
It’s becoming somewhat of a theme that machine-generated content – whether it’s code, text or graphics – keeps pushing people to their limits, mostly by how such ‘AI slop’ is generally of outrageously poor quality, but as in the case of [Vincent Driessen] there’s also a clear copyright infringement angle involved. Recently he found that Microsoft had bastardized a Git explainer graphic which he had in 2010 painstakingly made by hand, with someone at Microsoft slapping it on a Microsoft Learn explainer article pertaining to GitHub.
As noted in a PC Gamer article on this clear faux pas, Microsoft has since quietly removed the graphic and replaced it with something possibly less AI slop, but with zero comment, and so far no response to a request for comment by PC Gamer. Of course, The Internet Archive always remembers.
What’s probably most vexing is that the ripped-off diagram isn’t even particularly good, as it has all the hallmarks of AI slop graphics: from the nonsensical arrows that got added or modified, to heavily mutilated text including changing ‘Time’ to ‘Tim’ and ‘continuously merged’ into ‘continvuocly morged’. This makes it obvious that whoever put the graphic on the Microsoft Learn page either didn’t bother to check, or that no human was involved in generating said page.
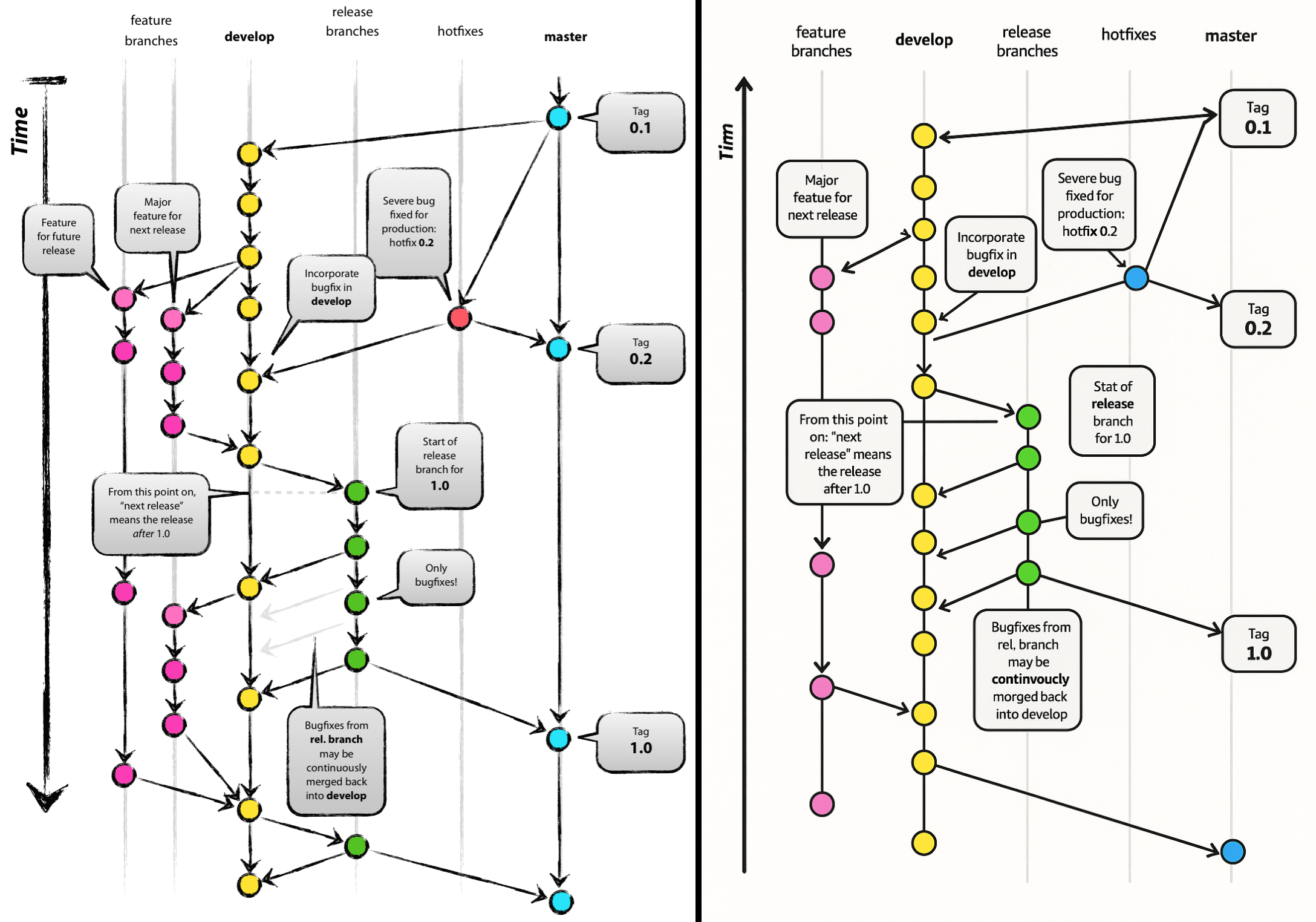
It definitely gives a dystopian ‘Dead Internet’ vibe where the fruits of past labor are being cynically regurgitated and spat out in the form of AI slop that bears little resemblance to the original, and should send real humans either running off in abject terror or fall over in uncontrollable laughter.
Even if this output was the result of [Vincent]’s original graphic getting scraped and shoved struggling and screaming into a diffusion model’s training dataset, there are so many dead giveaways that it was based on this original: from the text blurbs, to the use of the label ‘feature branches’ that’s retained in the reproduction even though the second feature branch has been trimmed.
All of this raises many uncomfortable questions about copyright in the context of both large language models and diffusion models, with cases like these making it clear that sometimes substantial elements of copyrighted works are being reproduced nearly verbatim. Depending on the associated copyright license, this can result in very expensive copyright infringement lawsuits, with some of these already working, or having worked their way through various courts pertaining to primarily stock images and books.
