
The world of software has seen many paradigms come and go, all of which were supposed to revolutionize its development. Still, one of the basic tenets in engineering of there being no shortcuts to just doing the work properly also rings true in the field of software engineering: trying to skip ‘nice to haves’ like proper documentation, code formatting, and proper testing inevitably results in developers nervously trying to ignore the looming avalanche of technical and other project debts as they keep piling up.
While Test-Driven Development (TDD) once got praised as the silver bullet, the principle of writing tests before writing code merely postpones the inevitable project collapse. The elephant in the room is that you cannot pass on the basics in engineering and expect to come out fine on the other end. There’s a reason why phrases like “all tests green, successfully failed in production” have become common.
This is where the concept of Comment-Driven Development (CDD) comes into play. What started as a bit of a joke many years ago stuck in my mind and led me to my current approach in software development that tries to effectively mirror solid engineering principles.
Defining Comments
In the field of software engineering, code comments are often regarded as a bit of an unloved stepchild. No developer regards them in the same way, few appreciate them, most neglect them and some outright banish them from their lives. The most extreme response here is probably that of the Clean Code movement, who together with the Self-Documenting Code crowd insist that inline comments in particular are unnecessary, an eyesore and that beautiful, well-written code documents itself.
Then there are those who use comments as a (temporary) crutch, as in what is referred to as ‘comment programming‘. This puts comments in the place where code is supposed to go, for either later replacement or to elucidate a specific aspect. None of this uses comments consistently to provide a parallel flow with the code that explains the what, why and how of said code.
Why this matters is that despite claims to the contrary, reading and understanding code is hard. Grasping architectural decisions and intuitively separating them from quick hacks is hard even if you’re reading back your own code after a few development cycles. This is also basically why writing documentation based on just code with at most spotty inline commentary is a nightmare at best.
After working with a variety of (commercial) codebases over the years that were practically dripping technical debt and regrets – as well as writing comprehensive documentation for some of them – I have become convinced that comments are ultimately the Alpha and Omega of a healthy codebase and up to date documentation.
Software Engineering

Although most people see the finished product of engineering and believe that that’s all there’s to it, the truth is that before that bridge, high-rise building or even some fancy electronic widget sees the light of day, most of the work has already happened. Building it is then theoretically as easy as following the provided instructions.
An essential point here is the assumption that said instructions are half-way correct and you don’t end up building your very own Millennium Tower.
Thus the process of engineering begins with the list of requirements. These have to be chiseled into the hardest of stone, as any change here will have potentially massive repercussions. From these requirements you can then begin to work on a design document that details the overall design of the product, from which the desired architecture follows.
While the specific details will differ for each specific field of engineering, it is this condensing from an abstract idea into increasingly more concrete steps that enables for all angles to be considered before committing to a specific decision that can be hard to revert or change later. In the case of the aforementioned Millennium Tower project, those in charge omitted steps like peer review, where an external set of eyes is asked to give their two cents, because this would have ‘taken too long’.
From Design To Code
Even if in general software is easier to change than e.g. the blueprints for a civil engineering project, you still want to avoid having to go back repeatedly to change or modify parts of a codebase. To this end you do not want to write code until you are very confident that said code is proper and correct.
Fortunately, with the detailed design document and architectural planning already in the bag you can then start the feedback loop of laying out the foundations, with any obvious issues discovered during this phase being used to improve the design and architectural documentation.
Laying out these foundations involves creating the codebase’s basic layout, including details like creating header and source files with appropriate naming. Next, within these files the architectural structure is laid out, such as creating the skeletons of types, classes, functions and methods that establish the APIs.
For each file a heading comment block is added that briefly summarizes the file’s purpose, the features contained therein, as well as a truncated change list with date and name, for accountability.
At this point we are ready to pour in the details of each compile unit’s implementation, starting by taking the design and related documents and turning the details contained therein into comments that describe the overarching design decisions, special considerations, the flow within a section and any interactions with other modules.
