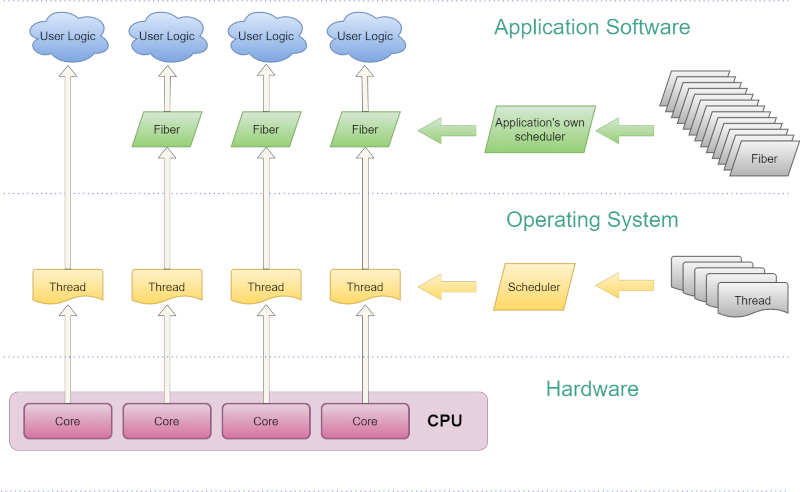
You’ve probably heard of multithreaded programs where a single process can have multiple threads of execution. But here is yet another layer of creating multitasking programs known as a fiber. [A Graphics Guy] lays it out in a lengthy but well-done post. There are examples for both x64 and arm64, although the post mainly focuses on x64 for Windows. However, the ideas will apply anywhere.
In the old days, there was a CPU and when your program ran on it, it was in control. But that’s wasteful, so software quickly moved to where many programs could share the CPU simultaneously. Then, as that got overloaded, computers got more CPUs. Most operating systems have the idea of a process, which is a program that thinks it is in complete control, but it is really sharing the CPU with other processes. The problem arises when you want to have multiple “little” programs that cooperate. Processes are not really supposed to know about one another and, if they do, there’s usually some heavy-weight communication mechanism allowing them to talk.
A thread, on the other hand, shares its variables and resources with other threads in the same process. In a multi-processor system, a program’s threads might run at the same time, or, in some cases, threads take turns running. For most cases, this is not a problem because many programs sit around waiting for some kind of I/O most of the time, anyway. But as [A Graphics Guy] mentions, video games and similar programs don’t work well with the typical thread scheduler, which tries to be fair and doesn’t really understand what the program is doing.
Another option is coroutines, where a program controls what is running (within its process). Some older operating systems worked this way. You ran until you decided you were at a good place to stop, and then you released to others, which is great until your program crashes, which is why you rarely see that at the top level anymore. Many C systems use longjmp as a way to let unrelated parts of the code switch between each other. C++ 20 introduced coroutines, too.
In fact, a fiber is an abstraction of this type of coroutine. In a practical operating system, a fiber works inside a thread, allowing the programmer to control their scheduling. Of course, the operating system still schedules among CPU cores, processes, and threads. But having, say, ten fibers will allow you to control how and when they execute better than creating ten threads and letting the operating system decide how they run.
The post provides an amazing amount of detail and compares fibers to C++ coroutines. Even if you aren’t writing games, the techniques here would be valuable in any sort of high-performance coding.
Of course, sometimes processes are all you need. There’s a lot to consider when you are multiprocessing.














Using C++ in general is like trying to slice bread with a toilet brush. I’d rather milk bulls instead.
The nice thing about C++ is that you don’t have to use all of it. You can strip away everything until you’re writing C, and then keep on carving away at it, add some setjmp(3) action, tell Djikstra to go self-service himself, and boom! you’re writing PDP11 assembly language with some convenience macros.
I mean, it’s an idiot move, but you can do it.
Agreed, some people shy away from difficult tasks. It’s the main reason I don’t use assembly or sling machine code anymore.
Telling people that their comment is bad is not helpful. Virtue signaling your intellectual superiority is really lame. We don’t need to know your opinion on someone else’s opinion, not everything is about you. Besides, his comment was funny. I took would rather milk a bull than dick around with c++.
Coroutines are very useful for embedded systems, though. Misbehaving routines do not pose any extra problems. Cooperative multitasking has big advantage that there are much fewer critical sections, which makes everything easier and often more efficient.
It’s not great at using more than one processor, but it’s great at allowing high usage without needing constant mutexes since you sync when making a ‘call’.
Agreed! For small systems, cooperative is the way to go. I like to think of it as the difference between opt-in vs opt-out.
With preemptive systems, your job is to find all the hidden race conditions, simultaneous access, and other foot-guns — and then to remove them all. (Does your system make atomic 64 bit read-modify-writes? YOU need to know!) And all of this while somehow solving the problem that you’re programming for in the first place.
With cooperative systems, you’re actively choosing when to swap contexts, so you are “never” surprised. Which means that you’re in control, and you know what’s going on all the time. Yield when you feel like yielding.
Coop is also easier to debug, in that you can tell which function you’re hanging in fairly easily because it’s all deterministic.
Honestly, it’s a freaking miracle that so many preemptive systems hold themselves together as well as they do.