And to think that all that Microsoft would have had to do here was to check with [Vincent] for the license on the graphic if they had wanted to use it. As [Vincent] indicates, he would have been more than happy to do so if a backlink and credit was provided. This obviously is the human way to do things, where a human contacts a fellow human being to inquire about their thoughts on a topic, or peruses the works by fellow humans to find something to their liking prior to contacting said human with a usage question.
In this era of ‘just ask the machine’ by mashing in a query on a prompt, it would seem that this particular case will be far from the last one. The cynical take here is that the value of human output has been reduced to mere training data for the content machines, but maybe Microsoft will surprise us here with a tearful apology and real actions to prevent such events from ever happening again.














A missed opportunity for good publicity. How cool would a “Microsoft Acknowledges Mistake, Apologizes” headline be?
Sadly lawyers very strongly recommend not doing this.
Sucks, but they’ve turned apologies or even acknowledgements of mistakes or problems into a legal minefield.
I’ve recently been advised that I shouldn’t even say a particular issue was fixed, as doing so would make us liable for the issue…
Indeed. I remember one incident where someone discovered a significant bug within Windows that caused it to repeatedly crash. When reported to MS… they came back and called it a “feature” … acknowledging it as a bug would mean they would need to fix it.
In the 51st US state (Canada), it is explicit in the traffic code.
Apologizing is not admitting fault.
If that wasn’t the law, their courts would grind to a halt.
Everybody would be at fault, including the cop and the judge.
The story of such things go way back.
In the Chris Craft’s “Flight: My Life in Mission Control” he mentions that the makers of the redstone rocket refused to let them know the list of known issues, lest their reputation would go bad and pentigon would quit ordering their rockets. Trying to explain them that the redstone rockets are to be used for human flight didn’t convince them to open up either.