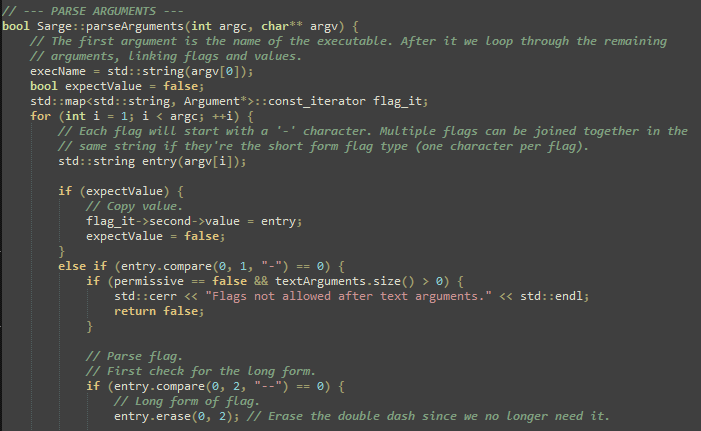
An example of this can be found in my Sarge command line argument parsing library, which both in its C++ and Ada form would be a very hairy mess of logic to keep track of without having the continuous flow of thought describing what is happening, why it’s happening and relevant implications.
Although it may seem simple and obvious, doing this consistently and in a way that doesn’t leave future you staring dumbfounded at a section of code, or chasing red herrings during a debugging session due to a flawed assumption is somewhat of an art. Here it’s crucial that whenever you find yourself in such a state that the relevant inline comments are updated or new ones added as necessary to prevent future confusion.
It shouldn’t even have to be said that keeping these comments – and related documentation – updated whenever code changes are made is absolutely paramount as well. While it’s ‘boring’ work, you don’t do it for your present self, but your future self and/or fellow developers who’ll otherwise use extremely colorful language related to your person.
Documentation And Tests
Writing the documentation with CDD starts from the first list of requirements, with the design document being the next major part, both providing the higher-level overview of the project before diving into the nitty-gritty of the architecture and implementation.
What the best approach here is largely depends on the project and who might be interested in documentation and to which extent. For a typical commercial project where there never is budget for ‘writing documentation’, simply having the design document and the detailed inline comments in the source might be what one has to settle for.
Here it might also be possible to use said inline comments to generate e.g. API listings from with tools such as Doxygen. My own experiences with such tools are mixed, but in a CDD context such auto-generated documentation could be significantly more useful, not to mention accurate.
Finally, any tests required to test specific functionality would be defined along with the code’s architecture, letting it define the testing scope rather than vice versa. With APIs for modules already settled early on, writing unit- and integration tests tends to be a lot easier and without the nagging and nebulous goal of that mystical ‘100% test coverage’.
Mitigating Circumstances
Of course, not every software project is the same, especially for hobbyist projects where you’re often the sole maintainer. It is here your prerogative to take all the shortcuts you want, as long as it is in the knowledge that you’ll only have yourself to blame.
This is why some of my projects are definitely a bit more loose in their adherence to CDD, while others are a complete stickler. for example, when I created my NyanSD network service discovery protocol, I started by writing out a complete requirements and design document, including the protocol itself. By following the top-down CDD approach here I was able to design and implement the entire protocol in the course of about two days, and have it mostly work first try.
Ultimately, CDD in my eyes is the correct approach to software engineering, as it saves a lot of time while being the only approach that actually follows basic engineering principles. You can change the field, but ultimately both physics and underlying hardware remain just as unimpressed by your personal views on how things ought to work.














Pfft. Good luck with all that. The “business reality” of most modern software development is that we’re all just Jira slaves tortured by crackhead timelines and demonic “metrics”. “Grab a ticket. Are you done yet? Are you done yet? WHY AREN’T YOU DONE YET?!” And AI just makes it worse.