Would it be fair to say that “fibers” are essentially non-preemptive threads?
This, and they are implemented in userspace, so that they don’t engage the OS for context switching. This makes them very lightweight and fast.
Linux implements threads in the kernel as regular tasks that just share some of the resources. An efficient implementation still makes them fast.
I came here to mention this as well. Unix from a very early era supported the fork() system call which launched a copy of the same program. Each copy shares some attributes and not others–this evolved as more and more attributes were accumulated by programs. Currently, the list is huge and keeping track of all the similarities and differences between two forked threads can be confusing.
To combat this (and to add features), Linux chose to implement a new system call function called clone(). It takes a bitmask which specifies what attributes the new process should share with the calling process. This allows you to implement fork() as well as many other different threading systems–which share or don’t share different sets of parent process attributes–just by passing a different bitmask of attributes to make unique to the new process. For example, you can share the same address space (or not), the same file descriptors, the same file change notification alerts, etc.
Some of the attributes support a COW (Copy On Write) nature in which the initial clone() requires very little to be done to spawn the new clone, but if either one ever changes the resource, a copy will be made and they will no longer share the same table/value/handle/etc. It’s a very efficient way of doing lazy cloning of attributes and it allows new process creation to be very flexable and fast as well as minimizing resource use.
Maybe I am reading it wrong, but these ‘fibers’ are just co-routines within a thread. The process thread is still preemptive, but the co-routines inside that thread simply cooperatively multitask within the thread context. Not a bad idea, just not sure where I’d use it (at this time).
I don’t think there are actually fewer critical sections; rather they aren’t necessarily highlighted. The developer simply does not yield to another fiber if otherwise in a critical section.
I’m wondering, coming from a rich embedded RTOS environment that has features such as event flags and the like, what problem this is solving? Typically I would be using 1 task per thread, and context switching is ~tens of microseconds. It it because Linux (large O/S) thread models are more heavyweight and the system calls for blocking are not as rich?
i am skeptical of the idea of generating new idioms for threads. it’s been my experience that if you really have tough requirements (like a videogame) then you will have to be very thoughtful about your scheduling needs. i often use the full range of pthreads or fork/SYSV IPC (or sometimes both!) idioms when i care. i’d love it if there was a way to simplify and generalize it but i just don’t personally believe it’s possible? or anyways i would be surprised to see much progress in an article submitted to hackaday.
so i started reading this article because if it does push it forwards, it would be very interesting to me, and i got this far before throwing up my hands in disgust…as a disadvantage of using existing thread scheduling idioms to wait on an input from another thread, it says “First of all, the OS has no idea when the inputs are ready”.
come on. there are so many ways — semaphores, pipes, sockets — for you to tell the OS that your thread is not doing a low-priority poll busy loop, but rather waiting for a specific resource. the OS *can* know when the resource is is ready. if your a priori problem statement is that none of the existing idioms exist, you can’t progress beyond them.
maybe i’m giving up too early but i didn’t read further. this reads as an undergrad with severe NIH syndrome and an abundance of ignorance. everyone starts from somewhere but not everyone produces useful output. two thumbs down.
I’m mostly likely nowhere near as proficient as you, and this is the immediate impression I got as well. Reminds me a lot of grads who were only functional in Visual Studio and couldn’t imagine constrained environments.
Almost like having classes structured around proprietary systems and their built in rhetoric had bad side effects.
In C# you have Task, Golang has go routines, C++ calls them coroutines. In Doom 3 the engine implemented “coroutines” but did not name them as such (I read an article when it went open source).
The Idea behind all of those implementations is to avoid switching Operating System code and User Space code.
Many Spectre/Meltdown mitigation implementations have made crossing this border expensive and it wasn’t cheap to begin with.
A “Fibre” is introduced as operating system concept but comparable to a coroutine. I am pretty skeptical we can use Fibres anywhere more effective then Threads or Coroutines … but who knows.
I am skeptical to call “fibers” a new idioms lol
Fibers are not meant to replace threads in any way but instead are useful in a form of cooperative scheduiling (-> waiting) whereas a fiber can inform the scheduler that it is stuck and has to wait, but it’s not limited to that.
Fibers have a few major advantages:
– the stack required for a fiber can be fine-tuned, if you need 10000 fibers and your stack will never grow over 64kb, you will waste much less memory (vs the 2 or 8mb used as default stack size)
– fibers both combine the best of threads and thread pools where you can have a “thread like” implementation but without the overhead of having 10000 threads but instead having just a few that are handling the job underneath, with a threadpool you have to re-arrange the logic of your software to pass around the context which is not required at all with fibers
– even when you use threadpool you use a “sort of” fiber in modern languages, infact all the “async” operations are implemented with coroutines that are a “stackless fiber” (or you can read the fiber as a “stackful coroutine”, up to you)
Fibers, for example, are one of the things that allow cachegrand to provide super low latency even with tens of thousands of connections active where each connection has a fiber, allowing a much simpler business logic.
But as everythingm fibers are a tool, they have downsides as well, and should be used being aware of pros and cons :)
Fibers all the life, that’s what I used as base for cachegrand ( https://github.com/danielealbano/cachegrand) to make it that faster, together with other things :)