I also recall how US car makers refused to add safety belts lest public thinks their cars are unsafe to drive. Same logic there.
It will never happen in a bajillion years. The heat death of the universe will occur before microsoft admits to anything, let alone apologize for thinking everything in existence is theirs by default.
“Software engineer”…its all so tiresome
It’s
Isn’t there a AI copyright lawsuit going on around them anyway?
And what happens when the next generation AI “learns” from the incorrect diagram and adds its own mistakes and halucinations? Seems like a downwards spiral to me.
And what happens when the nest generation Al “learns” from the inconnect diaphragm and pads its own mistakes and halucinations !? Sam like a downwards stairway to me.
Band hat happens when the best generator AI “learns” from the Kinect diaphragm and pads it’s won mist steaks and hallucinations!?! Sam lork a downwards stairwell tome.
“Send three-and-fourpence, we’re going to a dance.”
(For those confused: the above is the classic example of “chinese whispers” mangling a phrase through repeated hearing > misunderstanding > regurgitating cycles. In this case in a military context, where the original phrase from the apocryphal front-line unit was “send reinforcements, we’re going to advance”)
If this wasn’t one person posting on multiple aliases, you all win the internet for today.
This was indeed random and I love it !!
Well, have you ever had to do calculations on the propagation of uncertainty? The answer to this question is worse and worse outcomes.
I saw a funny video where someone had a picture of a meme then asked chat gpt to redraw the picture making zero changes about 100 times. In the end it was a completely different image and I think north koreas leader was in it.
Worse than that.
These errors are non-linear.
What is the first derivative of ChatGPT with respect to accuracy?
Noise.
This is more like modeling noise than measurement error.
What is ChatGPT’s signal to noise ratio?
What was the training dataset’s?
IIRC it is impossible (observed in the data, but unexplained) for a neural net to increase that ratio.
Error rate is on the order of log of the neural net’s size.
If you own Nvidea stock, take profits and run.
This is already an issue. AI trained with bad data, spread misinformation. Throw hallucinations on top… Later AI train on this and compound the errors.
ai has an opinion. nothing less, nothing more. sometimes its easier to ask a random person.
AI has an opinion in the way a trained monkey has an opinion.
That’s a little unfair to trained monkeys, which at least have memory and awareness of their surroundings, and can have valid & meaningful opinions on such things as “do you want a peanut?” or “how many fingers am I holding up?”.
Perhaps a better comparison would be a Magic 8-Ball? That latter has no comprehension of the rote phrases it spits out non-deterministically.
No opinion possible. That’s a human trait. It is simply computed output from a computer.
No? Only less.
GenAI is just a search engine.
A fancy one. And one that has been massaged and prodded by HUMAN engineers for opinionated reasons.
But it has no more opinion than…
f(x)=2[absolute (x)]+5
I remember that article, designed my own repository structure based on those ideas… A recommended read for anyone developing and maintaining multiple versions of a software in parallel.
Oh please… that original graphic was released as CC-SA. Creative Commons share alike. Ah HAH I can hear you clicking your gotchas now.. there was no attribution given! Doesnt have to be. That license has a Fair Use exception where those provisions don’t have to be followed. Fair use is defined according to the Copyright office to include:
“Under the fair use doctrine of the U.S. copyright statute, it is permissible to use limited portions of a work including quotes, for purposes such as commentary, criticism, news reporting, and scholarly reports. ”
Scholarly reports according to the “Fair Use Index” of the Copyright Office includes uses such as: factual work, technical articles, and inclusions are unlikely to adversely effect the existing economic marketability of the originators work. Pretty sure that author wasn’t gonna be making a lot of bank of his self admittedly ‘morged’ article from 15 years ago.
..and wanna claim it wasn’t fair use? Absolutely excited to hear it. Take Microsoft to court to make that case. I’ll wait. .. on second thought, no I wont.