This is fact. But if you put on a blue collar its is that installed yet, did you tighten that nut yet, why are your installations down? In a data driven world we’ve all become machines. AI and our soon to be AI powered robot overlords are certainly not going to make things better for us. Even if they do fold my laundry.
What you and the OP are both hitting that isn’t explicitly mentioned is the continuous drive to more profit at the expense of humanity. A humanistic approach to building something is purposeful, careful, & considered. A profit driven approach to building something is to build it the fastest and cheapest way possible in order to get as much profit as possible. Humanistic approaches create artful and delightful experiences, and people enjoy making them, I’ve never met someone actually building anything that enjoyed it when “the screws were tightened” on their projects.
MBA grad: “Careful, long-term planning and execution? Nah, we grab quick cash and dash!”
To respectfully disagree – and I’m a hobbyist indie game dev, mind you – I like knowing that my programming is working and do get quite excited when I stomp a particular bug. Of course, I’m also autistic so maybe it’s just a hyperfocus thing. But I agree wholeheartedly with this.
And if you want evidence that crappy profit-driven development leads to disaster down the line (in game dev at least), might I point one towards games as a service? Oh boy. That scene is a dumpster fire now.
I’ve been there when I was younger. Took it way too seriously and ended up badly burned out.
The real fun begins when you are older, more experienced, more cynical, able to mess with both the project itself and nаzіs disguised as “cum masters” or some other kind of “project managers”. Despite various coding paradigms, most of the corporate code is simply a one big spaghetti so it’s not that hard to keep coming up with creative ways to introduce subtle flaws (or better yet, make others introduce them). Despite day to day work looking just fine in Jira and meetings, over time the whole thing derails and usually it’s the PM’s head on the chopping block for mismanaging the project… sometimes some overzealous newbie coder too, but those just get assigned to another trainwreck-in-the-making. I’ve been doing this for the last 6 years and what a ride it’s been. Software work was never so fun.
Exactly. Cynicism is the last asylum of the common sense.
A former boss of mine that I greatly admired would call this a “low-integrity approach”. I always expected better from myself even it if severely burned me out in the process.
And I’m guessing you meant “scrum masters” – what they do on their own time I probably don’t want to know…
Welcome, to the “scrum” zone. :3
“Scrum” is originally a rugby term, where 8 players form up and do battle with a similar 8 players. They are all big, and what goes on in a scrum, one doesn’t want to know about. With TV, the bad behaviour isnt so obvious but still there.
With all that, I could never understand the use of the term in software project development. The original scrum was almost absolute mayhem, hardly what one is hoping for in software development.
Those yelling at you “ARE YOU DONE YET? WHY NOT?” should be paid the minimum wage janitor wages, because that’s what they are doing – keeping their task roster neat and tidy. If they cannot step in and pick up Some Slack where you cannot (or not allowed to – more on that later), then they are the hindrance, not the help, you have to drop whatever you are doing in order to waste your time explaining things at their basic level of understanding.
I’ve also worked with outright toxic so-called “managers” who were impossible to deal with – instead of helping me by picking up and doing some tasks that THEY supposed to be doing (for example, task coordination, relevant information sharing, etc) they yell at me for doing THEIR JOB and forbid me from ever, EVER doing such things in the future. It was not about helping with the task, it was about asserting their control over me, one task at a time, an making sure they are involved in everything I do, at all times. Obviously, once they are included in all discussions, unable to follow, they burn out and gradually/quietly fall to the wayside, unable to offer much of value, except mysterious “frameworks” or “indices/matrices” or whatever it is the level of naive/basic knowledge that they planned to “empower” (really, saddle) me with.
AI-ass-isted managers are not any better, btw, IMHO, they were dumb to start with, now they are dumb managers with AI. They gladly regurgitate what other managers say or do without thinking much, and other managers on average are not any smarter either. They think they will be The Ones left pushing the AI buttons, no, in all fairness they will be The Other Ones, told by the AI which buttons to push. I already see it happening, btw, managers babysitting AI that supposed to be “empowering” them.
Literate programming is a great way to do this. You write a document describing the code and what it does, interspersed with (named) chunks of actual code. A chunk of code can contain references to other chunks, by name. At build time, a program extracts all the code chunks and knits them together.
Uh yeah that is how programming and compilers work. Functions have names and are called, they are also chunks of code…and yes a compiler knits them all together….
No, “Literate Programming” is not just compiling code. It’s arguably over-specified and over-engineered, but you build a document aimed primarily at humans with embedded code blocks, and a special tool extracts the code before sending it to the compiler and other build tools.
It’s a system specified by Donald Knuth, and like all his work, it’s elegant, beautiful, and much easier to use in academia than in corporate jobs.
This sounds a bit like the top-down, bottom-up strategy I employ for larger projects where I basically write an outline of the code first in comments and placeholder functions that may (or may not) hold code to mocking the functionality.
This means that I have a good outline of the code to begin with and can use that to mentally check that I have understood the problem and to consider long term development opportunities (i.e. architecture) so I know where I want to be going and not take the steamer to “Argentina” when I really want to go to “Scotland”.
With this framework in place I can tackle each function on its own and test it thoroughly before committing it.
I rather do Documentation-driven dev; first document, then code, then test. This also helps against scope creep.
For many decades I have written code using the comments first method.
Do like to see skeletons start walking early on.
Curiously they might when I first think, helped by writing requirements and ideas down (in the source), and order and refine them.
I use this approach per subject that has no immediate glaringly obvious solution (to me).
And I may use a tiny testframework to drive the so developing API, but it may as well be
main().Then there’s integration…
Not too different from CDD perhaps :)
Yeah, the code skeleton helps you keep that high-level overview rather than getting lost in the weeds with countless micro-optimisations with the code implementation. Committing to the ‘final’ code is something you do when there are no obvious high-level objections :)
Code should be written clearly enough (function names and variable names) that what it does is clear. Comments should explain the why.
Self-documenting code used to be the least worst option, the only downside was it took more effort to follow the code. But coding LLMs have completely removed that problem. If you don’t know what some code is for, simple small LLM running locally can explain it. Self-documenting is a no brainier now.
Not sure if I understood properly, but looking at the sarge screenshot made me facepalm a couple of times. I am a big fan of self documenting code, but when you document what you do, instead of why?! // copy value, yes I can see that. But why? Or argv[0] is the executable name, OK granted, not everybody knows, or not in a whim, but where to draw the line? If argv[0] is that big of a concern, I would have made 0 a readable and documented define (surprised it is not yet so, worth a MR ¶:).
One good thing about CDD is that it Also helps AI a lot.
But I think what you are really discovering here is ‘spec driven development’, something made cool with AI. The really nice thing about this is it forces you to really think things true before hand. What do you really want to build? What are the true requirements? What is the spec?
And that, is what makes a real senior developer/architect.
Time for the classic tree swing cartoon!
https://www.businessballs.com/_assets/local/pix/businessballs/treeswing/tree_swing_70s.jpeg
I’m a big fan of the following workflow:
1) Thoroughly read through & think over requirements and architectural docs.
2) Write the code while leaving minimal comments.
3) Let it sit a week or two (long enough that I’ll have to really read the code, but not long enough for the intent to get stale).
4) Make a second pass through the code writing detailed comments (tying each chunk of the code to its conceptual role and, where appropriate, calling out things like preconditions, post conditions, and loop invariants).
Not only does waiting until the intent is fresh but the implementation is not put me as close as I can get to my future self / another developer but it has the bonus feature of letting me catch most of my bugs in one go. I’ve passed on this approach to folks I’ve mentored and occasionally will hear back years later whem it has saved them a major hassle and that they’re passing it on too…
How does this differ from the Waterfall model of software development?