In some ways that actually makes it worse. Why put it through an AI to generate nonsensical garbage when the author of the original has pretty much already given you permission to use it directly? That’s like putting an open source software package through an AI to make it different before integrating it into your project rather than just using the original. Why would you do that?
That’s because the AI isn’t allowed to copy from source or quote directly to avoid copyright issues, so if you ask it to generate you an article it will generate everything that goes in it.
Someone didn’t check the output and just shoved it along, out the door and not my problem anymore.
Microserf was gaming ‘Ranking and Rating’, which encourages ‘phoning in’ actual work.
So as to not distract employees from politicking.
Didn’t realize that ‘publicly embarrassing the company’ was an exception.
Even an female brahman is fired for this.
Unless she can pin it on someone.
haha i actually agree with your thrust — it’s a non-violation, just embarrassing garbage. But on the details, i am going to present a different view…
Microsoft generally claims copyright on MS Learn documents, so i don’t think it satisfies CC-SA. It isn’t share-alike.
And it certainly is not fair use! That’s ridiculous! The point of fair use is so you can talk about the original document, not so that you can reproduce the original document for its original purpose but under your headline!
Absolutely not fair use.
But the catch is that this would have to be demonstrated, at some expense, in court.
All I see is button candy.
😆
Other than the spelling mistakes and malformed arrows, I like the MS one better. It’s much cleaner and easier to follow.
Speech balloons and fake “ink” lines – which are clearly just scaled copies of the same “random” texture – make it neither more readable nor aesthetically pleasing. To me it screams “pretentious programmer ‘art’.”
The surprising thing is, the AI slop version has a visual formatting error…the blue circle in the lower-right isn’t centered in relation to its arrow! Usually it’s been my experience that AI slop gets the fine shape right but forgets its meaning in relation to the whole. So there’s a new flaw to watch for i guess.
Total aside, i can’t even glance at this without thinking how great it is that git really truly solved the partial merge problem. You can have two branches that intermittently track eachother or cherry pick from eachother and rarely merge and re-diverge, and mostly it all ‘works out’. Just so cool!
This fits right in line with Microsoft. The other day it was discovered they had an article up about training LLMs, and they suggested to use – and linked to pirated copies of – all 7 Harry Potter books as an example of good training material. There was a story over on Hacker News about it, and as the above, there are links to an archived copy.
Corporate protest against the author?
since I absolutely despise the workflow being depicted, I say…let them fight XD
What are the telltales that AI did this, and not a human pirate? I would expect AI to at least get the spelling correct, whereas a non-English speaker who neither understands nor cares about the content could come up with that. I honestly don’t know what to look for.
It’s so close in appearance to the original. What human would do that?
If one doesn’t care or doesn’t believe they will get caught copying they could just use the original image as-is. Especially if they are too lazy to even get the spelling right. (could have achieved that by simple copy-paste!)
OTOH if they are trying to not get caught. they would make it a lot less obvious by making it look less like the original.
If that hasn’t convinced you take a cue from TFA and look at the arrows. Some are missing their heads, but worse one of them is backwards, clocked wrong and pinched! Who makes an arrowhead like that besides AI?
And check out the m in “Tim”[Time]. What human makes that mistake? I think that’s a good reason to always ask the AI for the graph in the form of an SVG. At least it can’t hallucinate the alphabet when generating ASCII (or UTF8) text!
I’m reminded of a diagram that I asked an AI to create for me as an SVG the other day. And no.. it wasn’t slop nor infringement. I was very detailed in describing what wanted in my diagram and it was describing a particular local environment that I was working on which would not match any common charts on the internet. I continued to request tweaks until all the dumb bugs were fixed. I think there might have been one or two small things that I fixed directly in a text editor at the end to finish it.
Anyway… I think it was the second iteration… all the arrows had reversed heads. I guess arrows are a common problem for AI.
AI will usually get the spelling right when you ask for text. (Which is a good reason when asking for a non-photo image to ask for an SVG).