Well, since the waterfall model does not exist and this does, here you are.
Now, since your don’t see the difference between this and the granddaddy of counter-examples, I think you don’t even know waterfall.
Specifications are life before, during and after development.
What you are describing sounds a lot like a process I’ve seen for an ISO26262 certified process.
Trying to apply engineering principles from physical disciplines to the information based one that is software engineering will instantly be met with comments about the waterfall process.
But considering the that such processes have been employed successfully to create mission critical programs, it is a valid process.
The comments are where things start to get interesting because this is where I see some peers working in the LLM driven code development space. They are trying to make the bulk of the engineering the requirements, arch, and design parts with the LLMs implementing the code.
Oh, what a relief! I thought by “Comment Driven” you meant driven by customers’ comments.
PS: Interesting to see on Wikipedia how many industry awards the Millenium Tower received!
Amusingly some of those awards are actually for the hot patching of the flawed design, not for the original building :)
That Sarge code snippet is terrible. Just shows how C++ has made things more complicated.
Copy the arg into a c++ string, check the start with some mid_string equivalent test for — , delete — from string via some array manipulation, to continue into a word list I assume.
This is some wannabe low level coding. Man….
Either go the C way and just move the pointer along or write a class that you can pass some clean looking, generic, parsing instruction.
Thank you for your comment.
The main reason why in Sarge I use std::string for parsing is because it’s safer and the extra performance you can get with a more low-level approach is rather irrelevant for this purpose.
In my NymphRPC project, for example, performance is paramount and is where I have mostly banished those high-level C++ concepts for that reason and use all the raw pointers and memcpy. You have to pick your battles wisely.
100% improvement of 1% of runtime is 1% real improvement. Beware premature optimization.
Having said that: commenting a two-line code block isn’t usually necessary unless the function of that block isn’t immediately obvious. I’m a huge believer in class/function/library comments, but given decent code style line comments should only be needed when doing something that can’t be read off the line easily, and a block large enough to need commenting may want to be factored out as a function with meaningful name. Trust the optimizer, Luke… Or at least trust-but-verify.
LLMs are best used with spec driven development. PRDs and requirements aren’t comments but are pretty darn close.
“Ultimately, CDD in my eyes is the correct approach to software engineering, as it saves a lot of time while being the only approach that actually follows basic engineering principles.”
False premise.
The comments are unverifiable, and you’ve handwaved actual engineering strategies that are verifiable.
The comments are totally verifiable. Either the code matches the comments, or it doesn’t. The comments are the most important part as they tell you what is supposed to be happening. If you are presented with just code you have to figure it out (or guess) every time.
No, the comments aren’t verifiable except through a fully human fallible interpretation.
Test driven development, when done properly, is actually verifiable. While it is sometimes short circuited, the people who short circuit that would inevitably shortcut this too. But, test driven development can actually be structured to indicate how many and which lines of code were tested. It falls well within engineering principles this complete fails to address.
Comments are just comments, they are at best an intent.
Without verification there is no engineering principals being applied.
When you receive steel beams for a construction project you also receive documentation showing how the batch of steal was tested for conformance. You receive a documentation showing the test results, and you receive a signature of an engineer attesting to the accuracy of the paperwork. That engineer is legally responsible for the accuracy of the test, and the declaration of conformance to the specification as declared.
It’s not a hand written comment saying “this item confirms with xyz”, it’s a document saying that the steel was tested to meet the specifications as provided.
The engineering process isn’t the signature, it’s the entire workflow, combined with the signature.
If you were to take the steel and perform the same test and that product failed, that engineer can be legally held responsible for the failure of that product to meet the specifications.
I’ve worked with engineers, in several industries. Code comments aren’t engineering.
Maybe it should be called Theorem programming?
I am well out of the software now but one of my favourite practices was to ‘bury it in the subconscious”; by this I mean, if you have a new spec that you have to work on next week, have a good read of it this week and let the requirements float around in your head, in your subconscious. When next week becomes this week, you are somewhat familiar with the project and not starting from scratch.
Does this idea have any backing in psychology or neuro-science? I dont know but I consider it was useful to me.
Ripe / mature not bury, so “ripe it in the subconscious”
But the reality in many projects is that the spec will change, and allowing flexibility for that (whilst not over engineering) is wise.
Certainly true, though it’s another can of worms when doing the design and architecture steps. Of course you need to always take some level of expansion and flexibility into account, but this can also rapidly regress into scope & feature creep. And managers/customers rarely grasp or care how involved their change requests are anyway…
Comments are extremely important. Things that are unclear should be commented. ONLY things that are unclear should be commented. FUNCTIONS SHOULD BE CLEAR. So a comment at the top of the function, illustrating how it fits in, what its assumptions and side-effects are, is often extremely valuable. If there’s something surprising inside of it, like a side-effect into a counter-intuitive data structure, it should be commented. If you’re gonna look at an if (…) { do one thing } else { do the same thing but with a subtle interaction with the memory manager }, that should have an in-line comment, otherwise it looks like a distiction-without-a-difference. If you’ve got code where the order of steps has been logically reversed becuse of some subtle interaction, that needs an inline comment.
At some point, you’re gonna have to read the code of the function. Copious inline comments that duplicate the code itself are your worst enemy. They make it hard to read the code of the function. They take up vertical space that pushes the overall structure of the function off of your screen. They are often wrong and represent the fantasy in the mind of the programmer who wrote it, instead of the reality of the code that exists.
The Sarge example in this article is a worst-case of comment style. The boilerplate comment before the function is of literally zero value, it replicates the name of the function. One of the inline comments should have been the comment before the function, it says what the function does. The other ones should have been eliminated. Some of the inline comments are “justified” by the decision to use a state machine in expectValue instead of essentially a recursive descent parser (reading the value when it’s expected, instead of saving the fact that it’s expected as state). That poor structure decision complicates your code, and then you “make up for” the complication with comments. But the key to unraveling that complication when you read it is to have where expectValue is set be clearly related to where it is read, which is made harder by wasting all that vertical space within the function.
I recently improved a bunch of code simply by deleting the comments that said /* This part is tricky. */ I left in the parts that said what the trick was, but the fact that it’s tricky doesn’t help anyone, it just adds a level of mystification. Then i proceeded to make it not tricky anymore!
The code itself must be readable!
Data structures — of course — should be commented if there is anything remotely unclear about them. You should be able to look at a struct definition and imagine the code that uses it, so that when you see those functions you already have an idea what will be inside them, and the things that don’t match that idea should pop out at you, which is impossible if you’ve buried the surprises behind a wall of text.
People are gonna disagree with me, because they don’t really understand the language they’re using, and they aren’t working on complicated problem domains. They wind up commenting the little things that surprise them as a newbie and inevitably, people who do this fail to comment the big surprising things. Over-commenting the things that are clear is always paired with failing to comment things that are unclear. It’s a crutch to make up for the things you don’t understand. Comments should be read by people who don’t understand, but they should not be written by people who don’t understad.
But it doesn’t stop there at all! I keep copious journals in all my projects. Commit messages should be meaningful. Bug tracking is invaluable. If there’s waffling — a decision that is repeatedly reversed — an inline comment with the bug tracker id to look at the history of the waffle is invaluable. Do different customers genuinely have different needs or is this a case of repeatedly not understanding how it really works? I’m very verbose in these bug tracking, design, and commit documents, and even so i’m always wishing i was more verbose. Verbosity there can help your future self try to re-construct the dream that created the code in the first place, and doesn’t get in the way of reading the code.
The fundamental goal of a comment is to help you read code. You should never obscure the code itself. If the function is a bloated mess with multiple tasks within it and you need inline comments to “clarify” it, you’re only bloating the fuction further…you need to factor it instead.