Clearly this was handled as bitmap all the way. AIs hallucinate all sorts of stuff when you ask for text in a bitmap. It’s like asking your subconscious mind to picture a graffitti covered wall without focussing on the content of the graffiti. You get something that looks and feels familiar like text but isn’t actually accurate.
“… or that no human was involved in generating said page.”
Or, more realistically for Microsoft, no human capable of speaking English.
Which humans aren’t “capable”? And why don’t you like them?
Seeing such a debated subject I just scoll up to see how long it takes me to reach the end. I’m getting better predicting the articles having this feature.
Regarding AI, I hope for Asimov’s three laws one, but I brace for impact for Terminator style outcome.
I’l see myself out. As long as the trees are full of singing birds and the air is not full of radioactive dust.
“continvoucly morged” so that’s where all this zoomer brainrot slang came from
for how many ia compaies could be bankrupted by ai?
AI Overview
Up to 95% to 99% of AI startups could fail or face bankruptcy by 2026-2027, driven by unsustainable business models, high infrastructure costs, and a lack of clear return on investment. Research indicates that 95% of businesses implementing AI are not seeing a return on investment, threatening the viability of numerous AI-focused ventures.
Reddit
Reddit
+7
Key Factors Driving Potential AI Bankruptcies:
The “Wrapper” Problem: Many AI startups are merely “prompt pipelines” built on top of GPT, lacking proprietary technology (IP) or sustainable, independent business models.
Massive Cash Burn: Even major AI firms are struggling, with reports showing massive losses—such as OpenAI, which lost $5 billion in 2024, and Anthropic.
High Operational Costs: Training models and running AI services cost billions in infrastructure, with $3 trillion in AI infrastructure spending expected through 2028.
Market Saturation & Lack of Demand: About 38% of AI startups fail because they launch products without market demand.
Uncertainty and Risk: 56% of companies now list AI as a risk factor, highlighting potential for financial losses from compliance issues or poor implementation.
NPR
NPR
+5
The current situation is frequently compared to the dot-com bubble, with analysts warning that if AI investment does not yield significant revenue, a massive, industry-wide correction is likely
AI Overview
Yes, there is significant scrutiny and debate among analysts regarding “circular” investing, or “circular financing,” involving Nvidia, Meta, AMD, and other major AI players (such as OpenAI, CoreWeave, and Microsoft).
Wikipedia
Wikipedia
+2
These transactions, described by some as “vendor financing” or “hot potato” passing of capital, involve tech giants investing in each other, or in startups, which then use that same capital to purchase AI hardware and cloud capacity from the original investors, creating a “loop” that boosts revenue figures for companies like Nvidia and AMD.
CTech
CTech
+2
Key Aspects of the Alleged Circular Buying:
Nvidia-OpenAI-CoreWeave Loop: Nvidia has committed to investing heavily in AI firms like OpenAI (up to $100 billion in potential, though modified). These firms then use that funding to buy Nvidia GPUs and use services from AI cloud provider CoreWeave, in which Nvidia is also a major investor.
AMD-Meta Deal: In February 2026, Meta announced a massive, multi-year deal to buy AI chips from AMD (up to 6 gigawatts of processors), valued in the “double-digit billions”. This, along with Meta’s massive, continued spending on Nvidia hardware, is part of a broader,, interdependent AI ecosystem.
“Cloud” and “AI” Interdependence: Hyperscalers (Meta, Microsoft, Amazon) invest in AI startups, and in turn, those startups spend heavily on the hyperscalers’ cloud services to train models, creating a closed-loop system that drives, and potentially inflates, reported revenues.
CTech
CTech
+9
Why Concerns Exist:
Analysts argue that these deals, while not inherently illegal, can distort the reality of true market demand for AI chips and infrastructure. If the revenue growth in the AI sector is driven primarily by this circular flow of capital rather than by independent, profitable, real-world applications, it could resemble a bubble, similar to the telecommunications infrastructure bubble of the late 1990s.