Filthy casual (hobbyist) here, but I can only imagine what a nightmare it is working on code as part of a team without comments indicating what the various portions of code are supposed to be doing. Just returning to my own code after it’s been shelved for a while can be headache-inducing if my past self didn’t see fit to let future me know what I was trying to do 😭
I recommend you learn how to refactor code.
Then, take time when reading “headache-inducing” code to isolate those confusing chunks. Use the Extract Method refactoring process to move a small tangled bit into its own method, and give that method a descriptive, meaningful name. Also write unit tests for it, proving it does what you think; as a side benefit tests also provide examples to future maintainers how to use the functions. Repeat until the whole block of code explains what it does, and you have tests that prove it.
It’s only a little slower than writing comments and the resulting code is self-documented, which is a whole lot more valuable the next time it needs to be understood.
Of course this approach doesn’t always scale well down to bit manipulation logic buried inside device drivers or other code with super-high performance requirements. But for the majority of code you encounter readable, correctly performing code is far more important than fast code hiding subtle bugs.
Looks entirely sensible to me, although the first thing I always put in any file (usually as a banner) is what compiler variant, version and targets it’s intended to support (the actual build instructions can be assumed to be in a makefile or compiler-specific project file).
Then each file has a comment saying broadly what it contains, and each function etc. has a comment- ideally formatted so as to make sense to any IDE or document generator- describing purpose, parameters and return value; ideally each (public) type or variable would have something similar, but it’s not usually realistic to extend this to individual fields.
Have you seen the movie Memento? I use comments like clues for my future self to pick up where I left off. If you know have many datasheets these eyeballs have seen then you’ll understand why I walk around like a zombie sometimes and can’t remember what I had for breakfast let alone why I coded it that way last week.
I’ll use Doxygen to document the header file for public facing libraries but I will let it slide when I am the single maintainer of the project. The more exotic the technology is, the more verbose my comments will be, for example this SD card driver:
https://github.com/piconomix/px-fwlib/blob/master/devices/mem/inc/px_sd.h
https://github.com/piconomix/px-fwlib/blob/master/devices/mem/src/px_sd.c
Here’s the generated Doxygen page:
https://piconomix.com/px-fwlib/group___p_x___s_d.html
Sometimes I will even use a bit of ASCII art to visually document a situation:
https://github.com/piconomix/px-fwlib/blob/master/utils/src/px_ring_buf.c#L91-L103
I prefer to use ST’s low level drivers but the function names are not clear and obvious so I will use comments to say in plain language what it does, for example this function to initialize the clocks:
https://github.com/piconomix/px-fwlib/blob/master/boards/arm/stm32/st_nucleo64_l053/src/px_board.c#L54-L119
It’s an ever evolving art for me. It’s tricky to get the balance just right so that it’s clear and concise and not cryptic or overly verbose.
TDD is fine and dandy when you are doing something ‘algorithmic’ that is the very heart of the code – like some network protocol or complicated maths for a block chain or some such. But for the infrastructure, the UI, the flow of data, some documentation on the design & how it’s (meant) to work is everything.
I’ve tried to contribute to some larger open source projects, but the lack of architectural documentation & any form of future plans have quickly descending in to trying to find a black cat in a coal cellar. And in at least two instances, one a major contributor to radio, the academic C++ techniques make moving over the code base to trace inheritance so you can figure out what is actually being called laborious & tiring.
So CDD is good – for the why, the context & the detailed/nuanced stuff – and keeping files such that they don’t need more than a handful of screenfuls to navigate. But the first and most important docs are the CDD on the goal, objectives, architecture, code map (how things are divided up & where they are) and, as required, how it all hangs together.
Unpopular opinion :
Use a “better” language like c# that is more expressive with fewer parasitic character ( : : ->)
IDE should split comments and code and display them in two separate (synchronized) window (and probably a third window for logging and input/output).
Your brain isn’t wired to switch from a language to another every 4 lines.