J.P. Morgan
J.P. Morgan
+3
Counterarguments:
Some observers, however, defend these arrangements as necessary and logical for the rapid build-out of AI. They argue that this “capital-intensive” model is the only way to quickly secure the necessary hardware and infrastructure for cutting-edge AI. These, say defenders, are long-term, structural investments, not merely “round-trip” transactions.
J.P. Morgan
J.P. Morgan
+3
As of early 2026, despite these debates, the companies involved—Nvidia and AMD—have continued to report record-breaking revenue based on these huge, collaborative, and, to many, concerning, capital expenditures (CapEx).
Futuriom
Futuriom
+1
How Circular Financing Is Fueling the AI Boom | Built In
Feb 24, 2026 — Circular Financing Is Quietly Fueling the AI Boom. Here’s Why That Could Be a Problem. Billions of dollars are changing hands betw…
Built In
The circular economy of AI: How big tech is financing itself
Nov 10, 2025 — Microsoft, Nvidia, and OpenAI are investing in each other’s promises, a trillion-dollar loop that may not survive its own momentum…
CTech
AI bubble – Wikipedia
The AI bubble is a theorised stock market bubble growing amidst the AI boom, a period of rapid increase in investment in artificia…
Wikipedia
Show all
AI Overview
In the context of the current AI boom, cloud computing is central to “circular buying” (often called circular financing or vendor financing), where technology companies, chipmakers, and cloud providers invest in each other and use those funds to buy products from one another in a self-reinforcing loop.
Built In | Tech Jobs
Built In | Tech Jobs
+2
Cloud computing serves as the primary mechanism for this cycle by acting as both the service being purchased and the platform enabling the financial feedback loop.
YouTube
YouTube
+4
Key Roles of Cloud Computing in Circular Buying
Closed-Loop Financing (Vendor Financing): Cloud providers (e.g., Microsoft, Amazon, Google) and chipmakers (e.g., Nvidia) invest in AI startups (e.g., OpenAI, Anthropic). The startups then use that same capital to purchase high-end GPU hardware and cloud infrastructure, often from the original investors.
Revenue Generation and Valuation Inflation: The cash invested by a cloud provider returns to them as revenue for cloud services (e.g., Azure or AWS) and hardware. This allows companies to book massive revenue, which in turn boosts their stock prices.
Long-Term Capacity Commitments: Circular deals often involve long-term contracts where AI companies commit to buying billions in cloud capacity, ensuring steady revenue for cloud providers.
Infrastructure as a Service (IaaS) Enabling Scaling: Startups use rented cloud capacity to train models, allowing them to scale quickly without upfront capital, which is funded by the investments from the providers themselves.
Fortune
Fortune
+6
Examples of Circular Cloud Ecosystems
Microsoft-OpenAI-Nvidia: Microsoft invests in OpenAI, which uses those funds to purchase Azure cloud services and Nvidia GPUs. Nvidia also invests in OpenAI, creating a tighter loop.
Nvidia-CoreWeave-OpenAI: Nvidia owns a stake in cloud provider CoreWeave and guarantees to purchase its unsold capacity. CoreWeave then uses Nvidia chips to provide cloud services to companies like OpenAI.
Amazon-Anthropic: Amazon invests in AI startup Anthropic, which in turn signs long-term agreements to use Amazon Web Services (AWS) as its primary cloud provider.
Noahpinion | Substack
Noahpinion | Substack
+4
Why This is Considered “Circular”
Critics refer to this ecosystem as a “financial ouroboros” (a snake eating its own tail) because the same capital flows through interconnected parties, generating revenue at each point. While this drives rapid innovation and growth, it also raises concerns about artificial demand and the creation of an AI bubble.
LLVM a bad idea?
Are low-cost, low-power Nanocomluters with terabyte+ low-cost memories using
FIG Forth Intel 8080 hardware/software portability technology going to win?
Albert Gore and Allah, willing. of course.